Die große Familie der Programmiersprachen hat sehr viele Mitglieder und blickt auf eine
Geschichte zurück, die nach aktueller Interpretation bis zu den Pianolas, den selbst spielenden
Klavieren, reicht, also bis ins 19. Jahrhundert. Relevant für die Sprachen zur Programmierung
von Computern ist die Geschichte seit den frühen 1950er-Jahren. Neue Sprachen entstehen
häufig, aber nur wenige haben die Eigenschaften und das Glück, sich durchzusetzen. Die
Fähigkeit, am Markt der Programmiersprachen zu bestehen, hängt von vielen Faktoren
ab:
- Marktmacht des Herstellers
- Ähnlichkeit zu anderen wichtigen Programmiersprachen
- Starker Fokus auf ein Thema
- Zeit und Ort
- Lizenz
- Charismatische Erfinder und Lenker
- Bibliotheken-Landschaft
Diese Aufzählung erhebt weder den Anspruch auf Vollständigkeit noch auf korrekte
Reihenfolge bezüglich der Wichtigkeit der einzelnen Aspekte. In einigen Bereichen kann
Clojure aber punkten:
- Rich Hickey ist ein charismatischer Erfinder und kann seine Meinungen
und Entscheidungen sehr überzeugend vertreten, was zahlreiche aufgezeichnete
Vorträge im Internet belegen.
- Clojure hat einen sehr starken Fokus auf Concurrent Programming, und es könnte
die richtige Zeit sein, diesen Schwerpunkt gerade jetzt, im Jahre 2010, zu legen.
- Das Problem der Bibliotheken wird durch das Erbe von Java gelöst.
- Rich Hickey hat Clojure unter der Eclipse Public License veröffentlicht, die die
Freiheit der Sprache garantiert und eine kommerzielle Verwendung erlaubt.
Skeptiker betrachten vor allem die fehlende Ähnlichkeit zu anderen populären
Programmiersprachen als einen Mangel von Clojure. Lisp-Programmierer sehen das
naturgemäß anders und begrüßen die alternative Verwendung der Errungenschaften der
Java-Welt, aber es ist nicht zu leugnen, dass die Syntax zunächst abschreckend und ungewohnt
ist. Andererseits erlebt Lisp auch ohne die Revolution durch Clojure derzeit so etwas wie einen
zweiten Frühling, was sich an neuen Bucherscheinungen, wachsender Community und neuen
Projekten ablesen lässt. Wer sich traut und sich auf diese Syntax einlässt, wird von Clojure
reich belohnt.
In diesem Kapitel betrachten wir die Programmiersprache Clojure und beschreiben
die wichtigen Merkmale. Dabei hilft ein Crash-Kurs in Lisp, die ersten Hürden zu
nehmen.
Rich Hickey hat in Clojure verschiedene Eigenschaften zusammengetragen, die in ihrer
Kombination zu einem einzigartigen Resultat führen. Die meisten Features sind für sich
genommen nichts Neues, Lisp gibt es schon lange, die Java Virtual Machine ist weit verbreitet
und auch weitergehende Themen wie Software Transactional Memory sind zumindest aus der
Literatur bekannt. Eine Programmiersprache aber, die diese und weitere Funktionen
zusammenführt, existierte vor Clojure noch nicht. In diesem Abschnitt gehen wir auf die
wichtigsten Eigenheiten von Clojure ein, von denen einige bereits in der Einleitung in
Abschnitt 1.1 genannt wurden.
Zum Thema funktionale Programmiersprachen existiert die abwertende Bemerkung, dass in
ihnen geschriebene Programme allenfalls zum Aufheizen des Prozessors dienen können. Für
einen Anwender sichtbare Effekte wie Ausgaben irgendeiner Form, Veränderungen auf dem
Bildschirm, Datei- oder Datenbankzugriffe sind in einem rein funktionalen Programmiermodell
nur mit (teilweise recht komplexen) Tricks zu erreichen. Demgegenüber verspricht der
funktionale Ansatz auf anderen Gebieten Vorteile, was zur Entwicklung einer Vielzahl von
funktionalen Programmiersprachen geführt hat. Bei allen Unterschieden weisen die meisten
dieser Sprachen einige zentrale Merkmale auf, auf deren Umsetzung in Clojure wir im
Folgenden eingehen:
- Funktionen ohne Nebeneffekte sind eher die Regel als die Ausnahme,
- Funktionen sind ein Datentyp wie auch Zahlen oder Strings,
- Funktionen, die ihrerseits Funktionen als Argumente akzeptieren, werden häufig
verwendet,
- rekursive Lösungen sind idiomatische Lösungen,
- ein starkes Typsystem für Variablen, Parameter und Rückgabewerte kontrolliert
das Vorhandensein von Nebeneffekten und
- die Auswertung von Ausdrücken findet erst bei Bedarf statt, also erst, wenn das
Ergebnis benötigt wird.
Clojure erfüllt nicht alle genannten Eigenschaften und ist somit keine
rein funktionale Sprache im Gegensatz etwa zu Haskell. Vor allem ist Clojure nicht
statisch typisiert, was heute als wesentlicher Bestandteil von funktionalen Sprachen
angesehen wird. Zudem erlaubt Clojure Funktionen mit Nebeneffekten, wohingegen
nach heutiger Lesart in einer rein funktionalen Sprache Nebeneffekte im Typsystem
deklarativ untergebracht werden müssen. Nebeneffektfreie Funktionen bekommen einen
oder mehrere Parameter und ermitteln daraus einen Rückgabewert. Dabei spielen
Informationen jenseits der übermittelten Parameter keine Rolle, und es werden auch keine
Informationen verändert, außer dass ein Wert an die aufrufende Funktion zurückgegeben
wird. Solche Funktionen werden Reine Funktionen„reine Funktionen“ (engl. „pure
functions“) genannt. Sie haben den Nachteil, dass sie aus Sicht des Anwenders keinerlei
Wirkung haben. Ein wichtiger Vorteil aber ist, dass sie sicher auf verschiedene Threads
verteilt werden können, eben weil sie keine Nebeneffekte haben. Diese Funktionen
eignen sich nicht für die sichtbaren Bestandteile eines Programms, die mit ihrer
Umwelt oder dem Anwender interagieren, gleichwohl können diese Funktionen im
Hintergrund, wo die datenintensive Arbeit des Programms erledigt wird, eingesetzt
werden.
Die dadurch verbesserte Parallelisierbarkeit lässt die Familie der funktionalen
Programmiersprachen eine leichte Renaissance erleben, die sich im Blätterwald der
Computermagazine und in der Entwicklung von Sprachen wie Scala, F# und eben Clojure
widerspiegelt. Im November 2009 war funktionale Programmierung die Überschrift
eines Themenschwerpunkts auf der Webseite des deutschen Linux-Magazins, die
Dezemberausgabe der iX trug den Titel „Multicore-CPUs nutzen durch funktionales
Programmieren“ [48], und Howard L. Ship entwickelt im Sommer 2010 das von ihm
betreute Projekt Apache Tapestry in eine funktionale Richtung weiter [62]. Wer
heutzutage in einer Firma, die Software entwickelt, eine Bestandsaufnahme der
aktuellen Entwicklungsthemen macht, wird vermutlich eine erstaunliche Fülle an
Nebenläufigkeit, Future-Objekten und Multicore-Skalierungsproblemen finden. Selbst
eingefleischte Anhänger der objektorientierten Programmierung sehen sich – teils mit
zunehmendem Interesse – mehr und mehr mit Bibliotheken konfrontiert, die ein funktionales
Modell propagieren oder wichtige Elemente aus der funktionalen Programmierung
anbieten, selbst wenn die Programmiersprache an sich vielleicht nicht (rein) funktional
ist [53][17][8]. Auch Bücher über funktionale Programmierung in nichtfunktionalen
Sprachen wurden geschrieben, etwa über Perl [12]. Das theoretisch gut untersuchte
Feld der funktionalen Programmierung wird – so ist zumindest unser Eindruck –
Mainstream.
Die Funktionen in funktionalen Programmiersprachen haben im
Vergleich zu ihren Pendants in vielen nichtfunktionalen Sprachen den Vorteil, dass sie
gewissermaßen Bürger erster Klasse im Herzogtum der Datentypen sind. Sie sind ein ebenso
grundlegender Datentyp wie eine ganze Zahl, ein String oder ein Vektor. Funktionen können in
Variablen gespeichert und als Parameter übergeben oder als Resultat zurückgegeben werden.
Im Zusammenspiel mit dem lexikalischen Geltungsbereich (engl. „lexical scope“)
ergibt das die interessante Möglichkeit zur Anwendung von „Closures“. Der Name
„Clojure“ lehnt sich natürlich an „Closure“ an und vermittelt somit den funktionalen
Charakter von Clojure ebenso wie die Verbindung zur Java-Welt. Closures werden in
Abschnitt 2.17.1 beschrieben.Higher Order FunctionsEine direkte Folge von Funktionen als
„First-Class-Objekten“ ist, dass andere Funktionen ihrerseits Funktionen als Argumente
akzeptieren. Die Verwendung dieser Klasse von Funktionen, Funktionen höherer Ordnung
(engl. „higher order functions“), ist typisch für Clojure und wird in Abschnitt 2.17.2
beschrieben.
Clojures Datenstrukturen sind unveränderlich. Unveränderlichkeit von
Daten kennen auch Java-Programmierer: bei Strings. String-Objekte werden einmal
angelegt und mit einem Inhalt versehen, danach sind sie nicht mehr zu verändern.
Unveränderliche Daten erleichtern den Zugriff aus verschiedenen Threads, da keine
Maßnahmen für die Synchronisation von Änderungen über Thread-Grenzen hinweg ergriffen
werden müssen. Diesen Vorteil erkauft sich Clojure mit erhöhtem Aufwand, um
Manipulationen abzubilden. So wäre für das Hinzufügen eines Elements zu einer Liste
eigentlich eine komplette Kopie der ursprünglichen Liste notwendig. Wenn ein Datentyp
sicherstellt, dass sich die enthaltenen Dateninhalte nie mehr ändern werden, kann
mit dieser Zusicherung andererseits effizient agiert werden: Die Unveränderlichkeit
erlaubt eine deutlich effizientere Implementation, die beim Kopieren und Ändern einer
Datenstruktur die unveränderlichen Inhalte in beiden Versionen verwendet. Clojures
Vorgehen in diesem Falle beschreibt der Hintergrundabschnitt 3.2.2 über persistente
Datenstrukturen.
Aus der Konstanz der Daten ergibt sich unweigerlich, dass Schleifenkonstrukte, die
bei jedem Durchlauf eine oder mehrere Zustandsvariablen ändern, nicht möglich sind. In der
funktionalen Programmierung werden daher Algorithmen rekursiv formuliert. Dieses
Vorgehen entspricht ebenso wie die nebeneffektfreien Funktionen dem Vorgehen in der
Mathematik. Rekursion, also wenn eine Funktion sich selbst wieder aufruft, bis ein Aufruf
schließlich ein Ergebnis liefern kann, welches dann durch die rekursiven Aufrufe wieder
„nach oben“ durchgereicht wird, verbraucht aber viele Ebenen des Stacks, der für
Funktionsaufrufe zur Verfügung steht. Dieser Unterschied zur möglicherweise unendlichen
Rekursion in der Mathematik lässt diese zunächst für Problemlösungen ungeeignet
erscheinen. In den meisten Fällen reicht jedoch ein Spezialfall der rekursiven Funktionen
für einen eleganten Algorithmus: die EndrekursionTail Recursion. Damit wird ein
Konstrukt bezeichnet, bei dem erstens die Funktion immer nur sich selbst (und nicht
andere Funktionen, die wiederum die erste Funktion aufrufen usw.) aufruft („lineare
Rekursion“ im Gegensatz zur „wechselseitigen Rekursion“), und das auch nur an den
Stellen innerhalb ihres Funktionsrumpfes, an denen eine Wertrückgabe erfolgen
würde. Solche Formen lassen sich unmittelbar durch eine Schleifenform ersetzen, die
den Stack nicht belastet. Die Java Virtual Machine beherrscht diese „tail recursion
optimization“ nicht, so dass Clojure hier einen kleinen Kunstgriff bemüht, um dieses
Element funktionaler Programmierung zu erlauben, der in Abschnitt 2.14 vertieft
wird.
Clojure ist ein Lisp-Dialekt. Rich Hickey hat diese nicht unumstrittene Entscheidung getroffen.
Der Wunsch nach einem Lisp mit Eigenschaften, die die vorhandenen nicht hatten, war
sogar einer der treibenden Gründe für die Entwicklung von Clojure, hatte sich Rich
Hickey doch zuvor zweimal an einer Bridge-Lösung zwischen Common Lisp und Java
versucht.
Eine Grundlage von Lisp ist, dass der Quelltext in einer spracheigenen
Datenstruktur, einer verschachtelten Liste, dargestellt ist. Somit liegt Quelltext in einer Form
vor, die mit den üblichen Mitteln der Sprache bearbeitet werden kann. Anweisungen sind
gleichzeitig leicht zu verarbeitende Daten. Diese „Code-as-Data-Philosophie“ erklärt
einerseits die Syntax und erlaubt andererseits ein Makrosystem, das mit der Sprache
harmoniert.
Es ist keine eigene Sprache wie beim Präprozessor von C, es sind keine syntaktischen
Verrenkungen wie bei Javas Annotations, es ist ein sauberes und leicht zu verstehendes
Konzept, bei dem vor der Kompilation Quelltext mit allen Mitteln der Sprache
erzeugt werden kann. Keine andere Programmiersprache verfügt über ein solches
Makrosystem.
Hinzu kommt, dass ein Lisp-Kern sehr klein ist. In der Regel, und auch bei Clojure, muss
nur ein kleiner Teil des Sprachumfanges aufwendig implementiert werden und viele weitere
Elemente der Programmiersprache lassen sich dann in der Sprache selbst verfassen, vor allem
durch die Verwendung von Makros.
Lisp ist für Neueinsteiger ein Abenteuer, aber eines, bei dem viele
unerwartete Schätze gehoben werden können, eines, das sich lohnen kann. Oder, wie es Eric
S. Raymond ausdrückt: LISP is worth learning for a different reason – the profound
enlightenment experience you will have when you finally get it. That experience will make you
a better programmer for the rest of your days, […][56]. Die Sprachfamilie existiert
beinahe so lange, wie es Programmiersprachen gibt, sie wird aktiv verwendet und
entwickelt. Viele Programmierer haben in ihrer Laufbahn einmal einen jener „Smug Lisp
Weenies“ getroffen, der bei der begeisterten Schilderung der tollen Features der
heißgeliebten Programmiersprache nur milde gelächelt hat. Vergleiche aber auch
Abschnitt 1.3.
Die Java Virtual Machine spielt die Rolle einer Plattform, auf der Programme laufen. Damit
entkoppelt sie einerseits die Programme vom Betriebsystem, das seinerseits die Programme
von der verwendeten Hardware entkoppelt, und ist andererseits in der Lage, weitere
Dienste anzubieten. Einer der wichtigsten Dienste der JVM, der in der Vergangenheit
viele C- und C++-Programmierer angezogen haben dürfte, ist die Verwaltung des
Speichers. Wie bereits in Abschnitt 1.1.2 geschildert, ist Java vor allem aus dem
unternehmerischen Bereich der Softwareentwicklung nicht mehr wegzudenken. Viele
firmeninterne Lösungen oder Produkte wurden in den letzten Jahren in Java entwickelt, und
im Laufe der Zeit hat sich die JVM als eine stabile und schnelle Plattform etablieren
können.
Clojure ist von Grund auf in Java entwickelt. Es erbt von der Java-Plattform Teile des
Typsystems, die Garbage Collection, die Threads und alle Bibliotheken. Für eine neue
Programmiersprache sind das unschätzbare Vorteile.
Sprache als Plattform oder Sprache und Plattform
Nach Meinung von Rich Hickey gehört den
Plattformen die Zukunft der Softwareentwicklung, und somit überrascht seine Entscheidung
für die Java Virtual Machine nicht. Es ist wichtig, sich zu überlegen, welche Features
Bestandteil einer Programmiersprache und welche Bestandteil der dazugehörigen Plattform
sind. Bislang hatte jede Programmiersprache ihre eigene Plattform, aber durch den Erfolg der
JVM (und auch .NET) ist es heute möglich, das in Frage zu stellen und als Folge davon
Features wie Bibliotheken, Speicherverwaltung und Thread-Verwaltung durch die
Plattform anbieten zu lassen. Sprachen, die heute auf eine Plattform portiert werden,
merkt man aber immer ihre Herkunft an. Aufgrund dessen haben Sprachen wie
Clojure oder auch Scala, die von vornherein für die JVM entwickelt wurden, einen
großen Vorteil. Sie integrieren sich deutlich besser, sie haben kompatible Typen, sie
duplizieren keine Bibliotheken mit potenziell leicht unterschiedlichem Verhalten und sie
brauchen keine Abhängigkeiten zu erfüllen, die sich beispielsweise bei einer in C
geschriebenen Programmiersprache ergeben, wenn diese Sprache bestimmte Bibliotheken
voraussetzt.
Zumindest einer der Autoren dieses Buchs vertritt die Meinung, dass Java
nicht effektiv von Menschen geschrieben werden kann. Die althergebrachte Art der
Entwicklung mit einem Texteditor und weiteren Werkzeugen wie Interpretern und Compilern
erscheint bei Java nicht mehr angebracht. Ohne die Unterstützung aufwendiger IDEs
wie Eclipse oder NetBeans ist es kaum mehr möglich, den Quelltext eines größeren
Java-Programms im Griff zu haben. In Bezug auf die zahlreich vorhandenen, frei
verfügbaren Lösungen fühlt sich Java-Programmierung gelegentlich eher an wie
die Konfiguration einer komplexen Software. Clojure zeigt aber, dass dies nicht so
sein muss, und erlaubt die Nutzung von Java-Bibliotheken mit deutlich geringerem
Aufwand.
Da Clojure in Java implementiert ist, ist es aber auch von Java aus betrachtet eine
Bibliothek. Clojures Datentypen, vor allem die interessanten persistenten Datenstrukturen,
lassen sich in eigenen Java-Programmen verwenden.
Clojure-Programme werden nicht geschrieben, kompiliert und dann gestartet. Clojure begleitet
den Entwickler bei seiner Arbeit und interagiert mit ihm. Das Gefühl beim Programmieren ist
ein ganz anderes, viel direkteres, die einzelnen Funktionen wirken viel vertrauter (und
vertrauenerweckender), so dass sich auch ein größeres Vertrauen in die Stabilität des
entwickelten Programms einstellt. Funktionen in einer Clojure-Sitzung können wieder
und wieder neu geschrieben werden, und Clojure kümmert sich im Hintergrund
darum, dass sie zu Java-Bytecode kompiliert werden. Von zentraler Bedeutung ist
dabei die REPL, eine Art Shell für die Clojure-Sitzung, die in Abschnitt 2.3 erklärt
wird.
Bei Verwendung einer IDE spricht diese im Hintergrund mit der laufenden Instanz der
JVM. In der Regel bieten die Entwicklungsumgebungen auch die Möglichkeit, sich mit einer
bereits laufenden Instanz zu verbinden und dort am offenen Herzen zu operieren. Eine solche
Verbindung kann beliebig oft geschlossen und neu aufgebaut werden, zur Wartung von
produktiven Systemen kann sie sogar durch eine SSH-Verbindung getunnelt werden. Vor allem
die Entwickler von Serverprogrammen profitieren davon, denn die Server können im laufenden
Betrieb aktualisiert werden, sofern die Änderungen nur kleinere Teile betreffen. Auch in der
Phase der Entwicklung ist es durchaus üblich, eine Instanz über Wochen laufen zu
lassen.
Concurrency ist ein zentrales Thema von Clojure. Die einfache Entwicklung von Programmen,
die sich konfliktfrei auf verschiedene Threads verteilen, ohne dass es Gerangel um geteilte
Ressourcen oder gar Programmstillstände durch fehlerhaftes Locking gäbe, ist erklärtes Ziel
der Sprache. John Ousterhout ist im Jahre 1995 zu dem Schluss gekommen, dass es nur den
besten Programmierern vorbehalten ist, funktionierende Multithreaded-Programme zu
schreiben [52], und seine Folgerung daraus ist, dass auf Multithreading in der Regel
verzichtet werden sollte. Mit seinen Besonderheiten, die auf eine bislang einzigartige
Weise zusammenwirken, macht Clojure Multithreading für viele Programmierer
verfügbar.
Diesem Fokus, der Erklärung der einzelnen Bestandteile und deren Zusammenspiel, widmet
dieses Buch das eigene Kapitel 3.
Die einleitende Manpage perlsyn.1 erklärt auf über 800 Zeilen die Syntax von Perl,
und perlop.1 erklärt auf über 2300 Zeilen die Operatoren von Perl, von denen die
Präzedenztabelle alleine mehr als 50 auflistet. Perl ist sicherlich ein extremes Beispiel, aber
auch im Vergleich zu anderen Programmiersprachen erscheinen die syntaktischen
Konstrukte von Lisp-artigen Programmiersprachen, die Clojure erbt, verblüffend
einfach. Einen großen Teil des verfügbaren Quelltexts wird man mit einigen wenigen
Grundregeln bereits lesen können. Im Folgenden beschreiben wir einen solchen Satz
von Grundregeln, der weitestgehend auch auf andere Lisp-Dialekte übertragbar
ist:
- Kommentare beginnen bei einem Semikolon und reichen bis zum Ende der Zeile.
- Zahlen, Strings und andere Datentypen können direkt in Form von Literalen
geschrieben werden.
- Die Namen für Variablen (im Sinne von Wertebehältern, nicht im Sinne von
Veränderlichen), Funktionen und vergleichbare Sprachelemente werden Symbole
genannt.
- Symbole und Literale lassen sich kombinieren, indem sie, durch Leerzeichen und
andere Whitespaces getrennt, in runde Klammern eingeschlossen werden. Die
Kombination trägt den Namen Ausdruck oder Form (engl.) und ist vom Typ Liste.
Den in der Literatur häufig verwendeten Begriff der S-Expression verwenden wir
nicht.
- Die Evaluation eines Literals gibt das Literal zurück.
- Die Evaluation einer Liste führt zum Ausführen einer Operation. Dann gibt das
erste Element der Liste den Namen der Funktion an, und alle weiteren Elemente
sind die Argumente für die Funktion, die, falls sie ihrerseits Listen sind, im
Regelfalle zunächst evaluiert werden.
- Steht vor der öffnenden
runden Klammer einer Liste ein einfaches Anführungszeichen, dann wird bei der
Evaluation der Funktionsaufruf unterdrückt, die Liste ist gequotet. Das Ergebnis
ist ein Listenliteral.
Der Klassiker „Hello World“ lässt sich damit bereits nachvollziehen.
- Die runden Klammern erzeugen eine Liste.
- Deren erstes Element („println“) gibt den Namen einer Funktion an.
Programmierer mit einem Java-Hintergrund fühlen sich (zu Recht) an
System.out.println erinnert.
- Diese Funktion wird ausgewertet; dem Namen nach zu urteilen, um eine Ausgabe
zu erzeugen.
- Das Argument für die Funktion ist – wenig überraschend – ein Stringliteral,
eingefasst in doppelte Anführungszeichen.
Für Clojure gelten zusätzlich zu den oben genannten noch weitere Regeln, die sich so in
anderen Lisp-Dialekten nicht finden:
- Zusätzlich zu den runden Klammern verwendet Clojure auch geschweifte und
eckige Klammern, die keine Listen, sondern andere Datentypen erzeugen.
- Komma ist Whitespace, wird also ignoriert, kann aber zur Strukturierung
verwendet werden.
| Tabelle 2.1: | Gegenüberstellung von Konstrukten in Java und Clojure |
|
|
| Java | Clojure |
|
|
System.out.println("Hello");
| |
|
|
public int add(int x, int y) {
return x + y;
}
| |
|
|
for( i=0; i < lst.size(); i++) {
System.out.println(
lst.get(i));
}
|
(doseq [item lst]
(println item))
|
|
|
if( x + 1 < z) {
return x + z;
} else {
return x - z;
}
|
(if (< (+ 1 x) z)
(+ x z)
(- x z))
|
|
|
MyObject obj = new MyObject();
obj.callMethod1(1, 2);
obj.callMethod2();
|
(doto (new MyObject)
(.callMethod1 1 2)
(.callMethod2))
|
|
|
obj.m1(arg).m2().m3(a1, a2);
|
(.. obj (m1 arg) m2 (m3 a1 a2))
|
Wer sich nun direkt Beispielen aus dem Internet oder auch aus der Contrib-Bibliothek [35]
zuwendet, wird feststellen, dass Clojure noch mehr syntaktische Konstrukte verwendet, die im
Verlaufe dieses Buches ihren Platz finden werden. Ein Gefühl für Clojure-Konstrukte im
Vergleich zu Java-Konstrukten gibt die Tabelle 2.2, die eine Gegenüberstellung häufiger
Anwendungen aus der Java-Welt und den jeweiligen Clojure-Code mit ähnlicher Wirkung
zeigt.
Weitere Beispiele werden diesen Satz von Regeln verdeutlichen.
(+ 23 5)
(+ 23 (+ 5 42))
(+ 5 (+ 18 5) (* 6 7))
Das ist einfache Arithmetik, wobei die Funktionen + und * zum Addieren und
Multiplizieren verwendet wurden. Die Schachtelung der Ausdrücke ist gerade im Falle der
Arithmetik leicht zu verstehen und bietet den Vorteil, dass keine Operatorpräzedenzen gelernt
werden müssen. „Punkt vor Strich“ ist noch recht offensichtlich; aber wie war das noch mal in
Perl, hat das negative Vorzeichen - Vorrang vor dem Exponentialoperator **? Und hat in
Java instanceof Vorrang vor <<? Das explizite Schachteln der Ausdrücke mit Hilfe der
Klammern macht klar, in welcher Reihenfolge die Berechnungen evaluiert werden sollen. Der
letzte Ausdruck liest sich von innen nach außen (und von links nach rechts) wie
folgt:
- Addiere 18 und 5; das Ergebnis ist 23.
- Multipliziere 6 und 7; das Ergebnis ist 42.
- Addiere 5 und die beiden Zwischenergebnisse. Hier ist zu beachten, dass die
Funktion + nicht auf zwei Argumente beschränkt ist. Egal wie viele Argumente
man ihr übergibt, sie wird alle addieren. Insofern hätte die innere Addition im
zweiten Beispiel ebenso gut entfallen können. Eine Addition von nur zwei Werten
hat einen Performancevorteil, da sie inline ausgeführt wird.
- Evaluation der ArgumenteEs ist zu beachten, dass die inneren Ausdrücke zuerst von
links nach rechts evaluiert werden und ihr Ergebnis den äußeren Ausdrücken
übergeben wird.
In Clojure, wie in anderen Lisps auch, werden auch alle Kontrollstrukturen
mit der gleichen Syntax dargestellt.
;; x sei eine Variable mit einem Integerwert
;; groesse-in-kb ebenfalls
(if (> x (* groesse-in-kb 1024))
(println "x ist zu groß: " x)
(println "x ist OK: " x))
Hier testet der if-Operator mit der Funktion >, ob der Wert einer gespeicherten Zahl (x)
größer ist als ein berechneter Wert. Je nach Ausgang dieses Tests wird die eine oder andere
Nachricht geschrieben. In Lisp ergeben sich also beim if die Bedingung, der Then-Teil sowie
der Else-Teil aus der Position:
(if test-ausdruck
then-ausdruck
else-ausdruck)
Da jeder dieser Ausdrücke beliebig geschachtelt sein kann, lassen sich auch komplexe
Bedingungen formulieren.
Der if-Befehl ist einer der seltenen Fälle, bei dem nicht alle Argumente evaluiert werden,
bevor sie weitergegeben werden, denn dann würde ja sowohl der Then- als auch der Else-Teil
ausgeführt werden, was offensichtlich nicht das ist, was der Programmierer erreichen will. Die
Hintergründe dazu erklärt Abschnitt 2.12.2.
Die Definition von Variablen erfolgt mit dem Befehl def. Da Funktionen in
Clojure auch Datentypen sind, ist die Definition von Funktionen nur ein Spezialfall von der
Definition von Variablen, der aber, weil sehr häufig verwendet, einen eigenen abkürzenden
Befehl erhält: defn.
(def standard-gruss "Hallo")
(defn gruesse-mich [mein-name]
(println standard-gruss mein-name))
Ein letztes obligatorisches Wort zu den runden Klammern, auch wenn es seit über
50 Jahren immer wieder gesagt wird: Runde Klammern sind ein Vorteil! Sie verschwinden
nach kurzer Zeit, meist nach wenigen Tagen, nahezu völlig aus dem bewussten Sehen. Nach
weiterer Eingewöhnung erscheinen sie irgendwann unverzichtbar, vor allem weil sie die
Navigation im Quelltext und die Manipulation desselben erleichtern. Sie sind ein Feature. In
jüngerer Vergangenheit wird die Syntax von Lisp häufiger durch Vergleichen mit XML
eingeführt, beispielsweise im Artikel „Nature of Lisp“ [1]. Dieses Verfahren kann durchaus
gerade für Java-Programmierer, die mit XML gut vertraut sind, geeignet sein, um die
Notation zu motivieren. Unser Argument hingegen ist VertrauenVertrauen. Vertrauen
darauf, dass es einen Grund hat, dass die runden Klammern nach mehr als 50 Jahren
Sprachgeschichte, die zu jeder Zeit von klugen Menschen mitbestimmt wurde, immer noch
vorhanden sind. Als amüsante Randbemerkung sei erlaubt, dass man in ähnlicher Weise die
signifikante Einrückung bei Python kritisieren könnte, und auch dessen Entwickler
beharren auf ihrer Designentscheidung (siehe from __future__ import braces).
Natürlich könnte in beiden Fällen der eigentliche Beweggrund Starrköpfigkeit sein.
Wir teilen in jedem Fall die Begeisterung für runde Klammern mit vielen anderen
Lisp-Programmierern.
Es ist für die Lesbarkeit von hoher Bedeutung, den Quelltext korrekt
einzurücken. Sofern das vorausgesetzt werden kann, lässt sich beispielsweise der Else-Teil
einer If-Bedingung sehr schnell erkennen, ohne die Klammern, die den Then-Teil
umschließen, ermitteln zu müssen. Korrekt eingerückter Code ist aber ohnehin in jeder
Programmiersprache eine gute Idee oder gar (wie im Falle von Python) Bestandteil der
Sprache selbst.
Mit diesem Grundwissen ausgestattet, sollte es möglich sein, auch bei anspruchsvollem
Code, beispielsweise von Clojure-Bibliotheken aus dem Internet, einen groben Eindruck zu
bekommen, wie ein Programm funktioniert. Durch ein wenig Gewöhnung stellt sich vermutlich
schnell der Zustand ein, dass Clojure-Code schnell überflogen werden und dessen Funktion
verstanden werden kann. Eine sehr originelle Einführung in Lisp bietet ein Comic von Conrad
Barski [6], wo auch das Makrosystem amüsant erklärt wird. Dieser Comic wurde mittlerweile
auch nach Clojure „portiert“.
Über die Jahrzehnte haben sich in der Lisp-Welt einige Konventionen
durchgesetzt. Von diesen hat Clojure manche übernommen, und es haben sich bereits weitere
hinzugesellt. Die folgende Liste zählt die wichtigsten Konventionen auf:
- Dateien mit Clojure-Quelltext bekommen die Dateiendung .clj.
- Als Worttrenner in Namen wird ein Minus verwendet, kein Unterstrich wie in C
üblich oder CamelCase wie in Java.
- Globale Variablen erhalten meist einen Namen mit je einem Sternchen am Anfang
und am Ende. Clojure definiert beispielsweise die Variable *clojure-version*.
- Ähnlich erhalten globale Konstanten jeweils ein Pluszeichen am Anfang und
am Ende ihres Namens (eher selten in Clojure, da die Werte ja ohnehin nicht
veränderlich sind).
- Grundlegende Funktionen mit Nebeneffekten sollten ein Ausrufezeichen am Ende
ihres Namens tragen.
- Prädikate, also Funktionen, die eine Prüfung auf bestimmte Eigenschaften
bereitstellen und wahr oder falsch zurückliefern, werden in der Regel mit einem
abschließenden Fragezeichen versehen.
- Mehrere schließende Klammern kommen alle auf eine Zeile. Das ist zu Beginn
ungewohnt, verschwendet aber keinen wertvollen vertikalen Platz auf dem
Bildschirm.
Entwickler kennen den gängigen Entwicklungszyklus als die immer wiederkehrende
Wiederholung der folgenden Schritte:
- Editieren
- Kompilieren (entfällt bei Interpreter-Sprachen)
- Programm laufen lassen
- Fehler analysieren
In Clojure, wie auch in anderen Sprachen der Lisp-Familie, ist das typischerweise anders.
Hier startet der Anwender die Laufzeitumgebung der Sprache einmal und interagiert dann
direkt mit dieser. Das lässt sich am ehesten mit der Arbeit in einer Shell wie der Bash
vergleichen. An einem Prompt werden Befehle eingegeben, die dann ausgeführt werden und
Dinge bewirken.
Etwas genauer betrachtet, nimmt der Reader, das „R“ in REPL, den
eingegebenen Befehl entgegen. Der Reader ist aber ebenso für das Lesen von Dateien mit
Clojure-Quellcode verantwortlich und steht auch als Befehl read zur Verwendung in eigenen
Programmen bereit. Dabei kennt der Reader Clojures komplette Syntax. Das Ergebnis des
Readers sind Daten, die evaluiert werden können, das „E“ in REPL. Clojure ist homoikonisch,
das heißt, der Code ist eine Datenstruktur der Sprache selbst. Quelltext in Clojure besteht (im
Wesentlichen) aus Listen und Vektoren in einer Form, die der Reader versteht, und Listen sind
ebenso Datenstrukturen in Clojure wie Vektoren. Im Schritt der Evaluation werden eventuelle
Nebeneffekte realisiert und am Ende ein Resultat zurückgegeben. Dieses Resultat wird
ausgegeben (Print, das „P“ in REPL), und der ganze Vorgang wird wiederholt (Loop,
„L“).
Für den Entwickler heißt das, dass er eine Funktion entwickelt und
interaktiv testet, bis sie seinen Vorstellungen entspricht. Dazu wird er gegebenenfalls den
Aufruf anderer Funktionen, die er in der eigenen verwenden möchte, ausprobieren und so den
benötigten Aufruf finden. Diese Art zu arbeiten, führt zu Funktionen, die besser
getestet sind, weil sie schon während der Entwicklung immer wieder geprüft werden,
gegebenenfalls auch mit verschiedenen Argumenten. Daneben haben solchermaßen
entwickelte Funktionen die Tendenz, kürzer zu sein, was zu besser granuliertem Code
führt.
Das folgende Beispiel zeigt, wie zunächst von der Shell aus die REPL von Clojure gestartet
wird, an der danach einige Befehle eingegeben werden, deren Rückgabewerte die REPL
ausgibt, bis die Sitzung schließlich beendet wird.
shell> java -cp clojure.jar clojure.main
Clojure 1.2.0
user=> (println "Hello World")
Hello World
nil
user=> "Hello World"
"Hello World"
user=> (+ 2 3)
5
user=> (defn addier-2-zahlen [x y] (+ x y))
#’user/addier-2-zahlen
user=> (addier-2-zahlen 2 3)
5
user=> (System/exit 0) ;; oder drücke Strg-d
Diese einfache REPL, die direkt auf der Shell gestartet werden kann, ist
allerdings nicht sehr komfortabel. Sie kann verwendet werden, um etwa jetzt die
einleitenden Beispiele aus dem Grundkurs in Lisp nachzuvollziehen. Sie reicht auch
sicherlich für große Teile dieses Buches aus. Aber sie hat weder eine History noch
nennenswerte Editiermöglichkeiten auf einer Zeile. Es ist möglich, durch den Einsatz von
rlwrap [45], JLine [54] oder ähnlichen Technologien einige fehlende Fähigkeiten
nachzurüsten, allerdings lässt sich auch damit kein wirklich effizientes Arbeitsmittel
einrichten. Zum Ausprobieren, Testen und zum Start produktiver Programme ist
diese REPL ausreichend, für ernsthafte Entwicklung ist die Integration in eine IDE
angebracht.
Netbeans, Eclipse, Emacs und Co.
Da Clojure eine enge Beziehung zu Java hat, existieren Plugins
für die Integration in NetBeans, Eclipse und IntelliJ. Die Verwandtschaft zu Lisp sorgt dafür,
dass die Kombination von Emacs, SLIME und Clojure-spezifischen Anpassungen derzeit die
am häufigsten eingesetzte Umgebung ist. Interessanterweise hat sich Clojure auch im Umfeld
von Vim etablieren können. Laut einer online durchgeführten Rundfrage [57] findet sich die
Kombination von Vim mit Vimclojure sogar auf dem zweiten Platz noch vor NetBeans mit
Enclojure. Eine neuere Umfrage aus dem Juni 2010 [15] sieht nach wie vor Emacs und
SLIME vorne, gefolgt von der direkten Verwendung der REPL von Clojure und
Vimclojure.
Durch die IDE-Integration gewinnt der Programmierer viele Funktionen
hinzu:
- Syntax-Highlighting
- Automatisches korrektes Einrücken (sehr wichtig bei Lisp)
- Completion auf Clojure-Funktionen sowie die Namen von Java-Klassen und
-Methoden
- Zugriff auf die in Clojure eingebauten Hilfsfunktionen
- Direktes Kompilieren einzelner Funktionen aus dem Quelltext heraus
- Navigation im gesamten Quelltext auch größerer Projekte
- Templates für Quelltext
- Integration eines Debuggers
- …
Da aber die jeweiligen Communities ihre Projekte zurzeit zügig weiterentwickeln, ist die
Einrichtung einer solchen Umgebung in aktualisierbaren Dokumenten im Internet deutlich
besser aufgehoben als in Buchform. Im weiteren Verlauf gehen wir daher davon aus, dass eine
solche Umgebung vorhanden ist.
An dieser Stelle sei auf die exzellente, interaktive Einführung in Clojure verwiesen, die
unter dem Namen Labrepl [25] von Stuart Halloway und seinen Mitarbeitern angeboten wird.
Dieses Projekt integriert sich in NetBeans, Emacs und Eclipse, kann ebenso von der
Kommandozeile aufgerufen werden und löst mit Hilfe von Maven alle Abhängigkeiten auf. Ist
Labrepl einmal gestartet, stellt es einen lokalen Webserver bereit, auf dem verschiedene
Tutorials zum Ausprobieren einladen.
Für einen Clojure-Programmierer gestaltet sich der Entwicklungszyklus durch
das Vorhandensein der REPL deutlich anders. Zunächst wird er eine Clojure-Sitzung starten.
Diese kann durchaus tage- oder wochenlang ununterbrochen laufen, während permanent in ihr,
am offenen Herzen, gearbeitet wird. Danach wird er eine Funktion schreiben, in der Regel in
einer separaten Datei, deren Inhalt dann durch die IDE an Clojure weitergereicht wird. In der
Kombination Emacs, SLIME und Clojure reicht dafür das Drücken der Tastenkombination
C-c C-k in Emacs-Notation, also Strg und c zusammen gedrückt, gefolgt von Strg
und k. Das geht schnell. Wenn bei der Entwicklung einer Funktion Aufrufe von
Bibliotheksfunktionen notwendig sind, die sich dem Programmierer nicht sofort erschließen,
wird er diese an der REPL testen. Sobald eine erste Version der zu entwickelnden Funktion
vorliegt, kann diese ebenfalls interaktiv an der REPL getestet werden, wobei auch
gleich verschiedene Kombinationen von Argumenten getestet werden; das schließt
das explizite Testen von Fehlerszenarien mit ein. In den meisten Fällen wird eine
Veränderung der Funktion notwendig sein. Dazu wird der Entwickler den Quelltext der
Funktion umbauen und nur diese eine Funktion separat neu kompilieren (C-c C-c; das
geht noch schneller). Es ist kein Neubau des gesamten Projektes notwendig. Nach
einigen Zyklen kann diese Funktion dann als fertig und gut getestet gelten. Wenn zur
Unterstützung der Entwicklung ein Framework für automatisiertes Testen zum Einsatz
kommt, können die interaktiv eingegebenen Befehle leicht als Basis für das Testskript
dienen.
Diese Art zu arbeiten kann sich deutlich flüssiger anfühlen. Der angestrebte Flow,
der Zustand, in dem Programme nahezu direkt aus den Gedanken entstehen, in dem all die
Werkzeuge, die tatsächlich zwischen der CPU des Menschen und der des Computers
vermitteln, zu verschwinden scheinen, kann leichter erreicht werden. Es muss nicht auf
langwierige Kompiliervorgänge gewartet werden, es muss kein künstliches Szenario geschaffen
werden, um nur eine Funktion eines größeren Programms zu testen. Es gibt auch keine
Probleme im Deployment, bei denen im Fehlerfalle vorsichtshalber doch ein kompletter
Neustart eines Servers durchgeführt wird, um Fehler im Hot-Deploy auszuschließen. Die
direkte Arbeit mit dem Code umfasst jetzt nicht mehr nur das Bearbeiten, sondern auch das
Ausführen.
Die Dokumentation von Funktionen und Daten ist in Clojure in der Sprache eingebaut. Dies
steht im Gegensatz zu vielen anderen Programmiersprachen, in denen speziell formatierte
Kommentare in der Nähe des zu dokumentierenden Konstrukts zur Anwendung kommen
(vergleiche zum Beispiel JavaDoc, Doxygen). So könnte die einfache Addierfunktion aus dem
Abschnitt 2.3 auch wie folgt definiert werden:
(defn addier-2-zahlen
"Addiere die beiden Argumente x und y."
[x y] (+ x y))
Dieser sogenannte Docstring wird Bestandteil der Funktion und kann zur Laufzeit
am REPL-Prompt mit der Funktion doc abgefragt werden. Die Dokumentation zeigt
den vollständigen Namen der Funktion, die Argumentenliste und den Docstring
an.
user> (doc addier-2-zahlen)
-------------------------
user/addier-2-zahlen
([x y])
Addiere die beiden Argumente x und y.
nil
Platzierung des Docstrings
Auf erfahrene Lisp-Programmierer wartet hier eine kleine Falle: Der
Docstring steht vor der Argumentenliste. Hintergrund dessen ist, dass Clojure es erlaubt, in
einer Funktionsdefinition mehrere Varianten unterzubringen, die sich durch ihre
Argumentenliste unterscheiden (vgl. 2.12.1).
Wer den genauen Namen einer Funktion nicht weiß oder sich generell mal etwas
umschauen möchte, wird find-doc schnell zu schätzen wissen, das alte Lisp-Programmierer
unter dem Namen apropos kennen:
user> (doc find-doc)
-------------------------
clojure.core/find-doc
([re-string-or-pattern])
Prints documentation for any var whose
;; ... gekuerzt
nil
Mit Hilfe von find-doc lassen sich also alle bekannten Docstrings mit regulären Ausdrücken
durchsuchen.
user> (find-doc "-doc")
-------------------------
clojure.core/find-doc
([re-string-or-pattern])
Prints documentation for any var whose documentation
;; ... gekuerzt
-------------------------
clojure.core/print-namespace-doc
([nspace])
Print the documentation string of a Namespace.
nil
Seit Version 1.2 liefert Clojure auch die Funktion javadoc mit, die in der REPL
verfügbar ist. Mit dieser Funktion lässt sich die Dokumentation von Java-Klassen aufrufen.
Dazu kann der Funktion entweder die Klasse selbst oder aber ein Objekt übergeben werden,
dessen Klasse dann nachgeschlagen wird.
user> (javadoc java.lang.String)
"http://java.sun.com/javase/6/docs/api/java/lang/String.html"
user> (javadoc "Schau mal String nach")
"http://java.sun.com/javase/6/docs/api/java/lang/String.html"
Beide Aufrufe führen zur Anzeige der Dokumentation der Klasse java.lang.String. Es ist
möglich, die Dokumentation lokal zu installieren, so dass auch ohne Netzverbindung auf die
Informationen zugegriffen werden kann. Clojures Paket für JavaDoc stellt entsprechende
Variablen und Funktionen dafür bereit.
Was die externen Hilfen anbelangt, so existieren im Internet mit jedem Tag
mehr Tutorials und Erfahrungsberichte, die sich durch eine Suche nach „clojure“ leicht finden
lassen sollten. Die Webseite von Clojure liefert Material für den Einstieg und die aktuelle
API-Dokumentation, die aus den Docstrings erzeugt wird.
Der Interaktion mit Java ist das ganze Kapitel 4 gewidmet. In vielen Beispielen
bis dahin tauchen jedoch einfache Konstrukte auf. Dabei geht es immer um die
Instantiierung von Klassen und den Aufruf von Methoden auf den so erzeugten
Objekten.
Neue Objekte können – wie in Java – mit dem Operator new angelegt werden.
Das ist allerdings nicht die Form, die in Clojure-Code am häufigsten zu finden ist.
Clojure-Programmierer verwenden einen Punkt hinter dem Klassennamen, um ein neues
Objekt zu erzeugen. Die beiden folgenden Formen sind also äquivalent.
user> (new java.io.File "/etc")
#<File /etc>
user> (java.io.File. "/etc") ; beachte den Punkt
#<File /etc>
Nachdem ein Objekt erzeugt wurde, sollen auf diesem Methoden aufgerufen werden.
Dazu wird der Methodenname mit einem vorangestellten Punkt als erstes Element des
Aufrufs verwendet. Das entspricht der in Clojure üblichen Form des Aufrufs von
Funktionen.
user> (.isFile (java.io.File. "/etc"))
false
user> (.isFile (java.io.File. "/etc/hosts"))
true
user> (.nextFloat (java.util.Random.))
0.7582344
Der Aufruf von Klassenmethoden, also statischen Methoden ohne eine
Instanz, erfolgt mit Hilfe des Klassennamens und eines Schrägstriches. Dabei kann für den
Zugriff auf Felder auf die Funktionssyntax von Clojure verzichtet werden.
user> (java.net.URLEncoder/encode "Dick & Doof" "UTF-8")
"Dick+%26+Doof"
user> Math/PI
3.141592653589793
user> (Math/PI)
3.141592653589793
Die hier vorgestellten Konstrukte eröffnen den Zugang zur Funktionsvielfalt der Java-Welt.
Diese unvollständige Einführung in die Interaktion mit Java erfolgt an dieser Stelle, um im
weiteren Verlauf des Buches auf diese Vielfalt zurückgreifen und einige Beispiele etwas
interessanter gestalten zu können.
Datentypen sind grundlegende Blöcke, die eine Programmiersprache ausmachen.
Jede Sprache hat eingebaute, primitive Typen, Grunddatentypen. Aus der Welt der
objektorientierten Sprachen kennen Programmierer die Möglichkeit, oder auch die Pflicht,
eigene Typen hinzuzufügen. Dabei unterstützt Clojure im Gegensatz zu anderen
Lisps – wie beispielsweise Common Lisp – mehr Datentypen direkt im Reader.
Das führt neue syntaktische Merkmale für Literale, also hingeschriebene Daten,
ein. Vor allem die eckigen und geschweiften Klammern sind für Programmierer mit
Erfahrungen in Lisp zunächst ungewohnt. Sie haben aber den Vorteil, dass auch die so
dargestellten Datentypen durch die Unterstützung des Readers direkt schreib- und lesbar
sind.
Funktionen unterscheiden sich in Clojure nicht von anderen Datentypen, sie verhalten sich im
Wesentlichen genauso wie eine Gleitkommazahl oder eine Liste. Funktionen können als
Argumente an andere Funktionen übergeben werden. Bei einer Programmiersprache, die einen
Schwerpunkt auf das funktionale Paradigma legt, wäre es angemessen, den Typ der Funktion
noch vor den Zahlen und Strings einzuführen. Wir begegnen der zentralen Rolle, die den
Funktionen zukommt, indem wir ihnen und ihren engen Verwandten einen eigenen
Abschnitt (2.12) widmen.
Im einleitenden Abschnitt 2.2 wurden sowohl Aufruf als auch Definition von Funktionen
bereits grundlegend erklärt. Diese Grundlagen reichen für das Verständnis der Beispiele bis
zum Abschnitt, der sich den Funktionen im Detail widmet.
Die vermutlich einfachsten Typen in Clojure sind true und false. Sie werden von Funktionen
gelegentlich zurückgegeben und lassen sich als Literal hinschreiben. Ein enger Verwandter
dieser Typen ist nil, das für „Nichts“ steht.
user> true
true
user> false
false
user> (< 1 0)
false
user> (if true (println "Wie wahr..."))
Wie wahr...
nil
user> nil
nil
Zu diesem Zeitpunkt ist es ausreichend, diese Typen und Werte einmal gesehen zu
haben, da sie in den noch folgenden Beispielen als Resultat auftauchen können. Der
Abschnitt 2.9 behandelt Clojures Verständnis von Gleichheit und Wahrheit etwas
genauer.
Die notwendigen Datentypen zur Darstellung von Text in Clojure sind Character und String.
Clojure macht es sich dabei leicht, indem es diese Typen von Javas Klassen Character und
String übernimmt. Die Read-Syntax für Strings ist das Einschließen des Strings in doppelte
Anführungszeichen, wie es auch in anderen Programmiersprachen bekannt ist. Die
Read-Syntax für Characters ist ein vorangestellter Backslash. Innerhalb von Strings, die sich
auch über mehrere Zeilen erstrecken dürfen, gelten die gleichen Escape-Sequenzen wie in
Java.
user> "String
mit eingebetteten und direktem \n Umbruch"
"String\nmit eingebetteten und direktem \n Umbruch"
user> \c
\c
user> \newline
\newline
Einige Characters haben einen eigenen Namen, der im Clojure-Code
verwendet werden kann:
- newline,
- space,
- tab,
- backspace,
- formfeed und
- return.
Deren Resultat entspricht den Escape-Sequenzen (\n, …\r), die von Javas
Strings oder auch printf von C bekannt sind. Beginnt ein Character mit einem u, wird er als
Codepoint von Unicode interpretiert, findet Clojure ein o, wird der Character oktal
gelesen.
user> (println \u00DF)
ß
user> (println \o337)
ß
Mit der Funktion str, die ihre Argumente konkateniert, werden neue Strings
erzeugt.
user> (str "Hallo" " " "Welt")
"Hallo Welt"
user> (str "Ganze Zahl " 23 " Gleitkomma " 1.3)
"Ganze Zahl 23 Gleitkomma 1.3"
Die str-Funktion ruft dabei auf den übergebenen Objekten die Methode toString auf und
behandelt nil wie einen leeren String. Weitere Möglichkeiten zur Erzeugung von Strings
beschreibt Abschnitt 2.8.
Zahlen in Clojure sind die Nummerntypen, die in Java von java.lang.Number abgeleitet
werden können – mit einer Ergänzung: Ratios.
Ganze Zahlen werden – wie zu erwarten – einfach hingeschrieben, können aber
auch, wie in Java, mit ihrer jeweiligen Basis zwischen 2 und 36 angegeben werden. Technisch
betrachtet versteht Clojure alle Formate für ganze Zahlen, die auch die Java-Methode
Integer.parseInt versteht. Sollte eine ganze Zahl für den Java-Typ Integer zu groß werden,
wechselt sie automatisch den Typ zu BigInteger.
Die Read-Syntax für Gleitkommazahlen erlaubt zusätzlich zu den auch aus
anderen Sprachen gewohnten Darstellungen das Suffix „M“, um ein BigDecimal, also eine
besonders große Zahl, zu erhalten. Überlauf Bei Berechnungen werden ganze Zahlen vor
Überlaufen geschützt und werden im Falle einer zu großen Berechnung automatisch zu
ausreichend großen BigNums. Wenn in irgendeinem numerischen Ausdruck oder einer
Berechnung eine Gleitkommazahl (Double) auftaucht, wird das Ergebnis auch eine
Gleitkommazahl sein.
user> 23
23
user> 23.0
23.0
user> 8r27
23
user> (+ 23 23.0)
46.0
user> (type 1000000000)
java.lang.Integer
user> (type 1000000000000000000)
java.lang.Long
user> (type 10000000000000000000)
java.math.BigInteger
user> (type 42.0)
java.lang.Double
user> (type 42.0M)
java.math.BigDecimal
Typen und KlassenDas erste Beispiel zu Clojures Zahlentypen verwendet die Funktion
type, um den Typ verschiedener Zahlen zu ermitteln. Eine sehr ähnliche Funktion ist
class. Die beiden Funktionen unterscheiden sich darin, dass
type die Metadaten (vgl. Abschnitt
2.15) einer Datenstruktur der tatsächlichen Typinformation der Java-Implementation vorzieht.
Eine Besonderheit von Clojure gegenüber Java ist der Zahlentyp Ratio. Die Darstellung
von Ratios erfolgt mit einem Schrägstrich. Mit ihnen kann ähnlich wie mit Brüchen gerechnet
werden. Bei einer Ganzzahl-Operation, die keine ganze Zahl zum Ergebnis hat, wird ein
solcher Bruch als Ergebnis geliefert, keine Gleitkommazahl. Das hat den Vorteil, dass die sonst
üblichen Rundungsdifferenzen durch die binäre Repräsentation der Zahlen entfallen. Den
Nenner eines Bruchs liefert die Funktion denominator und den Zähler ermittelt
numerator.
user> 24/6
4
user> 23/5
23/5
user> (+ 23/5 1/5)
24/5
user> (/ 4 5)
4/5
user> (/ 10 5)
2
user> (numerator (/ 4 12))
1
user> (denominator (/ 4 12))
3
Im Zusammenhang mit Ratios ist zu beachten, dass sie in nativem Java unbekannt sind. Ein
schwer zu findender Fehler in Clojure tritt auf, wenn Divisionen durchgeführt und deren
Ergebnisse an Java-Methoden weitergegeben werden. Die Division zweier ganzer Zahlen
erzeugt dann automatisch eine Ratio, und die Java-Methoden werfen Exceptions. Bei
Divisionen empfiehlt es sich daher oft, das Ergebnis explizit zu einem Double zu
konvertieren.
Zahlen lassen sich in Clojure in einer Vielzahl von Funktionen verwenden. Neben
den offensichtlichen arithmetischen Funktionen wie +, -, * und / existieren auch noch inc und
dec, um zu einer Zahl 1 zu addieren oder abzuziehen, sowie min und max, die Minimum und
Maximum einer Menge von Zahlen zurückliefern. Die Division mit Rest stellen die Funktionen
quot und rem dar.
user> (inc 1)
2
user> (dec (inc 23))
23
user> (inc 1.5)
2.5
user> (dec 0.5)
-0.5
user> (inc 3/4)
7/4
user> (dec 8/9)
-1/9
user> (quot 10 3)
3
user> (rem 10 3)
1
user> (rem 11 3)
2
user> (min 1 7 3.9 1/3)
1/3
user> (min 1 7 3.9 1/3 0.01)
0.01
user> (max 1 7 3.9 1/3)
7
user> (* (min 1 7 3.9 1/3) (max 1 7 3.9 1/3))
7/3
Auch für die Vergleiche von Zahlen bietet Clojure die zu erwartenden Funktionen:
<, <=, >, >=, == (vgl. auch Abschnitt 2.9). Ob eine Zahl kleiner, größer oder gleich Null ist,
entscheiden die Funktionen neg?, pos? und zero?. Die Funktionen der Größer-Kleiner-Familie
unterstützen dabei beliebig viele Argumente. Sie können also testen, ob eine Menge von
Zahlen monoton steigend, streng monoton steigend oder (streng) monoton fallend
ist.
user> (== 1 2 3)
false
user> (== 2 8/4 (- 5.5 3.5))
true
user> (< 2 5 10/2 99 101)
false
user> (<= 2 5 10/2 99 101)
true
user> (pos? 4)
true
user> (neg? (- 100 99))
false
user> (zero? (- 2/3 (+ 1/3 1/3)))
true
Alle Beispiele zeigen, dass die verschiedenen Arten von Zahlen beliebig miteinander
kombiniert werden können.
Wer häufig mit mathematischen Problemen zu tun hat, wird an dieser Stelle
eine umfassende Mathematik-Bibliothek vermissen. Zur Lösung dieses Problems macht sich
Clojure die enge Verwandtschaft zu Java zunutze. Der Aufruf von Java-Methoden ist so
einfach, dass es sich schlicht nicht lohnt, Clojure noch eine eigene Bibliothek zu spendieren, die
die ohnehin einfachen Aufrufe nur kapselt. Einige einfache Beispiele verschaffen einen
Eindruck davon, wie Javas mathematische Funktion und Konstanten aufgerufen
werden:
user> Math/PI
3.141592653589793
user> (Math/sin 3)
0.1411200080598672
user> (Math/sin (* Math/PI 2))
-2.4492935982947064E-16
user> (Math/sin 0)
0.0
user> (Math/tan (/ Math/PI 4))
0.9999999999999999
user> (zero? (Math/sin (* Math/PI 2)))
false
Beachtenswert an diesem Beispiel ist auch, dass wir die heile Welt der Ratios verlassen
haben: sin 2π ist zwar sehr klein, aber eben doch nicht Null.
Logische Einheiten eines Programms brauchen Namen, unter denen sie vom Programmierer
angesprochen werden können. In Clojure werden diese Namen mit dem separaten
Datentyp Symbol dargestellt. Regeln für NamenIm Gegensatz zu den meisten anderen
Programmiersprachen sind die Namensregeln für Symbole in Clojure recht tolerant, wie auch
schon die Beispiele im Abschnitt über die Zahlen gezeigt haben. Dort sind Funktionsnamen
wie <= oder * aufgetreten. Im Gegensatz zu anderen Lisps sind die Regeln für Symbolnamen
verhältnismäßig restriktiv. Der Grund hierfür liegt darin, dass Clojure noch recht jung ist
(jung für eine Programmiersprache im Allgemeinen und für ein Lisp erst recht), so dass noch
nicht feststeht, ob bislang nicht erlaubte Zeichen eventuell anderweitig verwendet
werden sollen. Daher gilt im Moment, dass Clojures Symbole, also die Namen, die für
Variablen und Funktionen verwendet werden dürfen, folgende Bedingungen erfüllen
müssen:
- Sie beginnen mit einem Buchstaben oder einem der Zeichen *, +, !, -, _, oder ?.
Sie beginnen ausdrücklich nicht mit einer Ziffer.
- Alle weiteren Zeichen sind eines der erlaubten Anfangszeichen oder aber eine Ziffer.
user> (def +erlaubt-*?23 )
#’user/+erlaubt-*?23
user> (def 111verboten)
java.lang.NumberFormatException:
Invalid number: 111verboten
java.lang.Exception: Unmatched delimiter: )
user> (def verb%ten)
java.lang.Exception:
Unable to resolve symbol: %ten in this context
user> (def _erlaubt_)
#’user/_erlaubt_
Diese Beispiele lassen erahnen, woher die jeweiligen Beschränkungen stammen.
Es ist das Verhalten des Readers, der diese Regeln indirekt bedingt, da verbotene
Zeichen unter Umständen den Reader zu bestimmten Annahmen veranlassen, die sich
im weiteren Verlauf des Quelltextes als falsch herausstellen. Beim Auftreten einer
Ziffer versucht Clojures Reader ein Format für Zahlen zu erkennen, aber sobald
das erste nichtnumerische Zeichen auftritt, wird es – mit wenigen Ausnahmen –
problematisch.
Eine für Lisp-Programmierer verwirrende Eigenschaft von Symbolen ist,
dass sie nicht gespeichert werden. Jedes Auftreten eines Symbols führt im Reader
zur Erzeugung eines neuen Symbols. Das hat in der Regel keinen Einfluss auf die
Programmierung, hilft aber dabei, einen Namensraum sauber zu halten. Symbole
sind somit keine Speicherorte, diese Aufgabe übernimmt der Datentyp Var (siehe
Abschnitt 2.7.1).
Eng verwandt mit den Symbolen sind die Keywords, die jederzeit an einem
Doppelpunkt zu erkennen sind. Wir verwenden die Bezeichnungen „Keyword“ und
„Schlüsselwort“ gleichwertig. Der Doppelpunkt spielt in Clojures Schema für die Benennung
von Objekten nicht die Rolle eines Trenners zwischen Namespaces oder Packages, er ist aber
auch nicht Bestandteil des Namens eines Keywords, sondern vielmehr die Syntax zur
Erzeugung eines Keywords. Werden Keywords evaluiert, liefern sie sich selbst wieder zurück.
Keywords sind, anders als in anderen Lisp-Dialekten, keine Symbole. Sie finden häufig
Verwendung als Schlüssel in Clojures assoziativen Datenstrukturen (Maps), da sie einen
schnellen Test auf Gleichheit implementieren und in dem Fall auch als Funktion fungieren
können.
Die Funktion keyword? testet, ob ein Keyword vorliegt, die Funktion keyword erzeugt ein
neues Keyword, optional in einem Namensraum.
user> :keyword
:keyword
user> (type :keyword)
clojure.lang.Keyword
user> (keyword? :istdaseinkeyword?)
true
user> (keyword "neues-keyword-ohne-doppelpunkt")
:neues-keyword-ohne-doppelpunkt
user> (keyword "user" "neu-im-user-namespace")
:user/neu-im-user-namespace
Zusammengesetzte Daten werden in diesem Buch durchgehend mit dem Begriff
„Datenstrukturen“ bezeichnet. Dabei handelt es sich um eine Sammlung von Werten meist
gleicher – gelegentlich auch verschiedener – Art, die einer Identität zugeordnet werden. Hinter
dieser sperrigen Beschreibung verbergen sich letztlich die folgenden Datenstrukturen aus
Clojures Sprachumfang:
- Listen,
- Vektoren,
- Maps und
- Sets.
Allen diesen Typen ist gemein, dass sie sich beliebig ineinanderschachteln lassen
und dass sie eine Read-Syntax haben. CollectionZudem leiten sich alle diese Klassen von
java.util.Collection ab, so dass sie sich in das Collection Framework von Java integrieren.
Bei ineinandergeschachtelten Datenstrukturen muss auf Listen speziell geachtet
werden, da sie als Befehlsaufrufe evaluiert werden, sofern sie nicht durch ein Quote
davor geschützt sind. Die Beschreibungen der jeweiligen Typen gehen explizit darauf
ein.
Bevor die Gemeinsamkeiten der verschiedenen Typen, die zu Clojures Collection-Typen
gehören, besprochen werden, ist es wichtig, sich die Unterschiede deutlich zu machen. Die
Typen lassen sich in zwei Kategorien aufteilen:
- assoziative und
- sequentielle Datenstrukturen.
Clojure zählt zusätzlich zu den offensichtlichen Maps und Sets auch die Vektoren zu den
assoziativen Typen, da deren Index als Schlüssel aufgefasst werden kann und einen schnellen
Zugriff garantiert. Listen hingegen sind sequentielle Datenstrukturen.
Wichtig wird dieser Unterschied beim Zugriff auf die Elemente der Datenstrukturen, der
durch die Funktionen der folgenden Liste ermöglich wird.
-
get
- (get coll key default?). Aus jeder assoziativen Datenstruktur kann unter
Angabe eines geeigneten Schlüssels das jeweilige Element extrahiert werden. Wenn
der Schlüssel nicht gefunden wird, wird entweder nil zurückgeliefert oder aber
der als drittes Argument angegebene Wert. Diese Funktion funktioniert nicht auf
sequentiellen Typen und liefert dort stillschweigend immer nil zurück.
-
nth
- (nth coll key default?). Extrahiert ähnlich wie get ein Element aus einer
Datenstruktur, fokussiert aber Datenstrukturen, die einen abzählbaren Charakter
haben. Auf assoziativen Strukturen wie Maps wirft nth eine Exception, der Zugriff
auf Vektoren hingegen funktioniert.
Eine unter Umständen wichtige Eigenschaft der beiden Funktionen ist auch ihre
Zugriffscharakteristik. Der assoziative Zugriff mit get garantiert einen (nahezu) konstanten
Zugriff, während die Zeit bei nth im schlimmsten Falle linear mit der Anzahl der Elemente
steigen kann.
Die Funktionen von Clojure, die einen Collection-Typen erwarten und dies in ihrer
Argumentenliste duch den Namen „coll“ signalisieren, weisen dadurch darauf hin, dass es für
sie nicht notwendig wichtig ist, welcher Art genau die Collection ist. Diese Funktionen
funktionieren auf allen in diesem Abschnitt vorgestellten Datenstrukturen. Ihr Verhalten wird
sich in einigen Fällen leicht unterscheiden, dann aber, weil es die jeweilige Datenstruktur
suggeriert.
-
count
- (count coll). Die Anzahl der Elemente in einer Datenstruktur. Sie wird in
jedem Fall in
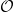 (1) ermittelt.
(1) ermittelt.
-
conj
- (conj coll x & xs). Die Funktion conj (sprich: „konnsch“, für engl. „conjoin“)
fügt einer Collection einen oder mehrere Einträge hinzu, wobei sie je nach Typ
der Collection eine passende Stelle zum Einfügen wählt. Für diese wie auch für
alle spezialisierten Funktionen zur „Manipulation“ der Datenstrukturen gilt, dass
keine von ihnen jemals das Original verändert. Wann immer im Folgenden von
Änderungen oder Manipulationen die Rede ist, wird eine neue Datenstruktur
erzeugt, die die Änderungen enthält.
-
coll?
- (coll? coll). Diese Funktion testet, ob einer von Clojures
Collection-Datentypen vorliegt.
-
seq
- (seq coll). Jede Datenstruktur kann zu einer Sequence konvertiert werden.
Sequences, für die es viele Funktionen gibt, werden im Abschnitt 2.16 detailliert
beschrieben. Durch die Funktion seq werden alle Funktionen, die auf Sequences
arbeiten, direkt für die Collection-Typen verfügbar. In der Regel ist aber ein
expliziter Aufruf von seq nicht notwendig, da die Funktionen, die Sequences
verarbeiten können, sich selbst darum kümmern.
Listen sind einfach verkettete Listen und werden, wie von Lisp generell gewohnt, durch runde
Klammern im Quelltext erzeugt. Clojure-Code selbst besteht aus Listen, die wiederum Listen
und andere Datenstrukturen enthalten können. In Abschnitt 2.2 wurde die Regel eingeführt,
dass eine Liste in Lisp immer evaluiert wird, indem das erste Element als Funktion und die
folgenden Elemente als Argumente angesehen werden. Daher muss eine als Literal angegebene
Liste durch Quoten vor der Evaluierung geschützt werden. Alternativ werden Listen durch die
Funktion list erzeugt.
user> (type ’(1 2 3))
clojure.lang.PersistentList
user> (type (list 1 2 3))
clojure.lang.PersistentList
user> ’(1 2 3)
(1 2 3)
user> ’("dies" "ist" 1 "Liste")
("dies" "ist" 1 "Liste")
user> (list? ’("dies" "ist" 1 "Liste"))
true
Der Typ PersistentList, der von type als Resultat geliefert wurde, bezeichnet die
Java-Klasse, die in Clojure Listen implementiert. Im Abschnitt 3.2.2 wird auf die
Implementation und die Besonderheiten näher eingegangen. In diesem Beispiel werden
zunächst zwei Listen erzeugt, deren Typ ermittelt wird. Dazu kommt einmal die Form als
Literal zum Zuge und einmal die Erzeugung einer Liste mit Hilfe der Funktion list. Die
Typenprüfung erfolgt mit dem Befehl list?, wie das Beispiel ebenfalls zeigt. Die
letzten zwei Befehle zeigen, dass die Elemente der Liste auch verschiedenartig sein
können.
Mit dem Befehl list* existiert noch eine weitere Möglichkeit, Listen zu erzeugen. Dieser
erwartet ebenfalls mehrere Argumente, von denen das letzte jedoch eine Liste (genauer: eine
Sequence, vgl. Abschnitt 2.16) sein muss und deren Elemente einzeln betrachtet
werden:
user> (def list1 ’(3 4))
#’user/list1
user> (list* 1 2 list1)
(1 2 3 4)
Einzelne Elemente einer Liste werden mit nth ermittelt. Ein
unter Umständen schwer zu findender Fehler ist, dass der Zugriff mit get immer nil
liefert.
user> (nth ’(1 2 3 4 5 6) 1)
2
;; get geht nicht
user> (get ’(1 2 3 4 5 6) 1)
nil
Um einer Liste ein neues Element hinzuzufügen, wird der Befehl conj verwendet.
Gemäß den Erwartungen an eine Liste fügt conj das neue Element vorne an der Liste
an:
user> (conj list1 12)
(12 3 4)
user> list1
(3 4)
Dabei wird die in list1 gespeicherte Liste durch das Hinzufügen nicht verändert. Listen
sind, wie fast alle Daten in Clojure, unveränderlich (siehe auch Abschnitt 3.2.1). Das Resultat
des Aufrufs von conj ist eine neue Liste.
Geschachtelte Listen werden bei ihrer Erzeugung als Literal nicht evaluiert, bei der
Verwendung von list hingegen findet eine Evaluation statt.
user> ’(:geschachelt (+ 1 2))
(:geschachelt (+ 1 2))
user> (list :geschachtelt (+ 1 2))
(:geschachtelt 3)
Wenn eine Evaluation im Literal notwendig ist, kann mit dem Backtick ein
anderer Quote-Operator mit Namen „Syntax-Quote“ verwendet werden. Innerhalb eines
solcherart gequoteten Ausdrucks kann mit dem „Unquote-Operator“ (Tilde) die Evaluation
explizit wieder eingeschaltet werden.
user> ‘(1 2 ~(+ 2 3))
(1 2 5)
Lisp-Programmierer werden merken, dass hier die Tilde das gewohnte Komma ersetzt,
dessen Verwendung in Clojure wie ein Leerzeichen zu betrachten ist. Diese Form des
Quotens tritt häufig im Zusammenhang mit Makros auf, denen sich Abschnitt 2.12.3
widmet.
Listen haben, bedingt durch die Implementation als verkettete Liste, eine
lineare Zugriffscharakteristik, (N). Somit eignen sie sich eher als Speicher für Elemente, auf
die nacheinander zugegriffen werden soll. Ihr primärer Anwendungszweck in Clojure ist als
Datenstruktur für Clojure-Code.
Vektoren enthalten ebenfalls geordnete Elemente, allerdings mit einer (nahezu) konstanten
Zugriffscharakteristik. Von einem Vektor erwartet ein Programmierer, dass der Zugriff
innerhalb von (1) erfolgt. Solange die Vektoren eine hinreichend kleine Anzahl von
Elementen enthalten, wird Clojure durch die Implementation seiner persistenten
Datenstrukturen einen fast konstanten Zugriff erlauben.
Die Read-Syntax für Vektoren sind eckige Klammern. Für
Programmierer mit Lisp-Erfahrungen ist das Auftauchen von Vektoren im normalen Quelltext,
beispielsweise in der Argumentenliste von Funktionsdefinitionen oder in der Binding-Form von
let, zumindest ungewohnt, gelegentlich auch verwirrend. Mit der Faustregel, dass
überall dort Vektoren verwendet werden, wo eher keine Evaluierung stattfinden soll,
lässt sich die Entscheidung über den richtigen Klammertyp in der Regel korrekt
treffen.
Zusätzlich zur Read-Syntax mit eckigen Klammern kann auch der Befehl vector verwendet
werden, der aus seinen Argumenten einen neuen Vektor erzeugt.
user> (type [1 2 3])
clojure.lang.PersistentVector
user> (type (vector 1 2 3))
clojure.lang.PersistentVector
user> (= (vector 1 2 3) [1 2 3])
true
Eine etwas andere Semantik hat der Befehl vec, der nur ein Argument entgegennimmt:
eine Datenstruktur, aus deren Elementen vec einen Vektor erzeugt. Beispielsweise
können so die Elemente einer Liste in einen Vektor derselben Elemente überführt
werden.
user> (vec ’(1 2 3 "vier"))
[1 2 3 "vier"]
ApplyIm Falle von Vektoren existiert eine spezielle Funktion, die eine Datenstruktur als Argument akzeptiert und einen Vektor erzeugt. Das Muster taucht jedoch häufig auf: Die Argumente für eine Funktion liegen in einer Liste oder einem Vektor vor. In diesen Fällen kann auf die Funktion
apply zurückgegriffen werden. Sie bewirkt, dass die Argumente aus einer Listenstruktur entnommen und der Funktion einzeln übergeben werden. Anwendungen von
apply folgen später im Buch.
Auf die Elemente eines Vektors kann mit den Funktionen get und nth
zugegriffen werden:
user> (def vec1 [1 2 3])
#’user/vec1
user> (get vec1 2)
3
user> (nth vec1 2)
3
user> (nth vec1 6 :default_wert_wenn_nicht_vorhanden)
:default_wert_wenn_nicht_vorhanden
Eine interessante Eigenschaft von Clojures Vektoren ist, dass sie auch als Funktionen
fungieren können. Sie erwarten dann den Index, auf den zugegriffen werden soll, als Argument
und liefern das Element an der Stelle zurück:
user> (def vec-is-auch-fn [\a \b \C])
#’user/vec-is-auch-fn
user> (vec-is-auch-fn 2)
\C
user> (["null" "eins" "zwei" "drei"] 1)
"eins"
Der zweite Aufruf in diesem Beispiel verwendet direkt einen als Literal hingeschriebenen
Vektor als Funktion. Eine durchaus ungewöhnliche Möglichkeit.
Geschachtelte Vektoren werden evaluiert, eine eventuell vorhandene Liste wird also
wie ein Befehlsaufruf interpretiert, sofern die Liste nicht durch ein Quote davor geschützt
wird.
user> [1 2 (+ 2 3)]
[1 2 5]
user> [1 2 ’(+ 2 3)]
[1 2 (+ 2 3)]
Für geschachtelte Vektoren existiert für den Zugriff auf die Elemente eine Abkürzung, die es
erlaubt, die Indizes der geschachtelten Strukturen als Vektor zu übergeben. Diese Aufgabe
übernimmt die Funktion get-in.
user> (get-in ["A" ["Beh" ["Zeh" "Deh"] "Eh"] :f]
[1 1])
["Zeh" "Deh"]
user> (get-in ["A" ["Beh" ["Zeh" "Deh"] "Eh"] :f]
[1 1 0])
"Zeh"
Vektoren können, ebenso wie Listen, nicht verändert werden. Gleichwohl kann
aber einem Vektor ein neuer Wert hinzugefügt oder ein Wert überschrieben werden, was als
Resultat zu einem neuen Vektor führt:
user> (assoc vec1 2 99)
[1 2 99]
user> (conj vec1 100)
[1 2 3 100]
user> vec1
[1 2 3]
Die Funktion assoc (gesprochen in etwa „assohsch“ für englisch „associate“) assoziiert mit
einem Index in einem Vektor einen neuen Wert, conj fügt ans Ende eines Vektors einen
weiteren Wert hinzu. Im Beispiel ist erkennbar, dass vec1 durch den assoc-Befehl nicht
verändert wurde: Nach den beiden Operationen hat vec1 den gleichen Wert, und in der REPL
wurde nach dem Aufruf von conj ein neuer Vektor ausgegeben. Ähnlich wie get-in
funktioniert assoc-in bei geschachtelten Vektoren
user> (assoc-in ["A" ["Beh" ["Zeh" "Deh"] "Eh"] :f]
[1 1 0]
"Nase")
["A" ["Beh" ["Nase" "Deh"] "Eh"] :f]
Mit der Funktion update-in existiert eine Variante von assoc-in, die nicht den
neuen Wert erwartet, sondern eine Funktion, die den neuen Wert zurückgibt. In
Situationen, in denen man zunächst den neuen Wert berechnen und eventuell sogar in einer
lokalen Variablen zwischenspeichern würde, kann sich der Einsatz von update-in
empfehlen.
user> (update-in [[1 1] 2 3] [0 1] inc)
[[1 2] 2 3]
Aus Performancegründen kann es sinnvoll sein, Vektoren mit einem
Grunddatentyp zu verwenden. Diese Vektoren verwenden intern ein effizienteres
Speichermodell. Wie bei allen Optimierungen sollte sie nur erfolgen, wenn die entsprechende
Stelle im Programm als Flaschenhals identifiziert wurde. Ein Vektor von primitiven Typen
wird unter Angabe des Typs mit der Funktion vector-of angelegt. Der Typ ist dabei einer
der möglichen Werte
- :int,
- :long,
- :float,
- :double,
- :byte,
- :short,
- :char oder
- :boolean.
user> (def int-vect (vector-of :int))
#’user/int-vect
user> (conj int-vect 2)
[2]
user> (conj int-vect "3")
#<CompilerException java.lang.ClassCastException:
java.lang.String cannot be cast to java.lang.Character>
user> (conj int-vect :oha)
#<CompilerException java.lang.ClassCastException:
clojure.lang.Keyword cannot be cast to java.lang.Character>
Beachtenswert an vector-of ist, dass diese Funktion, die erst seit Clojure 1.2 verfügbar ist,
in Clojure implementiert ist, ohne Rückgriff auf Java. Diesem Thema widmet sich das
Kapitel 5.
Der Datentyp für das Speichern assoziativer Schlüssel-Wert-Paare ist in Clojure die Map.
Clojure unterstützt dabei zwei verschiedene Varianten: eine, bei der die Reihenfolge der
Elemente nicht festgelegt ist („Hash-Map“), und eine, bei der die Elemente nach dem Schlüssel
sortiert werden („Sorted-Map“). Für die Schlüssel gilt, dass die Methoden equals und
hashCode unterstützt sein müssen, sowie – im Falle der sortierten Map –, dass die Schlüssel
das Interface Comparable implementieren oder alternativ eine Instanz von Comparator sein
müssen.
Ein wesentlicher Unterschied zwischen den Varianten ist, dass sie verschieden
schnell Zugriff auf ihre Elemente gewähren. Die Hash-Map, die weitaus häufiger verwendet
wird, garantiert einen Zugriff innerhalb von (log 32N), während die sortierte Map nur
(log N) garantiert.
Das folgende Beispiel zeigt die Erzeugung von Maps und den Zugriff auf
ihre Elemente. Besonders beachtenswert ist hier, dass Maps, ebenso wie Vektoren, auch
Funktionen sind. Wird der Name einer Map als Funktion verwendet, erwartet diese einen
Schlüssel als Argument und liefert den Wert zum Schlüssel zurück. Dieser Zugriff wird in
idiomatischem Clojure-Code dem expliziten Zugriff mit der Funktion get vorgezogen.
KeywordsDie Verwendung von Keywords als Schlüssel einer Map ist häufig anzutreffen, so auch
in diesem Beispiel. Diese Schlüssel fungieren dann ebenfalls als Funktion und erwarten beim
Aufruf eine Map als Argument.
user> (def map1 {:a 1 :b 2 :z 26 :c 3})
#’user/map1
user> map1
{:a 1, :b 2, :z 26, :c 3}
user> (get map1 :a)
1
user> (map1 :a) ;; map als funktion
1
user> (:a map1) ;; schluessel/keyword als fktn.
1
user> (def map2 {:a "Ah" :o "Oh"})
#’user/map2
user> (:a map2) ;; keyword :a mit anderer map
"Ah"
user> (sorted-map :a 1 :b 2 :z 26 :c 3)
{:a 1, :b 2, :c 3, :z 26}
user> (hash-map :a 1 :b 2 :c 3 :z 26)
{:z 26, :a 1, :c 3, :b 2}
Dieses Beispiel verwendet sowohl die Read-Syntax mit geschweiften Klammern, die eine
Hash-Map erzeugt, als auch die explizite Erzeugung mit Hilfe der Funktionen hash-map und
sorted-map in den letzten beiden Aufrufen. Liegen die Schlüssel und ihre Werte separat
vor, beispielsweise in zwei Vektoren, kann die Funktion zipmap sie zu einer Map
zusammenfassen.
user> (zipmap [:a :b :c :d] [1 2 3 4])
{:d 4, :c 3, :b 2, :a 1}
Sofern die verwendeten Schlüssel die oben genannten Bedingungen erfüllen, können
auch andere Typen verwendet werden. Beispielsweise Symbole, für die ebenfalls gilt, dass sie
zu Funktionen der Map werden.
user> (def map2 {’sym1 "Wert von Symbol1"
’sym2 "Wert von Symbol2"})
#’user/map2
user> map2
{sym1 "Wert von Symbol1", sym2 "Wert von Symbol2"}
user> (’sym1 map2 :default_value)
"Wert von Symbol1"
user> (’sym3 map2 :default_value)
:default_value
Für noch andere Schlüsseltypen, wie beispielsweise Strings, gilt nicht mehr
der bequeme Zugriff auf die Elemente mit Hilfe der Schlüssel als Funktion, gleichwohl
funktioniert die Map selbst als Funktion nach wie vor.
user> (def map3 {"aber" "auch" "Strings" "koennen"
"verwendet" "werden"})
#’user/map3
user> (get map3 "aber")
"auch"
user> ("aber" map3)
java.lang.ClassCastException:
java.lang.String cannot be cast to clojure.lang.IFn
user> (map3 "aber")
"auch"
user> (def map4 {"wenn" "auch",
"besser" "mit",
"Kommas" "oder?"})
#’user/map4
user> ({1 "Eins", 2 "Zwei"} 2)
"Zwei"
Die letzte Eingabe in diesem Beispiel verwendet eine in Read-Syntax notierte Map direkt als
Funktionsaufruf. Das ihr übergebene Argument ist 2, es werden hier also Integerwerte als
Schlüssel verwendet. Es ist nicht notwendig, aber üblich, gleichartige Schlüssel zu verwenden.
Clojure erlaubt auch eine Mischung aus verschiedenen Schlüsseltypen wie das nächste Beispiel
demonstriert.
user> (def mix {:k "Key", 1 "Int", "s" :string})
#’user/mix
user> (mix :k)
"Key"
user> (mix 1)
"Int"
user> (mix "s")
:string
Geschachtelte Maps verhalten sich ebenso wie Vektoren: Die Ausdrücke werden
evaluiert, und für enthaltene Listen gelten die üblichen Quoting-Regeln.
user> {:a 1 :b 2 :c (+ 2 3)}
{:a 1, :b 2, :c 5}
user> {:a 1 :b 2 :c ’(+ 2 3)}
{:a 1, :b 2, :c (+ 2 3)}
user> {:a 1 :b 2 :c ‘(2 ~(* 3 4))}
{:a 1, :b 2, :c (2 12)}
Auch geschachtelte Maps erlauben den abkürzenden Zugriff mit get-in.
user> (get-in {:a {:b {:c "Zeh"}
:d "Deh"}
:e "Eh"}
[:a :b :c])
"Zeh"
Soll aus einer Map nur eine Untermenge der Schlüssel-Wert-Paare extrahiert
werden, kann die Funktion select-keys verwendet werden. Sie erwartet als Argumente eine
Map sowie einen Vektor mit den zu erhaltenen Schlüsseln und liefert dann eine Map zurück,
die nur noch die angegebenen Schlüssel enthält. Nicht gefundene Schlüssel werden dabei
stillschweigend ignoriert.
user> (select-keys {:a 1 :b 2 :z 26 :c 3}
[:a :z])
{:z 26, :a 1}
user> (select-keys {:a 1 :b 2 :z 26 :c 3}
[:a :z :q])
{:z 26, :a 1}
Ein elementweiser Vergleich einer Hash-Map mit einer sortierten Map ist wahr,
wenn die Werte alle gleich sind, auch wenn die Objekte verschieden sind. Das folgende Beispiel
demonstriert das.
user> (def map1 {:a 1 :b 2 :z 26 :c 3})
#’user/map1
user> (= map1 (hash-map :a 1 :b 2 :c 3 :z 26))
true
user> (sorted-map :a 1 :b 2 :z 26 :c 3)
{:a 1, :b 2, :c 3, :z 26}
user> (= map1 (sorted-map :a 1 :b 2 :z 26 :c 3))
true
user> (identical? map1
(sorted-map :a 1 :b 2 :z 26 :c 3))
false
Die Manipulation von Maps, gleich welcher Art, erfolgt – wie bei Vektoren –
mit den Funktionen assoc und conj, wobei assoc bestehende Werte überschreiben oder aber
neue Schlüssel-Wert-Paare hinzufügen kann, während conj nur das als separate Map
übergebene Paar der ursprünglichen Map hinzufügt. Zusätzlich unterstützen Maps auch das
Entfernen von Einträgen mit Hilfe von dissoc und bei geschachtelten Strukturen die
Manipulation mit assoc-in
user> (assoc map1 :a 99)
{:a 99, :b 2, :z 26, :c 3}
user> (assoc map1 :d 4)
{:d 4, :a 1, :b 2, :z 26, :c 3}
user> (conj map1 {:d 4})
{:d 4, :a 1, :b 2, :z 26, :c 3}
user> (dissoc map1 :z)
{:a 1, :b 2, :c 3}
user> (assoc-in {:a {:b {:c "Zeh"}
:d "Deh"}
:e "Eh"}
[:a :b :c]
"Ohr")
{:a {:b {:c "Ohr"}, :d "Deh"}, :e "Eh"}
Eng verwandt mit assoc-in ist die Funktion update-in, die ebenfalls einen Vektor von
Schlüsseln für den Zugriff auf Elemente in einer geschachtelten Map versteht, den neuen Wert
jedoch mit einer Funktion berechnet. Diese Funktion wird als drittes Argument angegeben und
bekommt den aktuellen Wert aus der Map übergeben. Eventuelle weitere Argumente von
update-in werden der Funktion zusätzlich weitergereicht, wie der letzte Ausdruck in
folgendem Beispiel zeigt.
user> (def wahl {:spd {:stimmen 10}
:cdu {:stimmen 10}
:fdp {:stimmen 10}
:gruen {:stimmen 10}
:piraten {:stimmen 10}})
#’user/wahl
user> (update-in wahl [:piraten :stimmen] inc)
{:spd {:stimmen 10}, :cdu {:stimmen 10},
:fdp {:stimmen 10}, :gruen {:stimmen 10},
:piraten {:stimmen 11}}
user> (update-in {:a 1 :b [1 2 3]} [:b] conj 4)
{:a 1, :b [1 2 3 4]}
Sehr interessant für eine größere Änderung an einer Map ist auch die Funktion replace.
Diese nimmt eine Ersetzungsmap sowie eine Quell-Sequence entgegen und ersetzt in der
Quell-Sequence alle Werte, die als Schlüssel in der Ersetzungsmap gefunden werden, durch den
jeweiligen Wert in der Ersetzungsmap. Das folgende Beispiel weist Clojure also
an, im als zweites Argument übergebenen Vektor :a durch :X und 33 durch 44 zu
ersetzen.
user> (replace {:a :X, 33 44} [1 2 33 :k :l :a])
[1 2 44 :k :l :X]
Weitere Funktionen, die auf Maps operieren können, stellt die folgende
Liste zusammen.
-
contains?
- Prüft das Vorhandensein eines Schlüssels in einer Map. Diese Funktion
verwirrt viele Einsteiger, da sie sich zwar bei assoziativen Datenstrukturen wie
erwartet verhält, bei Vektoren aber beispielsweise nur prüft, ob das Argument ein
valider Index wäre. Bei Listen gibt contains? schlichtweg immer nil zurück.
-
find
- Findet in einer Map einen Schlüssel und liefert einen Vektor mit dem Schlüssel
sowie dem Wert zurück.
-
keys
- Ermittelt alle Schlüssel einer Map in Form einer Sequence (siehe Abschnitt 2.16).
-
vals
- Ermittelt alle Werte einer Map.
-
map?
- Prüft, ob das Argument eine Map ist.
Das folgende Beispiel zeigt diese Funktionen bei der Arbeit.
user> (def map1 {:a 1 :b 2 :z 26 :c 3})
#’user/map1
user> (contains? map1 :a)
true
user> (find map1 :a)
[:a 1]
user> (keys map1)
(:a :b :z :c)
user> (vals map1)
(1 2 26 3)
user> (map? map1)
true
Abschließend für diesen Teilabschnitt erfolgt noch der Hinweis, dass Clojure kleine Maps
optimiert, was in Abschnitt 2.18.2 beschrieben wird.
Der passende Datentyp für eine Sammlung von Werten ohne Duplikate ist Clojures Set. Sets
liegen, ebenso wie Maps, in zwei Varianten vor, die sich darin unterscheiden, ob ihre
Werte sortiert oder in unvorhersehbarer Reihenfolge aus dem Set zurückgeliefert
werden.
Zum Anlegen stehen mit hash-set und sorted-set zwei Funktionen für die
jeweiligen Varianten zur Verfügung. Die Read-Syntax für Hash-Sets ist #{}, die Elemente
werden also in geschweifte Klammern eingefasst und zur Unterscheidung von Maps mit einem
vorangestellten Rautenzeichen (auch: Hash-Zeichen) versehen.
user> #{:a 3}
#{3 :a}
user> (type #{1 2 3})
clojure.lang.PersistentHashSet
user> (sorted-set 99 77 88 1 100)
#{1 77 88 99 100}
user> (set ’(1 12 13 14 0 12))
#{0 1 12 13 14}
user> (set ["auch" "aus" "vektoren"])
#{"vektoren" "auch" "aus"}
user> (set {:a 11 :b 22 :c 33})
#{[:a 11] [:b 22] [:c 33]}
Das Beispiel zeigt zudem die Verwendung der Funktion set, die die enthaltenen Werte einer
der anderen Datenstrukturen als Set liefert.
Bei der Erzeugung als Literal oder mit der Funktion hash-set geht Clojure seit
Version 1.2 davon aus, dass ein doppelt vorhandener Eintrag ein Fehler ist, und wirft eine
IllegalArgumentException. Wenn jedoch aus einer anderen Datenstruktur ein Set erzeugt wird,
werden Duplikate entfernt.
user> #{:a 3 3 :b :a}
java.lang.IllegalArgumentException: Duplicate key: 3
user> (hash-set :a 3 3 :b :a)
java.lang.IllegalArgumentException: Duplicate key: 3
user> (set ’(:werte :sind :nur :nur 1 :mal :im_set))
#{1 :im_set :sind :nur :mal :werte}
Wie bei den anderen Datenstrukturen auch können einem Set weitere Werte mit
conj hinzugefügt werden, sofern sie nicht bereits Bestandteil sind.
user> (conj #{:a :b :c} :d)
#{:a :c :b :d}
user> (conj #{:a :b :c} :c)
#{:a :c :b}
Etwas ungewöhnlich ist der Zugriff auf die Elemente eines Sets: Die Elemente
fungieren sowohl als Schlüssel als auch als Wert. Wenn ein Set einen Eintrag enthält, auf den
mit get zugegriffen werden soll, liefert es den Eintrag selbst wieder zurück, ansonsten nil.
Wie schon bei Vektoren und Maps gesehen, fungieren auch Sets als Funktionen ihrer
Elemente.
user> (get #{"eine" "kleine" "dickmadam"} "eine")
"eine"
user> (get #{"eine" "kleine" "dickmadam"} 0)
nil
user> (get (hash-set 0 1 2 3) 0)
0
user> (#{"eine" "kleine" "dickmadam"} "kleine")
"kleine"
Eine oft gesehene Anwendung von Sets ist ihre Verwendung als Funktion, wenn
aus einer Listen von Werten nur einige erlaubte gefiltert werden sollen. Das Filtern
bewirkt die Funktion mit Namen filter. Sie akzeptiert eine Funktion und eine
Liste von Werten als Argumente. Die Funktion wird für jedes Element aufgerufen
und entscheidet mit ihrem Rückgabewert über den Verbleib eines Ergebnisses. Mit
einem Set als Filterfunktion lassen sich so beispielsweise die Zahlen aus einer Liste
filtern.
user> (def zahlen #{0 1 2 3 4 5 6 7 8 9})
#’user/zahlen
user> (def elemente [3 "Chinesen" "mit" 1 "Kontrabass"])
#’user/elemente
user> (filter zahlen elemente)
(3 1)
Es wird also für alle Elemente von elemente die Funktion zahlen aufgerufen. Da ein Set
immer nil liefert, wenn auf ein nicht vorhandenes Element zugegriffen wird, führt
unter anderem der Zugriff auf „Chinesen“ zu nil, so dass filter diesen Eintrag
entfernt.
user> (zahlen "Chinesen")
nil
user> (zahlen 3)
3
Dieses Beispiel mit der Funktion filter demonstriert eine typische Lösung aus dem Bereich
der funktionalen Programmiersprachen.
Eine Variante der normalen Maps sind die StructMaps, bei denen eine Strukturdefinition einen
Satz von Schlüsseln vorgibt. Wir orientieren uns bei der Schreibweise dabei am
dahinterstehenden Java-Typ (PersistentStructMap). StructMaps verhalten sich nahezu
komplett genauso wie Maps, mit dem wichtigen Unterschied, dass die definierten
Basisschlüssel immer vorhanden sind. Gleichwohl ist es möglich, weitere Schlüssel-Wert-Paare
hinzuzufügen. Die Verwendung von StructMaps wird meist der Verwendung von „structs“ aus
C oder Objekten aus Java ähneln.
Die Definition einer StructMap erfolgt durch Verwendung des Befehls defstruct,
eine Instanz wird dann mit struct-map angelegt. Es existiert keine Read-Syntax. Das folgende
Beispiel zeigt die Definition und die Erzeugung einer Instanz, wobei es verdeutlicht, welche
Rolle die Basisschlüssel spielen und dass auch weitere Schlüssel aufgenommen werden
können.
user> (defstruct kinofilm :titel :regisseur)
#’user/kinofilm
user> (type (struct-map kinofilm
:titel "Der Herr der Ringe I"
:regisseur "Peter Jackson"))
clojure.lang.PersistentStructMap
user> (struct-map kinofilm
:titel "Der Herr der Ringe I"
:regisseur "Peter Jackson")
{:titel "Der Herr der Ringe", :regisseur "Peter Jackson"}
user> (struct-map kinofilm
:titel "Der Herr der Ringe I"
:regisseur "Peter Jackson"
:jahr 2001)
{:titel "Der Herr der Ringe I", :regisseur "Peter Jackson",
:jahr 2001}
user> (struct-map kinofilm
:titel "Der Herr der Ringe I"
:jahr 2001)
{:titel "Der Herr der Ringe I", :regisseur nil, :jahr 2001}
StructMaps erlauben intern eine etwas effektivere Speicherung der Schlüssel, haben also
gegenüber normalen Maps einen leichten Performancevorteil. Auch für den Zugriff auf die
Werte hinter den Basisschlüsseln lassen sich etwas effizientere Funktionen durch den Befehl
accessor erzeugen.
user> (def kinofilm-titel (accessor kinofilm :titel))
#’user/kinofilm-titel
user> (kinofilm-titel
(struct-map kinofilm
:titel "Der Herr der Ringe I"
:jahr 2001))
"Der Herr der Ringe I"
Andere Funktionen in diesem Zusammenhang sind die hinter dem leicht
verdaulichen Makro defstruct arbeitende, grundlegende Funktion create-struct zur
Definition einer StructMap und der Befehl struct, dessen Aufruf struct-map ähnelt, wobei
aber die Schlüssel weggelassen werden und die Zuordnung durch die Reihenfolge der
Argumente gegeben wird. In der Regel ist diese Form etwas schwieriger lesbar, wenn die
Strukturdefinition nicht direkt neben der Verwendung steht. Zudem lassen sich so keine
weiteren Werte hinzufügen.
user> (def musikstueck (create-struct :titel :interpret))
#’user/musikstueck
user> (struct musikstueck "Schism" "Tool")
{:titel "Schism", :interpret "Tool"}
user> (struct musikstueck "Schism" "Tool" :jahr 2001)
java.lang.IllegalArgumentException:
Too many arguments to struct constructor
StructMaps, Records und TypenStructMaps legen einen Satz von Membervariablen fest. Das Resultat ist einer Java-Bean nicht unähnlich. Seit Clojure 1.2 existieren mit
defrecord und
deftype neue Methoden, ein ähnliches Ziel zu erreichen. Es ist zu vermuten, dass deren Verwendung die StructMaps im Laufe der Zeit ablösen wird.
Mit den ArrayMaps, die mit dem Befehl array-map angelegt werden, existiert eine weitere
Spezialform der Map, bei der die Reihenfolge der Schlüssel sichergestellt ist. Allerdings haben
diese ArrayMaps aufgrund ihrer Implementation als ein Array der Form Schlüssel1 Wert1
Schluessel2 Wert2 … eine lineare Zugriffscharakteristik, so dass sie sich nur für kleine
Datenmengen eignen. Zudem ist die Reihenfolge nur nach ihrer Erzeugung sichergestellt.
Sobald ein neues Schlüssel-Wert-Paar hinzugefügt wird, kann es sein, dass Clojure den Typ auf
eine normale Hash-Map setzen wird. Aufgrund dieser Beschränkungen fristen ArrayMaps eher
ein Schattendasein.
user> {:z 26 :a 1 :e 5 :g 7 :b 2
:c 3 :d 4 :f 6 :hupps "Unsortiert"}
{:hupps "Unsortiert", :z 26, :a 1, :c 3,
:b 2, :f 6, :g 7, :d 4, :e 5}
user> (array-map :z 26 :a 1 :e 5 :g 7 :b 2
:c 3 :d 4 :f 6
:hupps "Unsortiert")
{:z 26, :a 1, :e 5, :g 7, :b 2, :c 3,
:d 4, :f 6, :hupps "Unsortiert"}
Nachdem nun die grundlegenden, datentragenden und unveränderlichen Datentypen eingeführt
sind, ist es an der Zeit, ihre Verwendung in Variablen, die bis hierher nur in der Form des
Befehls def aufgetaucht ist, genauer zu betrachten.
Wer in Clojure eine Variable anlegt und mit einem Wert versieht, erzeugt das Symbol für
die Variable und den Wert unabhängig voneinander. In Lisp-Lingo wird die Variable an den
Wert gebunden. Der englische Begriff „Binding“ wird als „Bindung“ oder sperriger,
dafür korrekter, als „Variablenbindung“ übersetzt. Da sich der englische Begriff
auch unter deutschsprachigen Lisp-Programmierern durchgesetzt hat, verwenden
wir alle Formen gleichberechtigt. Jede dieser Variablen gilt zunächst nur in einem
Namensraum.
Clojure bietet jenseits der unveränderlichen Datentypen veränderliche Referenztypen an, deren
Motivation sich in den meisten Fällen aus den Anforderungen des Concurrent Programming
ergibt. Daher erscheint ein entsprechender Abschnitt (3.4) auch im Kapitel über Concurrency
(Kap. 3). Einer der Referenztypen jedoch spielt eine etwas andere Rolle und soll hier
beschrieben werden. Die Rede ist vom Typ Var.
Vars sind globale Variablen, die aus jedem Geltungsbereich angesprochen
werden. Sie werden mit def angelegt, in dessen Aufruf ein Symbol verwendet wird, um den
Namen der Var festzulegen. Damit gelten für Vars die im Abschnitt über Symbole
(2.6.5) beschriebenen Namensregeln. BindingEine Var kann an einen Wert (wie einen
Text, eine Zahl oder eine Datenstruktur) gebunden sein; zum Beispiel dadurch, dass
beim Aufruf von def ein Initialwert, das sogenannte „Root-Binding“, mitgegeben
wird.
Lokale Veränderungen pro Thread
Jeder neue Thread erbt diese Assoziation, kann sie aber lokal
überschreiben, ohne dass andere Threads davon betroffen wären. Auch Funktionen werden mit
Vars assoziiert und können so überschrieben werden.
Vars sind veränderliche Elemente in Clojure und unterscheiden sich damit von Daten wie
Strings, Zahlen oder Maps. Ein erneuter Aufruf einer Var-Definition wird das neue
Root-Binding etablieren, was für die interaktive Entwicklung notwendig ist. Dieses dynamische
Verhalten erklärt der Abschnitt 2.7.4.
Die auch aus anderen Programmiersprachen bekannten Namensräume – engl. „Namespaces“ –
bieten einen Mechanismus, die verfügbaren Namen für Variablen und Funktionen zu gliedern,
so dass Bibliotheken keine Rücksicht aufeinander nehmen müssen, wenn sie ihre Namen
vergeben. In diesem Buch verwenden wir die deutsche Form „Namensraum“ und die englische
Variante „Namespace“, fast gleichwertig. Bei Verwendung der englischen Form ist in der Regel
eher der Typ Namespace gemeint.
In Clojure nehmen Namespaces eine Zuordnung von Symbolen zu Vars oder
Java-Klassen vor. Dabei sind die Symbole nicht vollständig mit dem Namen ihrer Bibliothek
qualifiziert. Namespaces sind in Clojure auch ein Datentyp, wie im folgenden Beispiel anhand
der Variablen *ns*, die jederzeit auf den aktuellen Namespace verweist, gezeigt
wird.
user> *ns*
#<Namespace user>
user> (type *ns*)
clojure.lang.Namespace
user> (use ’clojure.repl)
nil
user> (in-ns ’clojure.repl)
#<Namespace clojure.repl>
clojure.repl> *ns*
#<Namespace clojure.repl>
clojure.repl> (type *ns*)
clojure.lang.Namespace
clojure.repl=> (in-ns ’user)
#<Namespace user>
Mit dem Befehl in-ns wurde zwischenzeitlich in einen anderen
Namensraum gewechselt, was am REPL-Prompt auch sichtbar wird. Namespaces können mit
der Funktion create-ns erzeugt werden. Allerdings ist es sehr viel gebräuchlicher,
das Makro ns am Beginn einer Clojure-Datei zu verwenden, da es ebenfalls einen
Namespace erzeugt und auch gleich hineinwechselt. Auf diese Weise werden die
folgenden Definitionen in der Datei im korrekten Namensraum durchgeführt. Den
Wechsel in einen anderen Namensraum mit in-ns wird man meist an der REPL
durchführen.
Die Implementation der Bibliothek clojure.contrib.json definiert den eigenen
Namespace wie folgt:
(ns #^{:author "Stuart Sierra"
:doc "JavaScript Object Notation (JSON) parser/writer.
See http://www.json.org/
To write JSON, use json-str, write-json, or write-json.
To read JSON, use read-json."}
clojure.contrib.json
(:use [clojure.contrib.pprint :only (write formatter-out)]
[clojure.contrib.string :only (as-str)])
(:import (java.io PrintWriter PushbackReader StringWriter
StringReader Reader EOFException)))
Diese Definition ist durchaus typisch und zeigt, wie zunächst mit Hilfe
von Metadaten, die in Abschnitt 2.15 beschrieben werden, die Autoren und eine
kurze Dokumentation angegeben werden, worauf der Name des neuen Namespace
folgt. Nur am Rande sei erwähnt, dass diese Definition die noch gültige Syntax
für Metadaten – #^ – verwendet, die als veraltet gilt. Das Schlüsselwort :import
sorgt für den Import einiger Klassen aus Javas Standardbibliothek in den aktuellen
Namensraum, wodurch diese ohne vollständig qualifizierten Namen referenziert werden
können. Im Gegensatz zu Java entfällt die ständige Wiederholung immer gleicher
Pfade, und die Importe sind gruppiert. Allerdings lassen sich nicht alle Klassen
durch Angabe eines Sterns importieren. Dieser Import, der im Hintergrund das
Makro import aufruft, legt die passenden Symbole in diesem Namespace an, die
den Zugriff auf die genannten Java-Klassen erlauben. Ganz ähnlich funktioniert
:use, das mit Hilfe von use Clojure-Bibliotheken in den aktuellen Namensraum
importiert. Siehe dazu auch den Abschnitt 2.18.1. Das Schlüsselwort :only sorgt dafür,
dass nur die angegebenen Symbole in den neu definierten Namensraum importiert
werden.
Namespaces verhalten sich zur Laufzeit dynamisch, sie können
erzeugt und manipuliert werden, sie können auch gelöscht werden. Zusätzlich existieren
Funktionen, um einen Namespace zu untersuchen, zum Beispiel um zu ermitteln, welche
Java-Imports bekannt sind.
Zudem lassen sich Zuordnungen von Symbolen zu Vars auch dynamisch zur Laufzeit
anlegen. Dazu dient der Befehl intern. Beispielsweise könnte man eine Liste von Vars mit
gleichartigen Namen, denen nur ein Zähler angehängt wird, auf die folgende Weise
erzeugen:
user> (dotimes [i 2]
(intern *ns* (symbol (str "prefix" (inc i)))
(str "Original " (inc i))))
nil
user> prefix1
"Original 1"
user> prefix2
"Original 2"
Hier erzeugt Clojure in einer durch dotimes eingeleiteten Schleife die Symbole für die
Namen der Vars sowie die Root-Bindings dynamisch. Diese Art der Erzeugung von
Vars ist eher für den fortgeschrittenen Gebrauch. Gerade im Zusammenhang mit
Makros, die in Abschnitt 2.12.3 beschrieben werden, kann dieses Konstrukt unter
Umständen brauchbar sein. Die Funktion intern erzeugt eine Var im übergebenen
Namespace, deren Namen durch ein Symbol und deren Root-Binding zusätzlich angegeben
werden:
Wenn die Var schon existiert, wird sie weiter verwendet. Den Namensraum bezieht der obige
Aufruf direkt aus der Variablen *ns*. Das Symbol für die Benennung der Var erzeugt im
Beispiel die Kombination von symbol und str bei Verwendung der Lauf-Variablen von
dotimes, i.
Lokale Variablenbindungen entstehen automatisch in Funktionsdefinitionen oder aber explizit
bei Verwendung der speziellen Operatoren let und loop.
Im Falle einer Funktion, die Argumente übergeben bekommt, erzeugt
Clojure lokal gültige Variablenbindungen und verwendet dabei die Namen aus der
Argumentenliste.
(defn fn-mit-bindings [arg1 arg2]
(println "Lokales Binding arg1 " arg1)
(println "Lokales Binding arg2 " arg2))
user> (fn-mit-bindings 1 2)
Lokales Binding arg1 1
Lokales Binding arg2 2
nil
user> (fn-mit-bindings "Eins" "Zwei")
Lokales Binding arg1 Eins
Lokales Binding arg2 Zwei
nil
Einelet weitere Standardmethode, lokale Bindings zu erzeugen, ist der Operator let. Dieser
hat die Form
oder etwas anschaulicher
(let [bind-name-1 bind-val-1
;; ...
bind-name-n bind-val-n]
(eine-fn bind-name-1)
(eine-andere-fn bind-name-1 bind-name-n))
Mit let werden lokale Variablen erzeugt, auf die im Rest des let-Ausdrucks lesend
zugegriffen werden kann. Die ist hier veranschaulicht durch die Verwendung von bind-name-1
und bind-name-n als Argumente für zwei anderweitig definierte Funktionen. Sobald sich aber
die letzte Klammer dieses Ausdrucks schließt, verschwinden die Variablen aus dem
Zugriffsbereich. Auch hierzu ein einfaches Beispiel:
(defn quadrat-mit-ausgabe [x]
(let [resultat (* x x )]
(println "Quadrat von" x "ist" resultat)
resultat))
user> (quadrat-mit-ausgabe 2)
Quadrat von 2 ist 4
4
user> (quadrat-mit-ausgabe 100)
Quadrat von 100 ist 10000
10000
user> resultat
java.lang.Exception:
Unable to resolve symbol: resultat in this context
In diesem Beispiel kommen beide beschriebenen Mechanismen der Variablenbindung zum
Einsatz. Die Funktion quadrat-mit-ausgabe erzeugt zunächst ein lokales Binding mit Namen
x für das übergebene Argument (in den beiden folgenden Aufrufen sind das die Zahlen 2 und
100) und danach mit let einen lokalen Zwischenspeicher mit dem berechneten Resultat. Der
letzte Ausdruck im Funktionsrumpf von let bestimmt den Rückgabewert des gesamten
let-Ausdrucks. Im Beispiel ist das einfach der Wert des lokalen Bindings resultat. Dass
resultat nur einen lokalen Geltungsbereich hat, zeigt die aufgetretene Exception bei dem
Versuch, außerhalb der Funktionsdefinition, hier direkt am REPL-Prompt, auf dieses Binding
zuzugreifen.
In den Ausdrücken, die die Variablenbindungen definieren, kann auf zuvor bereits
gebundene Variablen zugegriffen werden, es besteht somit keine Notwendigkeit, mehrere
Aufrufe von let ineinander zu verschachteln. Dieses Verhalten entspricht in Common Lisp
dem Operator let*.
(defn quad-sum [x y]
(let [sum (+ x x)
qua (* sum sum)]
(println "Summe ist" sum)
(println "Quadrat davon ist" qua)
qua))
user> (quad-sum 2 3)
Summe ist 4
Quadrat davon ist 16
16
Vars haben einen globalen Geltungsbereich, und der Wert, an den sie gebunden
sind, wird bei Bedarf dynamisch ermittelt. Darin unterscheiden sie sich von lokalen
Variablenbindungen, deren Geltungsbereich durch die lexikalische Umgebung definiert
wird.
Die dynamische Ermittlung des Werts ermöglicht ein Konstrukt, bei dem
das Verhalten einer Funktion von einer globalen Variablen abhängt, die dann kurzzeitig
umgeschrieben wird. Das erlaubt die Kommunikation zwischen aufrufender und aufgerufener
Funktion für diejenigen Fälle, die keine Erweiterung der Argumentenliste rechtfertigen. Solche
Funktionen sind andererseits nicht mehr als funktional zu betrachten, da sie von äußeren
Verhältnissen abhängen. Weil diese dynamischen Variablenbindungen eine Stack-Semantik an
den Tag legen, sind sie sicherer in ihrer Verwendung als globale Variablen, wie man sie
beispielsweise aus C kennt: Es ist nicht möglich, das Zurücksetzen auf das Root-Binding zu
vergessen. Da auch Funktionen in Vars gespeichert sind, können auch sie bei Bedarf zeitweilig
umgeschrieben werden.
Wann immer auf eine Variable, egal ob lokal oder dynamisch gebunden, zugegriffen wird,
findet die Ermittlung des Werts statt. Dynamische Variablen können mit Hilfe von binding
für einen Programmabschnitt an einen neuen Wert gebunden werden.
Das folgende Beispiel legt eine globale Var *wert* an und zeigt die Möglichkeiten,
diese dynamisch mit let und binding zu überschreiben.
(def *wert* "Root-Binding")
(defn fn1 []
(println "Wert in FN1:" *wert*))
(defn fn2 []
(println "Am Anfang von FN2:" *wert*)
(let [*wert* "LET in FN2"]
(println "Im LET von FN2:" *wert*)
(fn1)))
(defn fn3 []
(println "Am Anfang von FN3:" *wert*)
(binding [*wert* "GEBUNDEN FN3"]
(println "Im BINDING von FN3:" *wert*)
(fn1)))
user> (fn1)
Wert in FN1: Root-Binding
nil
user> (fn2)
Am Anfang von FN2: Root-Binding
Im LET von FN2: LET in FN2
Wert in FN1: Root-Binding
nil
user> (fn3)
Am Anfang von FN3: Root-Binding
Im BINDING von FN3: GEBUNDEN FN3
Wert in FN1: GEBUNDEN FN3
nil
Entscheidend ist hier das Verhalten in der Funktion fn1. Wurde die Variablenbindung von
*wert* lokal mit let überschrieben, sieht diese Funktion das nicht. Wurde die Bindung aber
mit binding umgeschrieben, verwenden auch aus diesem Kontext aufgerufene Funktionen den
neuen Wert.
Etwas verwirrend wird es, wenn sowohl let als auch binding zum Einsatz
kommen, wie die Funktion fn4 im nächsten Beispiel zeigt.
(defn fn4 []
(println "Am Anfang von FN4:" *wert*)
(let [*wert* "Lokal in FN4"]
(println "Im LET von FN4:" *wert*)
(fn1)
(binding [*wert* "GEBUNDEN in FN4"]
(println "Huch! Im BINDING von FN4:" *wert*)
(fn1))))
user> (fn4)
Am Anfang von FN4: Root-Binding
Im LET von FN4: Lokal in FN4
Wert in FN1: Root-Binding
Huch! Im BINDING von FN4: Lokal in FN4
Wert in FN1: GEBUNDEN in FN4
nil
Hier tritt die Reihenfolge der Auflösungsregeln für Symbole zutage, in der lokale Bindungen
jederzeit Vorrang vor globalen haben (siehe Abschnitt 2.18.3).
Die Verwendung von binding birgt noch eine weitere Gefahr, wenn Lazy
Sequences (vgl. Abschnitt 2.16) im Spiel sind. In solchen Fällen muss genau überlegt
werden, was zu welcher Zeit evaluiert wird und welches Binding in dem Moment gilt.
Das ist der Preis für das Verlassen des relativ sicheren Bereichs der funktionalen
Programmierung.
Wichtig ist auch das Verhalten von Vars und ihren dynamischen Bindungen im
Zusammenhang mit Threads. Alle Threads erben das Root-Binding – sofern vorhanden –,
und ein Überschreiben mit binding erzeugt die neue Variablenbindung nur lokal im Thread,
die anderen Threads sehen diese Änderung nicht.
(defn thread1 []
(println "Thread1-Root:" *wert*)
(binding [*wert* "Lokal-In-Thread1"]
(println "Thread1 binding vor sleep:" *wert*)
(flush)
(Thread/sleep 2000)
(println "Thread1 binding nach sleep:" *wert*)))
(defn thread2 []
(Thread/sleep 1000)
(println "Thread2-Root:" *wert*)
(binding [*wert* "Lokal-In-Thread2"]
(println "Thread2 binding: " *wert*)))
user> (do
(.start (Thread. thread1))
(.start (Thread. thread2)))
Thread1-Root: Root-Binding
Thread1 binding vor sleep: Lokal-In-Thread1
Thread2-Root: Root-Binding
Thread2 binding: Lokal-In-Thread2
Thread1 binding nach sleep: Lokal-In-Thread1
nil
Dieses Beispiel verlangt ein wenig mehr Erklärung. Zunächst wird eine Backend-Funktion
mit Namen thread1 definiert. In ihr gibt println den Inhalt von *wert* aus. Da
diese Funktion später in einem neuen Thread aufgerufen werden wird, ist das das
Root-Binding. Danach bindet thread1 mit binding die globale Var um, so dass
anhand des neuen Wertes erkennbar ist, von wo sie gebunden wurde. Mit flush wird
der Ausgabepuffer geleert und mit Thread/sleep zwei Sekunden gewartet. Nach
dem Schlafen gibt diese Funktion erneut ihr aktuelles Binding aus und beendet sich
danach.
Die zweite Funktion mit Namen thread2 schläft erst, gibt dann das aktuelle Root-Binding
aus, bindet die Var dynamisch neu und gibt den Wert aus. Die Sleep-Befehle sind so
aufeinander abgestimmt, dass die Ausgabe am Ende erkennen lässt, dass die neue Bindung im
ersten Thread keinen Einfluss auf den zweiten Thread hat. Starten von ThreadsMit
dem abschließenden do direkt an der REPL werden zwei Threads gestartet, die
jeweils eine der beiden Backend-Funktionen starten. Auch an dieser Stelle greift
der Clojure-Code direkt auf Java-Funktionen zurück (siehe auch den einleitenden
Abschnitt 2.5). Alle Clojure-Funktionen – also auch thread1 – implementieren
Runnable und können somit an einen Thread übergeben werden. Mit Thread. wird eine
neue Thread-Instanz erzeugt, die dann durch den Methodenaufruf start gestartet
wird.
Neuer Thread immer Root-Binding
Die Ausgabe zeigt, dass die Bindung des ersten Threads im
zweiten nicht sichtbar ist. Neue Threads erben immer wieder das Root-Binding,
auch wenn schon eine neue Variablenbindung aktiv ist, wie das folgende Beispiel
demonstriert.
(def *die-var* 23)
(defn println-die-var [thrnam]
(println thrnam *die-var*))
user> (let [*die-var* 42]
(println-die-var "REPL-Thread")
(.start (Thread.
#(println-die-var "LET-Thread")))
(Thread/sleep 10)
(binding [*die-var* 5]
(println-die-var "REPL-Thread(wieder)")
(.start (Thread.
#(println-die-var
"BINDING-Thread")))
(Thread/sleep 10)))
REPL-Thread 23
LET-Thread 23
REPL-Thread(wieder) 5
BINDING-Thread 23
nil
Es existieren mit alter-var-root und set! noch weitere Methoden, um die Bindung einer
Var zu manipulieren. Sie werden jedoch eher selten verwendet.
Clojures Binding-Ausdrücke (engl. „binding forms“) haben die interessante Eigenschaft, nicht
nur einfache Wertzuweisungen vornehmen zu können, sondern auch im Zuge der Zuweisung
bereits komplexe Datenstrukturen auseinandernehmen zu können. Dieser Vorgang
wird in der Lisp-Welt gemeinhin als „destructuring bind“ bezeichnet. Uns ist keine
gebräuchliche deutsche Übersetzung bekannt; in diesem Buch verwenden wir „zerlegende
Variablenbindung“. Zerlegende Variablenbindungen sind fast überall dort möglich, wo
lexikalische Variablenbindungen angelegt werden: bei der Übergabe von Parametern bei
Funktionen, in den Bindungsdefinitionen von let sowie bei loop. Da Makrodefinitionen mit
defmacro letztlich auch auf fn zurückgeführt werden, kann auch hier die zerlegende
Variablenbindung zum Einsatz kommen.
Im einfachsten Falle lassen sich durch die zerlegende Variablenbindung Werte eines
Vektors direkt an Variablen binden, ohne die Struktur zunächst selbst zu speichern und dann
auf ihre Elemente zuzugreifen. Im folgenden Beispiel werden die lokalen Namen aus
dem ersten Vektor (a, b und c) an die Werte aus dem zweiten Vektor (1, 2 und 3)
gebunden.
user> (let [[a b c] [1 2 3]]
(str "A: " a " B: " b " C: " c))
"A: 1 B: 2 C: 3"
Wie nicht anders zu erwarten, erlaubt Clojure, dass diese zerlegenden Bindungen
auch geschachtelt werden.
user> (let [[a b [c d e]] [1 2 [3 4 5]]]
(list a b (list c d e)))
(1 2 (3 4 5))
user> (let [[a b [c d e]] [1 2 [3 4 5]]]
(list a b c d e))
(1 2 3 4 5)
Auf der Datenseite muss nicht notwendig ein Vektor stehen. Jede Datenstruktur, die die
Funktion nth unterstützt, ist hier erlaubt:
user> (let [[a b c] [1 2 3]]
(list a b c))
(1 2 3)
user> (let [[a b c] ’(1 2 3)]
(list a b c))
(1 2 3)
user> (let [[a b c] "123"]
(list a b c))
(\1 \2 \3)
user> (let [[a b c] {:x 1 :y 2 :z 3}]
(list a b c))
java.lang.UnsupportedOperationException:
nth not supported on this type: PersistentArrayMap
Im letzten Beispiel wird eine Map verwendet, und diese unterstützt die Funktion nth nicht,
wie die Exception verdeutlicht. Aber auch assoziative Typen erhalten ihre Unterstützung von
Clojures Bindungsmaschine mit einer Syntax, die den Zugriff auf Werte anhand ihrer
Schlüssel, gleich welcher Art, erlaubt.
user> (let [{a :x, b :y, c :z} {:x 1 :y 2 :z 3}]
(list a b c))
(1 2 3)
user> (let [{a "x", b "y", c "z"}
{"x" 1 "y" 2 "z" 3}]
(list a b c))
(1 2 3)
Hier findet sich auf der „linken“ Seite – im Sinne von L-Values anderer Sprachen – eine
Map, die pro Element einerseits den lokal zu verwendenden Namen (a, b, c) und
andererseits den Schlüssel, der zum Extrahieren verwendet werden soll, enthält. Im ersten
Aufruf sind diese Schlüssel :x, :y und :z, im zweiten Aufruf sind es die Strings „x“,
„y“ und „z“. Zur besseren Übersicht sind die Elemente mit Kommas voneinander
getrennt.
Häufig wird der Programmierer für die Elemente einer Map als lokale
Bindings direkt die Namen der Schlüssel verwenden wollen. Dafür stellt Clojure in seinen
Binding-Regeln eine Kurzform bereit, die das Schlüsselwort „:keys“ verwendet. Nach diesem
Schlüsselwort folgt ein Vektor mit den Namen der Schlüssel in der Map, wobei den Namen
kein Doppelpunkt vorangestellt ist. Diese Namen können dann ohne Umschweife im
lokalen Kontext verwendet werden. Es ist zu beachten, dass diese Abkürzung nur
dann verwendet werden kann, wenn als Schlüssel in der Map Keywords verwendet
werden.
user> (let [{:keys [x y z]} {:w 0 :x 1 :y 2 :z 3}]
(list x y z))
(1 2 3)
user> (let [{:keys ["x" "y" "z"]}
{"x" 1 "y" 2 "z" 3}]
(list x y z))
java.lang.Exception: Unsupported binding form: z
Um den produzierten Fehler zu beheben, bei dem als Schlüssel keine Keywords,
sondern Strings verwendet werden, dient ein weiteres Schlüsselwort: :strs. Der letzte häufige
Fall, dass Symbole als Schlüssel in einer Map zum Einsatz kommen, wird ebenfalls durch ein
separates Schlüsselwort syms unterstützt.
user> (let [{:strs [x y z]} {"x" 1 "y" 2 "z" 3}]
(list x y z))
(1 2 3)
user> (let [{:syms [x y z]} {’x 1 ’y 2 ’z 3}]
(list x y z))
(1 2 3)
Neben der Extraktion von einzelnen Werten aus einer Datenstruktur kann auch
die gesamte Datenstruktur lokal gebunden werden. Dazu wird „:as“ verwendet und bekommt
den lokalen Namen übergeben.
user> (let [{a :x, b :y, c :z, :as xyz-map}
{:x 1 :y 2 :z 3}]
(list a b c xyz-map))
(1 2 3 {:x 1, :y 2, :z 3})
Auf diese Weise lassen sich einzelne Werte gezielt extrahieren. Beispielsweise, da ihr
Vorhandensein im jeweiligen Fall garantiert ist. Die komplette Liste bleibt aber zur
Untersuchung weiterer Fälle ebenfalls erhalten, ohne dass sie ein zweites Mal übergeben
werden muss.
Ähnlich zu :as ist das Verhalten, wenn in der Binding-Form ein kaufmännisches
Und („&“) auftaucht. In diesem Falle wird der Rest der Liste, der noch nicht explizit lokal
zugewiesen wurde, mit dem lokalen Namen, der nach dem Und folgt, gebunden.
user> (let [[a b c & mehr] [1 2 3 4 5 6]]
(list a b c mehr))
(1 2 3 (4 5 6))
Die letzte Funktionalität, die Clojure in seinen Binding-Forms durch das
Schlüsselwort :or erlaubt, ist die Zuweisung von Defaultwerten, wenn eine Extraktion kein
Ergebnis liefern konnte.
user> (let [{x :x, y :y :or {x 100, y 102}}
{:x 10}]
(list x y))
(10 102)
Dabei werden in der Map, die die Defaultwerte angibt, die lokalen Namen verwendet.
Alle bis hierher vorgestellten Varianten der zerlegenden Variablenbindung
verlangen, dass beim Aufruf einer Funktion, die ihre Argumente zerlegt, eine Datenstruktur –
sei es nun ein Vektor oder eine Map oder etwas Ähnliches – übergeben werden muss.
Sogenannte Keyword-Argumente, wie sie beispielsweise aus Common Lisp bekannt sind, waren
bis Version 1.2 von Clojure nicht möglich. Mittlerweile lassen sich aber im flexiblen Bereich
nach dem kaufmännischen Und auch Schlüsselwörter definieren, die dann direkt im
Funktionsaufruf verwendet werden. Die Verwendung nach dem & erhält die Semantik, dass
dort eine Listenstruktur erwartet wird. Diese kann somit separat auseinandergenommen
werden.
(defn schluessel [haus auto & {:keys [garage rad]}]
(list haus auto garage rad))
user> (schluessel "nr1" "nr2")
("nr1" "nr2" nil nil)
user> (schluessel "nr1" "nr2" :garage "der rote")
("nr1" "nr2" "der rote" nil)
Bei der hier demonstrierten gemischten Verwendung von positionalen und
Keyword-Parametern ist beim Aufruf sicherzustellen, dass die positionalen zuerst gefüllt
werden. Die Keyword-Parameter werden nach den Positionsparametern ausgewertet. Das
folgende Beispiel zeigt einen solchen Fehler.
user> (schluessel :garage "der rote" "nr1" "nr2" )
(:garage "der rote" nil nil)
Offensichtlich ist es auch möglich, Funktionen zu definieren, die ausschließlich Parameter in
Form von Schlüsselwörtern entgegennehmen. Diese akzeptieren dann keine positionalen
Parameter mehr.
(defn nur-schluessel [& {:keys [haus auto garage rad]}]
(list haus auto garage rad))
user> (nur-schluessel :haus "No. 9" :rad "klein" :auto "funk")
("No. 9" "funk" nil "klein")
user> (nur-schluessel "ja, wo ist er denn?")
java.lang.IllegalArgumentException:
No value supplied for key: ja, wo ist er denn?
Zerlegende Variablenbindung erleichtert, gut eingesetzt, die Lesbarkeit und vermeidet
triviale Zuweisungen in größeren Mengen. Die vielen verschiedenen Formen, vor allem jene, die
selten auftauchen, sind jedoch nicht immer selbsterklärend und bedürfen oft genauer
Untersuchung, bevor sie verstanden werden können. Gerade Einsteiger sind gut beraten, diese
Funktionen wohlbedacht zu verwenden.
Clojure bietet eine Reihe von Funktionen für die Ausgabe aus einem Programm, die sich oft
nur im Detail unterscheiden. Diese lassen sich grob in zwei Gruppen aufteilen: Funktionen
zur Ausgabe für Menschen und Funktionen für die maschinenlesbare Ausgabe. Für
wiederkehrende Muster wird mit Hilfe von passenden Makros eine Vereinfachung
erzielt.
Bevor die einzelnen Funktionen vorgestellt werden, muss die Frage beantwortet
werden, wohin die Ausgabe erfolgt. In Abschnitt 2.7.4 wurde die dynamische
Variablenbindung erläutert und als ein Verwendungszweck die Kommunikation von
Funktionen an der Argumentenliste vorbei beschrieben. Clojure hält die bekannten
Standardkanäle eines Programms – die Standardeingabe, -ausgabe und Fehlerausgabe – in
globalen Vars vor: *out*, *in* und *err*. Diese sind normalerweise an das Terminal
gebunden, in dem die REPL-Sitzung läuft. Integrierte Lösungen in IDEs binden sie
hingegen an andere Streams und ermöglichen so die Kommunikation der REPL mit
der IDE. Dieser Abschnitt beschreibt anhand der Var *out*, wie Funktionen, die
primär zur Ausgabe dienen, auch für die Erzeugung von Strings verwendet werden
können.
Die Var *out* muss an einen java.io.Writer gebunden sein, an den dann alle Ausgaben
gesendet werden. Die REPL von Clojure tut genau das:
user> *out*
#<OutputStreamWriter java.io.OutputStreamWriter@81b1fb>
Die einfachste Form der Ausgabe erfolgt mit der Funktion print, die ihre
Argumente mit Leerzeichen voneinander getrennt nach *out* schreibt. Die bereits mehrfach
verwendete Funktion println funktioniert genauso; sie hängt lediglich am Ende noch einen
Zeilenumbruch an, was die Ausgabe lesbarer macht. Beide Funktionen sind für Ausgaben
gedacht, die der Kommunikation mit Anwendern und Programmierern dienen. Da es bei diesen
Funktionen explizit um den Nebeneffekt der Ausgabe geht, liefern sie konsequenterweise nil
zurück.
user> (print "Hallo Welt")
Hallo Weltnil
user> (println "Hallo Welt")
Hallo Welt
nil
Clojures Datentypen haben in den meisten Fällen eine eigene Read-Syntax.
Das ist sehr praktisch, wenn man beispielsweise schnell und ohne großen Aufwand Daten
persistieren muss. Dazu muss ein Programm lediglich *out* an eine passende Datei
binden und die Funktionen pr oder prn aufrufen, die sich wie schon print und
println durch den abschließenden Zeilenumbruch unterscheiden. Im Gegensatz zu
diesen sind sie aber nicht für Menschen, sondern für Clojure gedacht. Ihre Ausgabe
lässt sich wieder einlesen, sofern es um Datenstrukturen geht, für die Clojure eine
Read-Syntax kennt. Dieser Unterschied lässt sich bereits am einfachen Hallo-Welt-Beispiel
erkennen.
user> (pr "Hallo Welt")
"Hallo Welt"nil
user> (prn "Hallo Welt")
"Hallo Welt"
nil
Im Gegensatz zu print werden hier die Anführungszeichen mit ausgegeben, so
dass ein wieder einlesbarer String entsteht. Diese beiden Funktionen lassen sich in
ihrem Verhalten durch dynamisches Binden von *print-readably* beeinflussen. Ist
diese Variable auf nil gesetzt, werden sie sich genauso verhalten wie print und
println.
Für die formatierte Ausgabe kann die Funktion printf verwendet werden,
die im Hintergrund format für die Formatierung aufruft und dann das Ergebnis ausgibt. Die
Funktionalität wird dabei vollständig von String.format bereitgestellt, sie ist also
Java-Programmierern bekannt. Programmierer mit einem Common-Lisp-Hintergrund finden
ihre Variante von format unter dem Namen cl-format im Namespace clojure.pprint, der
seit Version 1.2 zum Sprachstandard von Clojure gehört.
Das folgende Beispiel erstellt zunächst einen Vektor mit verschiedenen durch format
erzeugten Texten und wendet danach die Funktion println mit Hilfe von doseq auf alle
Elemente des Vektors f-strings an, um den gewünschten Nebeneffekt der Ausgabe zu
erzielen. Zudem ist zu beachten, dass String.format Clojures Datentyp Ratio nicht kennt.
Dieser verfügt jedoch über eine toString-Methode, so dass die Formatierung mit %s gewählt
werden kann.
user> (let [f-strings
[(format "Die wilde %d" 13)
(format "Die %s 13" "wilde")
(format "König Alfons der %s vor %d-te"
1/4 12)]]
(doseq [fs f-strings]
(println fs)))
Die wilde 13
Die wilde 13
König Alfons der 1/4 vor 12-te
nil
Bislang haben die Ausgaben stets auf der REPL-Konsole stattgefunden. Wenn sie
umgelenkt werden sollen, muss die Var *out* passend neu gebunden werden. Aus der
Java-Welt, auf die aus Clojure stets direkter Zugriff besteht, bietet sich dafür die
Verwendung der Klasse java.io.StringWriter an. Im nächsten Beispiel wird eine ebensolche
Instanz erzeugt, auf der die toString-Methode aufgerufen wird. Dem explorativen
Charakter der REPL folgend, erledigt dieses Beispiel die notwendigen Schritte langsam
nacheinander.
user> (def jiosw (java.io.StringWriter.))
#’user/jiosw
user> (binding [*out* jiosw]
(print "Hallo Welt"))
nil
user> (.toString jiosw)
"Hallo Welt"
user> (str jiosw)
"Hallo Welt"
Der erste Befehl speichert in der Var mit Namen jiosw eine neue Instanz von
java.io.StringWriter. Im zweiten Befehl erhält *out* kurzzeitig eine neue Variablenbindung an
die soeben erzeugte Var, und print wird mit dieser Bindung aufgerufen. Auf der
REPL-Konsole erfolgt keine Ausgabe. Danach stellt sich die Frage, wie der nun im
StringWriter gespeicherte String ausgelesen werden kann. Die Antwort gibt die
toString-Methode, die auf jiosw aufgerufen wird. Dafür existiert mit der Clojure-Funktion
str eine kürzere Form. Selbstverständlich lassen sich diese Schritte auch zu einem Ausdruck
zusammenfassen:
user> (let [sw (java.io.StringWriter.)]
(binding [*out* sw]
(print "Hallo Welt"))
(str sw))
"Hallo Welt"
Diese Lösung wird häufig genug gebraucht, dass ein eigenes Makro bereits
von Clojure mitgeliefert wird: with-out-string.
user> (with-out-str
(print "Hallo Welt"))
"Hallo Welt"
Damit nicht genug. Für die Funktionen print, println, pr und prn existieren
bereits vordefinierte Funktionen, die das Idiom der Verwendung von with-out-str
beinhalten: print-str, println-str, pr-str und prn-str.
user> (let [strg (print-str "Hallo Welt")]
(printf "strg enthält: >%s<" strg))
strg enthält: >Hallo Welt<nil
user> (let [strg (println-str "Hallo Welt")]
(printf "strg enthält: >%s<" strg))
strg enthält: >Hallo Welt
<nil
user> (let [strg (prn-str "Hallo Welt")]
(printf "strg enthält: >%s<" strg))
strg enthält: >"Hallo Welt"
<nil
user> (let [strg (pr-str "Hallo Welt")]
(printf "strg enthält: >%s<" strg))
strg enthält: >"Hallo Welt"<nil
Diese Beispiele unterscheiden sich nur in den kleinen Details der Zeilenumbrüche und
Anführungszeichen, zudem verwenden sie nicht direkt die zu demonstrierenden Funktionen, da
die REPL sonst den zurückgegebenen String direkt ausgeben würde, so dass der Unterschied
zu den Funktionen ohne -str nicht erkennbar wäre.
Beim Vergleichen von Dingen muss man sich Gedanken machen, was man vergleichen will. Bei
zwei ganzen Zahlen ist das noch relativ einfach. Die Zahlen 1 und 2 sind verschieden, Gleiches
gilt auch für Variablen, die diese Zahlen enthalten:
user> (= 1 2)
false
user> (def eins 1)
#’user/eins
user> (def zwei 2)
#’user/zwei
user> (= eins zwei)
false
Bei Gleitkommazahlen wird es durch die binäre Repräsentation im Speicher in
manchen Fällen schon schwierig. Eine Berechnung mit Gleitkommawerten, gefolgt
von einem Vergleich mit einer ganzen Zahl, muss nicht immer funktionieren. Noch
schwieriger stellt sich die Situation dar, wenn komplexe Datenstrukturen, die mehrere
Werte beinhalten, betrachtet werden. Müssen diese Wert für Wert verglichen werden,
oder ist Objektgleichheit gefragt, stehen zwei Dinge also an der gleichen Stelle im
Speicher?
Clojure beantwortet diese Frage auf natürliche Art und Weise für eine
Sprache, die auf einer Plattform läuft: Clojure erbt die Gleichheit von Java. Unter der Haube
wird Javas equals-Methode auf den gefragten Objekten aufgerufen werden. Diese Funktion
wird von Clojure noch dahingehend erweitert, dass sowohl Zahlentypen als auch
Datenstrukturen weitgehend typunabhängig verglichen werden. Für die Clojure-eigenen
besonderen Datenstrukturen gilt, dass auch sie nach Werten vergleichen, nicht nach
Objektidentität.
Gleichheit testet in Clojure die Funktion = oder für den Spezialfall von Zahlen auch
==. Dabei ist == funktional identisch zu =, es kann aber durch Hinweise an dem Compiler
bezüglich des Typs der zu vergleichenden Zahlen (vergleiche auch Abschnitt 2.15) in Hinsicht
auf die Geschwindigkeit der Ausführung optimiert werden.
user> (def einskommafuenf 1.5)
#’user/einskommafuenf
user> (def nullkommafuenf 0.5)
#’user/nullkommafuenf
user> (= eins (- einskommafuenf nullkommafuenf))
true
user> (def vektor1 [1 2 3])
#’user/vektor1
user> (def vektor2 [eins 2 3])
#’user/vektor2
user> vektor2
[1 2 3]
user> (= vektor1 vektor2)
true
Auf referenzielle Gleichheit von Objekten kann mit der Funktion
identical? getestet werden, die Javas Operator == entspricht. Dabei ist jedoch
zu beachten, dass Java bei kleinen Integerwerten eine Optimierung mit ins Spiel
bringt, die eigentlich verschiedene Objekte bei kleinen ganzen Zahlen gleich sein
lässt.
user> (def grossezahl1 123456789)
#’user/grossezahl1
user> (def grossezahl2 123456789)
#’user/grossezahl2
user> (= grossezahl1 grossezahl2)
true
user> (identical? grossezahl1 grossezahl2)
false
user> (def kleinezahl1 10)
#’user/kleinezahl1
user> (def kleinezahl2 10)
#’user/kleinezahl2
user> (= kleinezahl1 kleinezahl2)
true
user> (identical? kleinezahl1 kleinezahl2)
true
Gleich und Gleich …Common Lisp kennt mit
=,
char=,
string=,
char-equal,
eq,
eql,
equal,
equalp,
string-equal und
tree-equal mindestens zehn verschiedene Operatoren, die auf verschiedene Weisen auf „Gleichheit“ testen. Diese Operatoren tauchen in Clojure (bislang?) nicht auf. Die Zeit wird zeigen, welche davon tatsächlich notwendig sind und doch noch Einzug in die Sprache halten werden.
DenUngleich zwei Möglichkeiten, auf Gleichheit zu testen, steht eine Vielzahl von
Ungleichheiten gegenüber. Monotone und streng monotone Serien von Zahlen werden mit den
Funktionen <, <=, => und > getestet, die mehrere Zahlen gleichzeitig vergleichen
können.
user> (< 1 2 3 4 4 5)
false
user> (<= 1 2 3 4 4 5)
true
Diese Funktionen akzeptieren jedoch nur Zahlen als Argumente. Etwas generischer geht
compare zu Werke, das im Wesentlichen der Java-Methode compareTo entspricht. Diese kann
mit verschiedenen Argumenten umgehen, allerdings nicht in einem Aufruf. Es lässt sich also
kein String mit einem Integer vergleichen.
user> (compare 1 2)
-1
user> (compare "abc" "bcd")
-1
user> (compare 11 "11")
java.lang.ClassCastException:
java.lang.String cannot be cast to java.lang.Number
Mit compare lassen sich alle Typen vergleichen, die das Java-Interface Comparable
implementieren. Im Falle von Vektoren wird zum Beispiel zunächst die Anzahl der Elemente
und bei Gleichheit das Verhältnis des ersten nicht gleichen Elements überpüft.
user> (compare [1 2] [1 2 3])
-1
user> (compare [1 2] [1 2])
0
user> (compare [1 2 3] [1 2 2])
1
Das besondere Element nil ist einem Java-Programmierer recht schnell erklärt: Es ist
Javas NULL. Es steht wirklich für „Nichts“, nicht für eine leere Liste oder einen leeren Vektor,
sondern Nichts. In Common Lisp sind nil und die leere Liste ’() gleichbedeutend, in
Clojure ist das nicht so. In Clojure lässt sich dafür aber eine leere Liste von einem
leeren Vektor oder einer leeren Map unterscheiden. Selbstverständlich ist die Zahl 0
(Null) auch von nil verschieden und bedeutet auch in einem Wahrheitskontext nicht
„falsch“.
user> (if 0
"null ist wahr"
"null ist unwahr")
"null ist wahr"
In Clojure werden ausschließlich nil und false als nicht wahr verwendet. Alle
anderen Werte gelten als wahr.
user> (if nil "nil wahr" "nil unwahr")
"nil unwahr"
user> (if false "false wahr" "false unwahr")
"false unwahr"
user> (if ’() "’() wahr" "’() unwahr")
"’() wahr"
Dennoch sind nil und false unterschiedliche Dinge. Das Erstgenannte entspricht exakt
Javas null, aber false ist äquivalent zu Boolean.FALSE. Analog dazu entspricht true dann
Boolean.TRUE.
user> (type nil)
nil
user> (type false)
java.lang.Boolean
user> (type true)
java.lang.Boolean
Die Symbole false, true und auch nil werden bereits vom Lisp-Reader gesondert
behandelt und in die entsprechenden Java-Pendants gewandelt.
Clojure erbt also seine Auffassung von Gleichheit, Wahrheit und Null weitestgehend von
Java.
Nachdem nun Clojures Verständnis von booleschen Ausdrücken geklärt ist, können diese in
verschiedenen Formen verwendet werden. Clojure bietet verschiedene Kontrollkonstrukte, die
in diesem Abschnitt erklärt werden.
Eine bereits häufig demonstrierte Form ist die Verwendung von if. Die bisherigen
Beispiele waren immer dergestalt, dass je ein Ausdruck den Then- und einer den Else-Teil
abgedeckt hat. Das verlangt if auch exakt so. Gelegentlich ist es für das zu behandelnde
Problem aber notwendig, mehrere Anweisungen in einem der beiden Blöcke auszuführen. Dann
können diese mit dem Befehl do zusammengefasst werden.
(defn mind-zehn [x]
(if (< x 10)
;; then: zu wenig
(do
(println "Zu wenig, bekommst 10")
10)
;; else, das geht so
x))
user> (mind-zehn 5)
Zu wenig, bekommst 10
10
user> (mind-zehn 15)
15
Eine weitere Abweichung vom bisherigen Aufruf von if liegt vor, wenn kein
Else-Teil benötigt wird. Diese Form erlaubt auch if, aber für den Leser des Quelltexts ist es
vorteilhaft, den speziell für diesen Fall vorgesehenen Befehl when zu verwenden. Dann weiß der
Leser, dass kein Else-Teil folgen wird.
;; Namensliste keineswegs vollständig :)
(def irc-leute #{"chouser" "hiredman" "rhickey" "lpetit"})
(defn pruefe-nachricht [msg]
(when (irc-leute (:sender msg))
(println "Nachricht evtl. wichtig?")))
user> (pruefe-nachricht
{:sender "ska2342"
:text "Hi, I have a question"})
nil
user> (pruefe-nachricht
{:sender "rhickey"
:text "New Clojure release!"})
Nachricht evtl. wichtig?
nil
Dieses Beispiel verwendet ein Set mit einigen IRC-Namen, die im Clojure-Kanal auftauchen.
Die Funktion pruefe-nachricht sucht bei einer Nachricht in diesem Set nach dem Autor der
Nachricht und benachrichtigt den Benutzer, wenn einer der Autoren auftaucht. Für diese
Suche wird das Set selbst als Funktion verwendet. (Die Liste der Namen ist natürlich weder
repräsentativ noch vollständig.)
Die Verknüpfung mehrerer Bedingungen übernehmen die Befehle and, or und
not. Diese werden wie alle anderen Lisp-Befehle auch verwendet: Sie stehen vor den einzelnen
Bedingungen. Das ist im Falle einer Schachtelung leichter zu lesen als die von C oder Java
bekannten Operatoren && oder ||. Eine naive Funktion, die ganze Zahlen in Form von Strings
oder Integern verarbeitet, könnte so den Test auf den Texttypen mit einem regulären
Ausdruck und einem Aufruf von re-find kombinieren. Reguläre Ausdrücke werden in
Abschnitt 2.13 beschrieben.
(defn zahl [x]
(if (and (string? x)
(re-find #"^[0-9]+$" x))
(Integer/parseInt x)
x))
user> (zahl 3)
3
user> (zahl "92")
92
Da sowohl and als auch or aber nur so viele ihrer Argumente evaluieren, wie
sie brauchen, bis ihr Resultat feststeht, eignen sie sich auch für Kurzschlusslogik.
(defn vollzugriff? [f]
(let [ff (if (instance? java.io.File f)
f
(java.io.File. f))]
(and (.canRead ff)
(.canWrite ff))))
user> (vollzugriff?
(str (System/getenv "HOME")
(java.io.File/separator)
".bashrc"))
true
user> (vollzugriff?
(java.io.File. "/etc/hosts"))
false
Die Negierung eines Ausdrucks erfolgt mit not. Da diese Form jedoch so häufig ist,
existiert mit if-not eine kompakte Form mit gleicher Bedeutung.
(defn wer-wars? [anlass]
(if-not (= anlass "steinigung")
"Sie war’s"
"Er war’s"))
user> (wer-wars? "essen")
"Sie war’s"
user> (wer-wars? "steinigung")
"Er war’s"
Das negierte Pendant zu when ist when-not, dessen Verwendung ähnlich trivial
ist.
(defn denk-an-creme [himmel]
(when-not (= himmel "wolkig")
"Denk an die Sonnencreme"))
user> (denk-an-creme "blau")
"Denk an die Sonnencreme"
In vielen Programmsituationen gilt es, verschiedene Fälle zu
unterscheiden. Hier hat Lisp traditionell ein hilfreiches Konstrukt, das auch Clojure
anbietet. Das Makro cond expandiert im Hintergrund zu einer geschachtelten Folge von
if-Anweisungen. Der Aufruf von cond verlangt die paarweise Angabe von Bedingungen mit
dem auszuführenden Ausdruck, falls die Bedingung eintritt.
(cond
bedingung-1
ausdruck-1
bedingung-2
ausdruck-2
;; ...
)
Diese Form unterscheidet sich durch das Weglassen von Klammer-Paaren
von der Schreibweise in Common Lisp. Dort werden die Paare aus Bedingung und Wert
explizit durch eine weitere Klammerung zusammengefasst. Bei Clojure leidet die
Lesbarkeit etwas darunter, denn der Leser muss die Argumente durchzählen. Im
Normalfall wird sich aber die Bedingung auch ohne Zählen erkennen lassen. ReihenfolgeDie
Bedingungen werden in der angegebenen Reihenfolge ausgewertet, und nur das erste
Resultat bestimmt das Ergebnis des gesamten Ausdrucks. Auf diese Weise lassen
sich speziellere Fälle zunächst abhandeln. In Konsequenz wird häufig ein letzter
Ausdruck angegeben, der den Default bestimmt, dessen Bedingung also immer wahr ist.
Dort könnte als Bedingung schlicht true stehen, doch hat es sich etabliert, dort
das Schlüsselwort „:else“ zu verwenden. Das folgende Beispiel enthält verschiedene
Bedingungen. Es beginnt mit einem Spezialfall und endet schließlich mit einem
Defaultwert.
(defn welche-schuhe [temp niederschlag]
(cond
(and (not niederschlag)
(> temp 30)) "Flip-Flops"
(and (not niederschlag)
(> temp 20)) "Sandalen"
(< temp 5) "Stiefel"
(not niederschlag) "Turnschuhe"
:else "Halbschuhe"))
user> (welche-schuhe 30 false)
"Sandalen"
user> (welche-schuhe 30 true)
"Halbschuhe"
user> (welche-schuhe 15 false)
"Turnschuhe"
user> (welche-schuhe 1 true)
"Stiefel"
Ein naher Verwandter von cond ist condp. Dieser bildet eine Abkürzung für den Fall,
dass alle Bedingungen vom Ergebnis eines immer gleich gearteten Aufrufs abhängen. Die
formale Definition von condp hat die Form
(condp predicate expr
test-1
resultat-1
;; ...
)
Die Funktion predicate wird für jedes Paar aus Test und Resultat mit zwei Argumenten
aufgerufen: test-n und expr. Wenn dieser Aufruf wahr zurückliefert, wird das jeweilige
Resultat verwendet.
Ein einfaches Beispiel verwendet = als Prädikat und vergleicht die Objekttypen.
(defn dc [x]
(condp = (class x)
String (.toLowerCase x)
Integer (str (Character/toLowerCase (char x)))))
user> (dc "HALLO")
"hallo"
user> (char 89)
\Y
user> (dc 89)
"y"
user> (dc ["A" "B" "C"])
java.lang.IllegalArgumentException:
No matching clause: class clojure.lang.PersistentVector
Die hier definierte Funktion akzeptiert Objekte vom Typ String und Integer und reagiert
auf die beiden auf verschiedene Weise.
Weitere attraktive Möglichkeiten für das Prädikat sind die Verwendung von
Sets, Maps oder deren (Keyword-)Schlüssel. Mit diesen lässt ich auf Zugehörigkeit zu einer
Gruppe oder in einer Map kodierte Eigenschaften reagieren. Interessant ist auch die
Kombination mit apply, die es erlaubt zu testen, welches Prädikat ein übergebener Wert
erfüllt.
(defn welches-pred [ding]
(condp apply [ding]
integer? "Ist ein Integer"
keyword? "Ist ein Keyword"
pos? "Zahl größer 0"))
user> (welches-pred 1)
"Ist ein Integer"
user> (welches-pred :hallo)
"Ist ein Keyword"
user> (welches-pred 4.5)
"Zahl größer 0"
Natürlich ist hier auf eventuell auftretende Exceptions zu achten, wie beim nächsten Aufruf
deutlich wird:
user> (welches-pred {:a 1})
java.lang.ClassCastException:
clojure.lang.PersistentArrayMap cannot be cast to
java.lang.Number
Funktion für das Resultat
Es ist zu beachten, dass es nicht so ohne weiteres möglich ist, einen
Defaultwert anzugeben. Ob und wie das möglich ist, hängt von der Prädikatsfunktion ab.
Wenn das Resultat durch den Aufruf einer weiteren Funktion erfolgen soll, muss zwischen den
Testausdruck und die Resultatsfunktion das spezielle Keyword :» geschrieben werden. Die
Resultatsfunktion bekommt als einziges Argument das Ergebnis des Aufrufs des Prädikats
übergeben.
(defn t [x]
(condp < x
100 :>> #(println "< 100" x %)
10 :>> #(println "< 10" x %)
1 :>> #(println "< 1" x %)))
user> (t 5)
< 1 5 true
nil
user> (t 50)
< 10 50 true
nil
user> (t 500)
< 100 500 true
nil
Sowohl cond als auch condp zeigen sich deutlich dynamischer als die von Sprachen wie C
bekannten switch-Anweisungen. Im Falle von switch müssen die einzelnen Werte, die die
unterschiedlichen Fälle markieren, bereits zur Compile-Zeit feststehen. Bei cond und condp
findet die Auswertung zur Laufzeit statt, und beliebige boolesche Ausdrücke können
verwendet werden. Seit Version 1.2 stellt Clojure aber auch ein Konstrukt bereit, das switch
ähnelt: case.
Das folgende Beispiel demonstriert die Verwendung von case anhand einer fiktiven
Mediendatenbank, für deren Inhalte eine Funktion mit Hilfe des Medientyps ermittelt, wo im
Hause nach dem Medium gesucht werden sollte. Das erste Argument für case ist hier der
Ausdruck (:type m), es wird also aus der Map m der Wert zum Schlüssel :type ermittelt. Die
darauf folgenden Ausdrücke geben je möglichen Wert (:cd oder :ogg) den Platz des Mediums
in Form eines Strings zurück.
(def media-db
[{:type :cd
:artist "Ozric Tentacles"
:title "Become the Other"}
{:type :ogg
:artist "Phish"
:title "Lawn Boy"}])
(defn medien-ort [m]
(case (:type m)
:cd "Schrank"
:ogg "Computer"))
user> (map medien-ort media-db)
("Schrank" "Computer")
Den Abschluss dieses Abschnitts bilden die Speziallösungen when-let und
when-first. Die erstgenannte Lösung verbindet die Evaluation eines Tests mit dem Binden
einer lokalen Variablen an das Ergebnis des Tests. Das folgende Beispiel verwendet dazu die
Aufrufform mit drei Argumenten von nth, bei der das dritte Argument das Ergebnis
angibt, falls in der Datenstruktur unter dem angegebenen Index nichts gefunden
wurde.
Die Funktion viertes-hoch-fuenftes stellt mit Hilfe dieses Aufrufs fest, ob es ein viertes
und fünftes Element gibt. Werden die beiden gefunden, stellt when-let sie als lokale
Variablenbindung zur Verfügung.
(defn viertes-hoch-fuenftes [col]
(when-let [viert (nth col 4 nil)]
(when-let [fuenft (nth col 5 nil)]
(Math/pow viert fuenft))))
user> (nth [1 2 3] 99 "Bei 99 ist nix")
"Bei 99 ist nix"
user> (viertes-hoch-fuenftes [1 2 3])
nil
user> (viertes-hoch-fuenftes [0 1 2 3 2 3])
8.0
user> (viertes-hoch-fuenftes [0 1 2 3 4 2])
16.0
Damit wird deutlich, dass sich when-let immer dann empfiehlt, wenn mit einem zu
ermittelnden Wert weiter operiert werden soll, sofern der Wert vorhanden ist. Im
Gegensatz dazu funktioniert when-first etwas anders. Zwar stellt es auch eine
lokale Variablenbindung her – in diesem Falle zum ersten Element einer Sequence –,
doch der Test erfolgt darauf, ob sich in der Bindingform tatsächlich eine Sequence
befindet.
user> (when-first
[x1 [1 2 3 4]]
(* x1 2))
2
Beiden Befehlen ist gemein, dass sie in ihren Variablenbindungen nur genau ein Element
akzeptieren. Im Beispiel von when-let waren daher zwei Aufrufe notwendig. Auch die
Verwendung zerlegender Variablenbindung führt ziemlich sicher nicht zum erwarteten
Ergebnis. Zwar zerlegt Clojure die Variablenbindung, doch der Test, ob das zu einem wahren
Ausdruck geführt hat, erweist sich als immer wahr. Es werden nicht die einzelnen Variablen
ausgewertet.
user> (when-let [[a b c] [1 2 3]]
(list a b c))
(1 2 3)
user> (when-let [[a b c] [1 3]]
(list a b c))
(1 3 nil)
user> (when-let [[a b c] []]
(list a b c))
(nil nil nil)
user> (when-let [{:keys [ui jui]} {:oh "Oh"}]
(list ui jui))
(nil nil)
Exceptions in Clojure sind vor allem für Java-Programmierer leicht erklärt, denn Clojures
Exceptions sind Javas Exceptions.
Wie in Java: try, catch, finally
Das Duo aus try und catch entspricht der Verwendung in Java,
lediglich die Anordnung unterscheidet sich leicht. Die Ausdrücke, die dem try folgen, werden
evaluiert und eventuelle Exceptions werden mit einem oder mehreren catch-Ausdrücken
aufgefangen. In den catch-Ausdrücken, die der Reihe nach untersucht werden, kann auf die
Art der Exception spezialisiert werden und abschließend ein optionaler finally-Ausdruck
folgen. Eine große Erleichterung besteht darin, dass es in Clojure nicht notwendig
ist, jede „checked Exception“ ausdrücklich zu fangen. Diese Notwendigkeit, einst
eingeführt, um das Fangen von Exceptions durch den Compiler zu erzwingen und so
robusteren Code zu erzeugen, gilt heute auch unter Java-Programmierern als eher
lästig.
user> (try
(with-open [stream
(java.io.BufferedReader.
(java.io.FileReader.
"/home/clj/.emacs"))]
(println "Habe .emacs gefunden")
(println "Erste Zeile: " (.readLine stream)))
(catch java.io.IOException e
(println "Problem beim Oeffnen von .emacs\n" e))
(catch Exception e
(println "Unerwartete Exception: " e))
(finally
(println "\nBin mit der Pruefung durch")))
Problem beim Oeffnen von .emacs
#<FileNotFoundException
java.io.FileNotFoundException:
/home/clj/.emacs (No such file or directory)>
Bin mit der Pruefung durch
nil
Dieses Beispiel versucht, die klassische Emacs-Initialisierungsdatei im Heimatverzeichnis des
Benutzers „clj“ zu finden und aus ihr eine Zeile zu lesen. Falls es eine IOException gibt, soll
diese mit passender Fehlermeldung ausgegeben werden. Falls eine andere Exception auftritt,
reagiert der Code darauf ebenfalls mit einer entsprechenden Meldung. Abschließend (finally)
wird eine Schlussmeldung ausgegeben.
In diesem Beispiel taucht versteckt noch eine weitere Behandlung von
Exceptions auf. Der Befehl with-open ist ein Makro, das an der Stelle seiner Verwendung
nicht nur eine Variablenbindung gemäß der Angaben im Binding-Vektor für die Zeit, die das
Programm im Rumpf von with-open verbringt, anlegt. Zudem erzeugt es noch Code, der
sicherstellt, dass der geöffnete BufferedReader auch wieder geschlossen wird. Dieses Makro
zeigt auf eindrucksvolle Weise, wozu das Makrosystem in der Lage ist. Der Abschnitt 2.12.3
wird näher darauf eingehen.
Der einleitende Abschnitt 2.2 zur Gewöhnung an Lisp hat vereinfacht dargestellt, dass bei der
Evaluierung eines Listenausdrucks das erste Element immer den Namen einer Funktion angibt.
Tatsächlich können an erster Stelle drei semantisch unterschiedliche Objekte stehen, deren
Verhalten sich leicht unterscheidet und von denen eines grundlegender Bestandteil der
Sprache und durch den Programmierer nicht zu beeinflussen ist. Wir fassen alle drei
unter den Begriffen „Anweisung“ oder „Befehl“ zusammen. Somit verwenden wir
diese Begriffe nicht in ihrer in imperativen Sprachen bekannten Bedeutung, bei
der der durch die Ausführung der Anweisung erzielte Nebeneffekt im Mittelpunkt
steht.
In jedem Fall erwartet Clojure den Namen eines Symbols, das im aktuellen Namensraum
mit etwas Ausführbarem verknüpft ist.
Der Aufruf von Funktionen macht den größten Teil der Anweisungen aus. Clojure ist eine
funktionale Programmiersprache, und diese Bezeichnung suggeriert zu Recht, dass Funktionen
eine wichtige Rolle spielen.
Clojures Implementation von Funktionen erzeugt einerseits Objekte, die Javas
Interfaces Callable, Runnable sowie Comparator implementieren. Damit sind alle Funktionen
von Clojure in Javas Thread-Landschaft verwendbar. Zudem implementieren alle Funktionen
das Clojure-eigene Interface IFn, das unter anderem das Überladen nach Argumentenanzahl
erlaubt. Beim Überladen sind alle Varianten Bestandteil nur einer Funktionsdefinition und
auch desselben Funktionsobjekts.
Die am häufigsten verwendete Form für die Definition einer Funktion ist defn, daher wurde
diese Form bereits zu Beginn eingeführt. Mit defn- steht eine sehr ähnliche Form zur
Verfügung, die jedoch in einem Namespace eine private Funktion anlegt.
defn: eine Abkürzung für def und fn
Hinter den Kulissen sind jedoch zwei andere Befehle für die
Funktionsdefinition verantwortlich. Zunächst werden Funktionen immer mit Hilfe von fn
angelegt. Das Resultat, also die Funktion, wird dann mit def in einer Var gespeichert. Die
beiden folgenden, äquivalenten Konstrukte zeigen sowohl die Verwendung von def als auch die
der Kombination von def und fn. Die zweite Form verwendet den Operator fn zur Anlage
einer Funktion und bindet das Resultat an die Var, deren Namen als erstes Argument von def
angegeben wird.
(defn eine-fn [arg]
(println "Ich bekam als Argument: " arg))
(def eine-fn
(fn [arg]
(println "Ich bekam als Argument: " arg)))
Die Funktion fn dient immer zur Erzeugung einer neuen Funktion. Die formale
Syntax-Beschreibung von fn lautet
(fn name? [params*] exprs*)
;; oder
(fn name? ([params*] exprs*)+)
Die Angabe eines Namens bei Verwendung von fn ist selten, wird aber benötigt, wenn
innerhalb einer Funktionsdefinition, die nicht in einer Var gespeichert wird, eine Rekursion
erfolgen soll.
Anzahl der Argumente, Überladen
Des Weiteren unterscheiden sich die beiden Formen darin, ob
die zu erzeugende Funktion nur eine Argumentenliste versteht, oder aber bezüglich der Anzahl
ihrer Argumente – ihrer „Arity“ – überladen wird.
Wenn eine Überladung gewünscht ist, werden die separaten Funktionsrümpfe mit ihrer
Argumentenliste in je einer Liste aufgeführt.
(defn eins-zwei-oder-drei
([eins] (println "Eins,"))
([eins zwei] (println "Zwei,"))
([eins zwei drei]
(println "Oder drei.")
(println "Du musst dich entscheiden,"
"drei Felder sind frei.")))
user> (eins-zwei-oder-drei 1)
Eins,
nil
user> (eins-zwei-oder-drei 1 1)
Zwei,
nil
user> (eins-zwei-oder-drei 1 1 1)
Oder drei.
Du musst dich entscheiden, drei Felder sind frei.
nil
Ein weiteres Beispiel, das die Definition bezüglich ihrer Argumentenanzahl demonstriert,
liefert die Additionsfunktion. Eine einfache Implementation einer Funktion zur Addition, die
die Fälle von keinem und nur einem Argument dediziert und sinnvoll behandelt, könnte so
aussehen:
(defn simpel-plus
"Addiere zwei Zahlen, wenn kein Argument da ist, liefer 0."
([] 0)
([x] x)
([x y] (+ x y)))
user> (simpel-plus)
0
user> (simpel-plus 1)
1
user> (simpel-plus 1 2)
3
Allerdings zeigt diese Implementation der Addition Schwächen, wenn mehr als zwei
Argumente übergeben werden:
user> (simpel-plus 1 2 3)
java.lang.IllegalArgumentException:
Wrong number of args (3) passed to: user$simpel-plus
Die tatsächliche Implementation der Funktion + in Clojure ist diesem einfachen Ansatz aber
recht ähnlich:
;; Leicht verkuerzte Darstellung
(defn +
"Returns the sum of nums. (+) returns 0."
([] 0)
([x] (cast Number x))
([x y]
(. clojure.lang.Numbers (add x y)))
([x y & more]
(reduce + (+ x y) more)))
Die erste Variante – ohne Argumente – liefert einfach 0 zurück, was sinnvoll erscheint, da
nicht addiert wird und die Null das neutrale Element bezüglich der Addition ist. Die
Multiplikation verhält sich da ebenso und gibt ihr neutrales Element (1) zurück,
wenn keine Argumente übergeben wurden. Bei nur einem Argument wird die Zahl
selbst zurückgegeben, aber mit der Funktion cast umgeben. Diese stellt sicher, dass
es sich auch um ein Objekt vom Typ Number handelt, und wirft andernfalls eine
ClassCastException. Im Falle von zwei Argumenten wird die statische Java-Methode add aus
clojure.lang.Numbers aufgerufen. Wie bereits gezeigt wurde, akzeptiert + aber auch mehr als
zwei Argumente. Dieser Fall wird durch die letzte Funktionsvariante implementiert,
die mit Hilfe von & die weiteren Argumente in einer Liste sammelt (vergleiche den
Abschnitt 2.7.5). Nur eine flexible ArgumentenlisteEs ist wichtig zu wissen, dass bei einer
Funktion, die bezüglich der Anzahl ihrer Argumente überladen wird, nur in einer
Variante eine solche flexible Argumentenliste verwendet werden darf. Im Falle von
mehr als zwei Argumenten wird eine Rekursion angestoßen, die die ersten beiden
Elemente addiert (rekursiver Aufruf der Variante von + mit zwei Argumenten) und mit
Hilfe von reduce die Addition der weiteren Elemente einleitet. An dieser Stelle soll
auf reduce nicht weiter eingegangen werden. Nur so viel: Sie iteriert durch eine
Sequence und wendet die übergebene Funktion (hier also +) auf das erste Element der
Sequence sowie das bisherige Ergebnis an. Eine Beschreibung von reduce erfolgt in
Abschnitt 2.17.2.
Bei der Benennung von Funktionen ist zu beachten, dass Clojure die Namen von
Funktionen nicht von den Namen anderer Dinge trennt. Das schränkt die Menge der
verfügbaren Namen ein, was sich vor allem bei der Benennung von lokalen Variablen, wie den
Argumenten einer Funktion, bemerkbar macht:
(defn test-name [list]
(println "list nix gut")
(list 1 2 3))
user> (test-name 99)
list nix gut
java.lang.ClassCastException:
java.lang.Integer cannot be cast to clojure.lang.IFn
Hier überschreibt der lokale Name list die im Allgemeinen verfügbare Funktion gleichen
Namens, so dass ihr Aufruf im Geltungsbereich der lokalen Bindung nicht mehr möglich ist.
Stattdessen versucht Clojure das mit dem Namen list übergebene Argument, also die Zahl
99, als Funktion aufzurufen. Wenn dieser Funktion eine Funktion übergeben wird, wird das
deutlich sichtbar.
user> (test-name +)
list nix gut
6
Diese Eigenschaft macht aus Clojure ein „Lisp-1“, wohingegen ein „Lisp-2“ die Namen von
Funktionen auf der einen Seite und die von Variablen und Argumenten auf der anderen
trennt.
Die Funktion reduce aus dem Beispiel zum Überladen der Addition bezüglich ihrer
Argumentenliste kann hier stellvertretend für eine Klasse von Funktionen betrachtet werden,
die ihrerseits Funktionen als Argumente erwarten. Solche Konstrukte sind in der funktionalen
Programmierung sehr häufig anzutreffen. Dadurch entsteht ein so hoher Bedarf an Funktionen,
dass nicht für jeden Fall extra eine globale und mit einem Namen versehene Funktion
definiert werden sollte. In solchen Fällen helfen anonyme Funktionen, diesen Overhead
zu vermeiden. Sie können mit fn überall erzeugt werden, wo sie gerade gebraucht
werden.
user> (reduce
(fn [x y]
(let [s (str x " " y)]
(println s)
s))
’("ich" "und" "du" "muellers" "esel" "meiers" "kuh"))
ich und
ich und du
ich und du muellers
ich und du muellers esel
ich und du muellers esel meiers
ich und du muellers esel meiers kuh
"ich und du muellers esel meiers kuh"
In diesem Beispiel wird eine anonyme Funktion definiert, die zwei Argumente
entgegennimmt. Diese konkateniert sie mit Hilfe von str, gibt sie als Nebeneffekt aus und
liefert sie auch als Resultat. Auf diese Weise wird zudem sichtbar, wie reduce durch die Liste
iteriert und das Ergebnis zusammenbaut.
Da gerade anonyme Funktionen sehr häufig verwendet werden, bietet Clojure für
Funktionen noch eine spezielle Read-Syntax an. Anstatt die Funktionsobjekte mit fn
zu erzeugen, kann auch das Konstrukt #(body) verwendet werden. Innerhalb des
Funktionsrumpfes kann dann mit den speziellen Variablen % auf das erste Argument und mit
%1, %2 …%n auf die positionalen Argumente zugegriffen werden. Ein Rest-Argument erhält den
Namen %&. Es ist zu beachten, dass diese Form nicht äquivalent zu fn ist und dass sie nur für
sehr kurze Funktionen verwendet werden sollte. Weitere Beschränkungen ergeben sich daraus,
dass diese anonymen Funktionen nicht geschachtelt werden können, die mit fn erzeugten aber
sehr wohl, sowie in der Kombination mit anderen syntaktischen Konstrukten des Readers
(siehe auch Abschnitt 2.18.2).
user> (take 10 (iterate inc 1))
(1 2 3 4 5 6 7 8 9 10)
user> (map #(* % 2) (take 10 (iterate inc 1)))
(2 4 6 8 10 12 14 16 18 20)
;; verwendet toUpperCase aus java.lang.String:
user> (map #(.toUpperCase %)
["common" "lisp" "symbole"
"sind" "gross" "geschrieben"])
("COMMON" "LISP" "SYMBOLE" "SIND" "GROSS" "GESCHRIEBEN")
user> (range 2)
(0 1)
user> (take 5 (cycle (range 2)))
(0 1 0 1 0)
user> (map #(list %1 %2)
(take 5 (cycle (range 2)))
(take 5 (cycle (range 2))))
((0 0) (1 1) (0 0) (1 1) (0 0))
user> (sort #(> %1 %2) [3 55 4 11 123 76 0])
(123 76 55 11 4 3 0)
user> (sort > [3 55 4 11 123 76 0])
(123 76 55 11 4 3 0)
In diesem Beispiel tauchen einige neue Funktionen auf, die jeweils zur Verdeutlichung an der
REPL getestet werden, bevor das eigentliche Beispiel mit der anonymen Funktion
folgt.
-
iterate
- (iterate f x). Liefert eine unendliche Lazy Sequence zurück, bei der die
Funktion f im ersten Schritt auf den Startwert x und danach jeweils auf das
Ergebnis des vorherigen Schritts angewendet wird. Achtung! Nicht an der REPL
eingeben, da das Resultat unendlich viele Elemente enthält.
-
take
- (take n sq). Entschärft unendliche wie auch endliche Sequences, indem es nur n
Elemente der Sequence sq nimmt.
-
range
- (range start? end step?). Erzeugt eine Sequence, die bei start oder 0
beginnt, bei jedem Schritt step (oder 1) fortschreitet und vor end aufhört.
-
cycle
- (cycle coll). Erzeugt eine unendliche Sequence, die die Werte von coll immer
wiederholt.
Funktionen werden wie andere Datentypen auch verwendet. In einer funktionalen
Programmiersprache wie Clojure ist es ganz natürlich, Funktionen zu schreiben, die
Funktionen als Argumente erwarten. Ebenso natürlich ist es, Funktionen zu entwickeln, die
ihrerseits Funktionen als Resultat liefern. Der Abschnitt 2.17.2 geht auf dieses Thema näher
ein.
Die Dokumentation einer Funktion ist – wie bereits in Abschnitt 2.4 beschrieben – in Clojure
Bestandteil der Funktionsdefinition und nicht durch speziell ausgezeichnete Kommentare
irgendwo in der Nähe der Funktion nachträglich hinzugefügt. Dabei speichert Clojure die
Dokumentation in den MetadatenMetadaten der Var, die die Funktion enthält. Die übliche
Form der Definition von Funktionen mit defn erlaubt die Angabe des Docstrings als String
zwischen Funktionsnamen und Argumentenliste. Die Hintergründe der Metadaten beleuchtet
Abschnitt 2.15.
(defn fn-mit-doku
"Diese Funktion demonstriert die Dokumentation"
[] (println "Nur zu Doku-Zwecken"))
user> (fn-mit-doku)
Nur zu Doku-Zwecken
nil
user> (doc fn-mit-doku)
-------------------------
user/fn-mit-doku
([])
Diese Funktion demonstriert die Dokumentation
nil
Wer bereits über Erfahrung in der Lisp-Programmierung verfügt, muss hier ein wenig
aufpassen. Diese Programmierer sind es gewohnt, den Docstring hinter die Argumentenliste zu
stellen:
common-lisp> (defun fun-name (args)
"Documentation String."
;; function body
)
Der Grund für diese Abweichung ist die oben beschriebene Möglichkeit der Überladung
bezüglich der Argumentenliste. Käme der Docstring nach den Argumenten, wäre für jede
einzelne Implementation eine Dokumentation anzugeben.
Mittlerweile sollte der Aufruf von Funktionen in Clojure kein Geheimnis mehr sein. Eine Liste
mit einem Funktionsnamen als erstem Element wird von Clojure evaluiert. Einer Funktion
können Argumente übergeben werden, die als weitere Elemente in dieser Liste auftauchen. Sie
werden meist durch Leerzeichen voneinander getrennt. Die Trennung mit Komma ist erlaubt,
gilt aber nicht als idiomatisch.
Eine Funktion, die einen Namen bekommen hat, sei es durch entsprechende
Verwendung von fn oder durch Binden an eine Var, kann sich selbst wieder aufrufen. In dem
Falle spricht man von Rekursion. Ähnliches gilt für die Verwendung von recur, mit der ein
Überlaufen des Stacks vermieden werden kann. Der Abschnitt 2.14 geht darauf näher
ein.
Geschachtelte Ausdrücke werden von innen nach außen und von links
nach rechts zunächst evaluiert, bevor abschließend die Funktion mit den dann feststehenden
Argumenten aufgerufen wird. Ein Beispiel mit gewollten Nebeneffekten verdeutlicht, wie die
Argumente ausgeführt werden:
(defn fn11 []
(println "Liefer 11 zurück") 11)
(defn fn22 []
(println "Liefer 22 zurück") 22)
user> (+ (fn11) (fn22))
Liefer 11 zurück
Liefer 22 zurück
33
Die Evaluation von geschachtelten Argumenten lässt sich ähnlich leicht nachvollziehen:
(defn fn33 []
(println "Liefer 33 zurück") 33)
(defn fn44 []
(println "Liefer 44 zurück") 44)
user> (+ (+ (fn11) (fn22))
(+ (fn33) (fn44)))
Liefer 11 zurück
Liefer 22 zurück
Liefer 33 zurück
Liefer 44 zurück
110
Vars als Funktionsbehälter
Funktionen sind an Vars gebunden. Eine Folge davon ist, dass Vars,
die solchermaßen gebunden sind, direkt an der Stelle verwendet werden können, an der sonst
die Symbole stehen, die eine Funktion benennen. Das funktioniert, da sowohl die Vars als auch
die Symbole letztlich zu etwas Ausführbarem evaluieren. Es ist auch eine Folge der Eigenschaft
von Clojure, ein „Lisp-1“ zu sein.
Das folgende Beispiel illustriert anhand einer mit dem Befehl fn erzeugten Funktion, die in
einer Var gespeichert ist, wie diese Var direkt an der Stelle eines Funktionsnamens verwendet
werden kann.
(def ich-halte-eine-fn
(fn [arg]
(println "Mein Argument war"
arg)))
user> (ich-halte-eine-fn "Hallo")
Mein Argument war Hallo
nil
Der Umweg über eine Var kann sogar vermieden werden, und an jener Stelle des
Funktionsaufrufs eine anonyme Funktion stehen. Da die Definition einer anonymen Funktion
auch nur wieder in einem Befehl besteht, ist klar, dass auch ein beliebiger Funktionsaufruf
erfolgen kann, der eine Funktion zurückgibt.
;; Klammern beachten
user> ((fn [arg]
(println "Mein Argument war" arg))
"Hallo")
Mein Argument war Hallo
nil
user> (defn auch-nur-mal []
*)
#’user/auch-nur-mal
user> (fn? (auch-nur-mal))
true
user> ((auch-nur-mal) 5 10)
50
Die Eigenschaft eines Funktionsaufrufes, dass alle Argumente zunächst evaluiert werden,
macht Funktionen für manche Aufgaben ungeeignet. Bei einem if soll zunächst das erste
Argument evaluiert werden und je nach Resultat entweder das zweite oder das dritte, aber auf
keinen Fall beide.
Wäre if eine normale Funktion, würde der folgende Ausdruck sowohl den Text „0
gewuerfelt“ als auch „1 gewuerfelt“ ausgeben.
(if (= 0 rand-int 2)
(println "0 gewuerfelt")
(println "1 gewuerfelt"))
Stattdessen verhält sich if aber wie erwartet, und je nach Ausgang des Aufrufs von
rand-int wird entweder der eine oder der andere Text ausgegeben.
Auch andere Befehle zeigen ein Verhalten, das zu dem von Funktionen
nicht passt. Für solche grundlegenden Funktionalitäten der Sprache selbst verwendet
Clojure – wie andere Lisp-Dialekte auch – sogenannte special operators (in der Literatur auch
häufig special forms genannt), die wir als spezielle Operatoren übersetzen. Diese Operatoren
bilden die nicht veränderbare Basis der Sprache Clojure.
Die folgende Liste liefert eine kurze, kompakte Beschreibung dieser speziellen
Operatoren.
-
def
- (def symbol init?). Legt eine globale Var mit dem durch symbol gegebenen
Namen im aktuellen Namensraum an oder findet eine bereits angelegte. Falls init
angegeben wird, wird es evaluiert und das Root-Binding der Var auf das Resultat
angelegt. Überschreibt das Root-Binding, was für die dynamische Neudefinition
von Vars eingesetzt wird. Die Verwendung zum Manipulieren von Status ist zwar
möglich, aber nicht üblich.
-
if
- (if test then else?). Bedingte Ausführung. Die Funktion von if wurde bereits
in Abschnitt 2.10 beschrieben.
-
do
- (do exprs*). Evaluiert alle übergebenen Ausdrücke exprs – potenziell auch für
ihren Nebeneffekt – und liefert das Resultat des letzten Ausdrucks zurück. Wird
verwendet, wenn ein Operator an einer Stelle nur einen Ausdruck erlaubt, aber
mehrere notwendig sind, oder um Nebeneffekte explizit zu bewirken. Entspricht
progn in Common Lisp.
-
let
- (let [bindings*] exprs*). Legt lokale Bindings nach den Angaben in bindings
an und führt dann die Ausdrücke exprs aus, die Zugriff auf die definierten Bindings
haben. Liefert das Resultat des letzten Ausdrucks zurück. Siehe Abschnitt 2.7.3.
-
quote
- (quote form). Liefert form zurück, ohne sie zu evaluieren. Wird meist mit Listen
verwendet, um die Evaluation der Liste nach den Lisp-Regeln zu verhindern.
-
var
- (var symbol). Sucht eine Var mit dem Namen, der durch symbol angegeben wurde,
und liefert diese Var zurück. Wichtig zu verstehen: Dieser Operator liefert nicht
den Wert, an den die Var gebunden ist.
-
fn
- (fn name? [params*] exprs*) oder bei verschiedenen Argumentenlisten (fn
name? ([params*] exprs*)+). Legt eine Funktion an, anonym, falls name nicht
angegeben wurde. Funktionen werden in Abschnitt 2.12.1 beschrieben.
-
loop
- (loop [bindings*] exprs*). Einstiegspunkt für Rekursionen,
vgl. Abschnitt 2.14.
-
recur
- (recur epxrs*). Springt an eine mit loop explizit oder fn implizit definierte
Einsprungsstelle mit neuen Werten für die Variablenbindungen. Offensichtlich muss
die Definition der Variablenbindung in loop oder eine Argumentenliste in fn zu
der Anzahl der Ausdrücke in recur passen. Dieser Operator darf nur an einer
Rückgabestelle einer Funktion oder eines loop-Ausdrucks stehen.
-
throw
- (throw expr). Wirft eine Exception, die durch Evaluation von expr entstehen
muss.
-
try
- (try expr* catch-clause* finally-clause?). Alle in expr angegebenen
Ausdrücke werden evaluiert und das Resultat des letzten Ausdrucks als Resultat
des gesamten Ausdrucks zurückgegeben, falls keine Exception auftrat. Andernfalls
werden alle catch-clause-Ausdrücke der Reihe nach betrachtet und die Ausdrücke
im ersten zur aufgetretenen Exception passenden Catch-Ausdruck ausgeführt.
Diese bestimmen dann auch das Resultat des gesamten Ausdrucks. Falls es
einen Teil finally-clause gibt, werden dessen Ausdrücke in jedem Falle evaluiert,
allerdings nur für ihre Nebeneffekte; sie tragen nicht zum Resultat des gesamten
Ausdrucks bei. Vergleiche auch Abschnitt 2.11.
-
.
- (sprich: „dot“) (. obj method args*). Direkter Zugriff auf Java-Funktionen. Wird
in Abschnitt 4.1 beschrieben.
-
new
- (new class args*). Erzeugen von Instanzen von Java-Objekten. Die explizite
Verwendung dieses Operators ist eher unüblich. Vergleiche die Abschnitte 2.5 und
4.1.
-
set!
- (set! (. obj field) expr). Dieser Operator kann entweder verwendet werden,
um eine globale Var, die in einem Thread bereits neu gebunden wurde, erneut zu
überschreiben, wobei auch das neue Binding wieder nur für den lokalen Thread
gilt, oder aber um Felder in einem Java-Objekt zu überschreiben.
Ganz Clojurien evaluiert seine Argumente. Ganz Clojurien? Nein, eine kleine Gruppe von
Kommandos wehrt sich dagegen, obwohl sie nicht zu den speziellen Operatoren gehören.
Beispiele dafür sind die logischen Operatoren and und or, die ihre Argumente sukzessive
evaluieren, bis ihr Ergebnis feststeht, aber auch comment, das seine Argumente gar
nicht evaluiert und somit einen Kommentar implementiert, der seine Funktion nicht
auf Ebene des Quelltexts, sondern auf der Ebene der Datenstruktur des Quelltexts
erfüllt. Diese Gruppe von Kommandos sind Makros, ein wichtiges Sprachelement von
Lisp.
Makros sind die Antwort auf die Frage, was Anwender tun können,
wenn ihnen ein Sprachkonstrukt fehlt. Sie erzeugen dort, wo sie eingesetzt werden, bevor der
Compiler seine Arbeit aufnimmt, neuen Quelltext. Java-Programmierer können leicht neue
Klassen und Methoden erstellen, aber was werden sie tun, wenn sie ein wiederkehrendes
Muster erkennen, das immer gleiche Wiederholungen zur Folge hat? Java hat, wie andere
Programmiersprachen auch, relativ viele syntaktische Konstrukte, die nicht auf Klassen und
Methoden zurückzuführen sind. Diese sind von der Sprache vorgegeben, unveränderbar
und darüber hinaus auch nicht erweiterbar. Muster und WiederholungenEs gibt keine
Möglichkeit, die Syntax von for so zu umzustellen, dass man nur noch den Namen der
Laufvariablen und den letzten Wert angibt, weil man festgestellt hat, dass das Muster,
das bei 0 beginnt zu zählen und in jedem Schritt um 1 inkrementiert, sehr häufig
auftaucht.
for(i = 0; i < letzter_wert; i++) ...
Es gibt keine Möglichkeit, in
JFrame fra = new JFrame("Frankreich");
fra.add(new JLabel("leWidget"));
fra.pack();
fra.setVisible(true)
die ständige Wiederholung von fra zu vermeiden, und es ist auch nicht möglich,
in
import java.awt.Dimension;
import java.awt.Color;
import java.awt.RenderingHints;
import java.awt.KeyboardFocusManager;
das immer wiederkehrende java.awt zu ersetzen, wenn wirklich nur gezielte Teile importiert
werden können. (Am Rande: Clojure liefert für die beiden letztgenannten Lösungen in Form
von Makros mit; die Lösung für das zweite Beispiel wurde bereits in Abschnitt 2.7.2
beschrieben und die Lösung des ersten wird in Abschnitt 4.1.1 auftauchen.) Die
Erweiterbarkeit von Java hat enge Grenzen. Die Erweiterbarkeit von Clojure nicht.
Gewissermaßen sind in Clojure die Daten unveränderlich, in Java hingegen die Konstrukte der
Sprache.
Um die Funktionsweise von Makros zu verstehen, kann es helfen, sich die
Frage zu stellen: „Wie kann ich mit meiner Programmiersprache neuen Quelltext
erzeugen?“ Bei den meisten Programmiersprachen wird die erste Antwort darauf
sein, mit Hilfe der String-Funktionen der Sprache den Text in Form einer Datei
oder im Speicher zusammenzubauen und dann die Werkzeuge zum Kompilieren und
Ausführen oder zur Interpretation aufzurufen. Dieses Verfahren gerät recht schnell
an seine Grenzen, und es entstehen in der Folge häufig Template-Systeme, die es
erlauben, größere Textmengen zu verwalten. Die Templates enthalten üblicherweise
aktive Elemente, also solche, die mit variablem Inhalt gefüllt werden können. Dazu
gesellen sich meist Kontrollkonstrukte für Wiederholungen oder Bedingungen. Somit
wird aus einem Template eine kleine Programmiersprache. Zur Beantwortung der
ursprünglichen Frage wurde ein eigener Interpreter entworfen Greenspun(vgl. auch
Greenspuns Tenth Rule [22]). Natürlich existieren auch technisch aufwendigere Lösungen,
die eine dynamische Erweiterung der Sprache erlauben. Im Falle Java existieren
beispielsweise verschiedene Bibliotheken zur Bytecode-Manipulation. Diese verlangen aber
ebenfalls nach einer Einarbeitung in eine andere Sprache, eben den Bytecode der
JVM.
Konsistenz: Lisp mit Lisp
Das Makrosystem von Lisp ist deutlich konsistenter, denn es erlaubt,
mit Lisp neuen Lisp-Code zu generieren. Clojures Makros können Clojure-Code
entgegennehmen und – noch bevor der Code an den Compiler geht – vollkommen neuen
Clojure-Code erzeugen. Dieses Verfahren hat ein wenig Ähnlichkeit mit der Arbeitsweise von
XSLT. Dort nimmt der XSLT-Prozessor ein XML-Dokument entgegen und transformiert es zu
einem neuen XML-Dokument, wobei die Beschreibung der Transformation ebenfalls als ein
XML-Dokument vorliegt. Diese Ähnlichkeit mag durchaus auf die Geschichte von XSLT
zurückzuführen sein, das als Nachfolger der Transformationssprache DSSL (sprich: „dissel“),
einem Lisp-Dialekt, gilt.
In den meisten Fällen ist ein Makro durch einen der folgenden Gründe motiviert:
- Die Evaluation von Argumenten soll kontrolliert werden.
- Wiederholungen im Quelltext sollen vermieden werden.
- Komplexität soll in einer eigenen, domänenspezifischen Sprache (DSL) gekapselt
werden, die natürlich wieder ein Lisp ist.
Beispiele für den ersten Fall wurden bereits genannt: and und or. In diesen Fällen geht es
gewissermaßen darum, die Sprache durch eigene spezielle Operatoren zu erweitern.
Derwith-artige zweite Fall liegt häufig bei den „with-artigen“ Makros vor. Diese legen meist
lokale Variablenbindungen auf einfache Weise an, führen ein Stück Quelltext des Anwenders
aus und räumen danach auf. Ein Mitglied dieser Familie ist with-open, das lokale Bindings für
eine geöffnete Quelle (beispielsweise eine Datei) erzeugt und eine Liste von Ausdrücken
evaluiert, die diese Bindings verwenden können. Abschließend stellt es sicher, dass die Quelle
geschlossen wird. Zudefine-artige den Beispielen für die dritte Motivation zählen die
„define-artigen“, die eine Definition in Form einer eigenen Spezialsprache aufnehmen und unter
Umständen erhebliche Mengen Code erzeugen, der für die passende Infrastruktur sorgt.
Hierzu gehört auch defn, das die Anlage von Funktionen mit Docstrings vereinfacht,
indem es den Aufruf von def mit den passenden Metadaten und einem Aufruf von
fn erzeugt. (Metadaten sind parallel zu Dateninhalten vorliegende Informationen,
die Clojure assoziiert und auswertet. Sie werden in Abschnitt 2.15 beschrieben.)
Somit vereinfacht defn den Aufruf von def mit der Erzeugung der notwendigen
Metadaten.
Eine wichtige Grundlage für das Funktionieren von Makros ist, dass
Clojure-Code in Form von Clojure-Daten geschrieben wird. Für Einsteiger ist das oft ein
unbedeutender Satz, dessen tieferer Sinn sich nicht erschließt. Doch das ist die Erklärung für
Lisps Syntax: Es ist eine Datenstruktur von Lisp. Das ist der vermutlich wichtigste Grund,
warum diese Syntax nicht zur Debatte steht; hier erst zeigt sich die wirkliche Stärke. Die
Bedeutsamkeit dieser „Code-as-Data-Philosophie“ tritt gerade im Zusammenhang mit
Makros am ehesten zutage. Denn auf diese Weise kann die Definition eines Makros
in gewohnter Manier ihre Daten behandeln, wobei der komplette Sprachstandard
vollumfänglich zur Verfügung steht. Makros betrachten Quelltext schlicht und ergreifend
als Daten (in erster Linie) vom Typ Liste. Das Resultat der Makro-Expansion ist
wieder eine Datenstruktur, die geeignet sein muss, vom Compiler verarbeitet zu
werden.
Clojure-Code besteht unter anderem aus Clojure-Listen. Ein Makro kann also eine Liste
erzeugen, deren Inhalt nach der Expansion des Makros evaluiert wird. Dazu kann die Funktion
list verwendet werden.
(defmacro plus-a-b [a b]
(list ’+ a b))
user> (plus-a-b 2 3)
5
Dieses Beispiel zeigt ein ebenso einfaches wie sinnloses Makro, das zwei Zahlen addiert. Die
dabei neu entstandene Form ist länger und weniger robust als das Original +. Das Beispiel ist
aber geeignet, um einige Eigenschaften von Makros zu untersuchen.
Zunächst fällt auf, dass die Definition eines Makros der einer Funktion
gleicht. Tatsächlich beginnt der Docstring von defmacro mit den Worten „Like defn, but …“,
und die Argumentenliste ist ebenfalls identisch.
Wann werden nun die Werte von a und b evaluiert? Vor der Übergabe an
plus-a-b oder später? Ein weiteres Beispiel mit einem etwas erweiterten Makro schafft
Klarheit.
(defn liefer-2 []
(println "Ich gebe 2 zurück")
2)
(defmacro plus-a-b-print [a b]
(println "Im Makro")
(list ’+ a b))
user> (plus-a-b-print (liefer-2) 5)
Im Makro
Ich gebe 2 zurück
7
(defn plus-a-b-fn [a b]
(println "In Funktion")
(+ a b))
user> (plus-a-b-fn (liefer-2) 5)
Ich gebe 2 zurück
In Funktion
7
Hier ist deutlich zu sehen, wie beim Aufruf von plus-a-b-print zuerst die Ausgabe des
Makros erfolgt und die Evaluation des ersten Arguments später stattfindet, während
bei plus-a-b-fn das Argument evaluiert wird, bevor es der Funktion übergeben
wird.
Bei der Entwicklung von Makros würde diese Form der Tests eher hinderlich sein. Abhilfe
schafft da macroexpand-1, die eine Stufe von Makros in einem (mit einem Quote versehenen)
Ausdruck expandiert.
user> (macroexpand-1 ’(plus-a-b 2 3))
(+ 2 3)
user> (macroexpand-1 ’(plus-a-b 2 (+ 3 4)))
(+ 2 (+ 3 4))
user>
Auch dieses Beispiel zeigt, dass die Schachtelung des zweiten Arguments, eigentlich ja eine
Addition, nicht ausgewertet, sondern als Ergebnis der Makroexpansion zurückgegeben wird.
Noch überraschender mag die folgende Expansion wirken.
user> (macroexpand-1 ’(plus-a-b-print (liefer-2) 5))
Im Makro
(+ (liefer-2) 5)
Der Code des Makros wird evaluiert und die Ausgabe „Im Makro“ erfolgt.
Daran ist zu sehen, dass bei der Definition eines Makros auf die gesamte Sprache
zurückgegriffen werden kann. Im Moment der Verwendung eines Makros kann mit
allem, was Clojure bietet, operiert werden: Datenbanken können geöffnet, Dateien
gelesen und geschrieben werden, bis der neue Quelltext als Resultat des Makros
feststeht. Wer eine größere, in Clojure geschriebene Applikation maßgeschneidert
an seine Kunden ausliefern möchte, kann die Konfiguration des Kunden in seinem
CRM-System ablegen und vor der Auslieferung exakt die benötigten Funktionen
zusammenbauen.
Mit der bisher gezeigten Form der Makrodefinition ist allerdings die Entwicklung
von komplexen Makros schwierig bis unmöglich. Warum muss das Resultat mit list
zusammengebaut werden? Für Listen gibt es eine eigene Read-Syntax, wie Abschnitt 2.6.6
beschrieben hat, warum kann diese nicht verwendet werden? Nun, die Antwort ist: Sie kann,
fast.
(defmacro plus-a-b [a b]
’(+ a b))
user> (plus-a-b 2 3)
java.lang.Exception:
Unable to resolve symbol: a in this context
Das Problem hier ist, dass die übergebenen Argumente nun gar nicht mehr
evaluiert, sondern als Symbol betrachtet werden. Wie bereits in Abschnitt 2.6.6
beschrieben, existiert eine zweite Read-Syntax für Listen, die es erlaubt, innerhalb
der Liste Teile gezielt zu evaluieren. Diese Syntax wird durch das „Syntax-Quote“
genannte Backquote-Zeichen eingeleitet, und die UnquoteEvaluation innerhalb dessen
geschieht mit der Tilde („Unquote“). Andere Lisp-Dialekte verwenden hier üblicherweise
das Komma anstelle der Tilde, aber Komma hat in Clojure die Bedeutung eines
Whitespace und steht somit nicht zur Verfügung. Das obige Beispiel wird damit
zu:
(defmacro plus-a-b [a b]
‘(+ ~a ~b))
user> (plus-a-b 2 3)
5
Abschließend sei darauf hingewiesen, dass die Änderung eines Makros verlangt, dass der
davon abhängige Code neu kompiliert wird. Das ist eigentlich selbstverständlich, da die
Makros ja vor dem Kompilieren zu einer Ersetzung von Code führen, wird aber dennoch gerne
vergessen, weil es nicht so recht zu der sonst so dynamischen Natur der Entwicklung mit
Clojure passen will.
Die Funktion map stellt eine der am häufigsten verwendeten Iterationsmethoden zur
Verfügung. Sie erwartet als erstes Argument eine Funktion und darauf folgend eine oder
mehrere Sequences. Bei der Arbeit mit map merkt man gelegentlich, dass die Funktion im
ersten Argument größer wird als zunächst angenommen. Dann kann eine separate
Funktionsdefinition, sei sie global mit def oder in den lokalen Bindings, Abhilfe
verschaffen. Mit einem Makro könnten wir aber ein vergleichbares Ziel erreichen. Die
Sequence sollte das erste Argument sein und die Funktion das zweite. Das erhöht die
Lesbarkeit.
user> (map inc [1 2 3])
(2 3 4)
(defmacro vmap [coll f]
"Wie map nur verkehrt."
‘(map ~f ~coll))
user> (vmap [1 2 3] inc)
(2 3 4)
user> (macroexpand-1 ’(vmap [1 2 3] inc))
(clojure.core/map inc [1 2 3])
user> (vmap [1 2 3]
(fn [x]
(if (odd? x)
(inc x)
x)))
(2 2 4)
user> (vmap ["Watermelon" "In" "Easter" "Hay"]
(fn [s] (.length s)))
(10 2 6 3)
Bei der Verwendung in den letzten beiden Beispielen fällt auf, dass die Definition der
anonymen Funktion eine unnötige Wiederholung ist und ebenfalls entfallen kann. Alle
Ausdrücke nach der Sequence sollen zusammen als eine Funktion aufgefasst werden. Dazu
brauchen wir nur noch den Namen der Laufvariablen anzugeben, dann kann auch hier ein
einfaches Makro verwendet werden.
(defmacro emap [v coll & body]
"Wie vmap nur ohne Funktion."
‘(map (fn [~v] ~@body) ~coll))
user> (emap x [1 2 3]
(if (odd? x)
(inc x)
x))
(2 2 4)
user> (macroexpand-1 ’(emap x [1 2 3]
(if (odd? x)
(inc x)
x)))
(clojure.core/map (clojure.core/fn [x]
(if (odd? x)
(inc x)
x)) [1 2 3])
In diesem Makro taucht ein neues Konstrukt auf: ~@. Die Tilde signalisiert
bereits, dass an dieser Stelle eine Evaluierung stattfindet. Mit dem At-Zeichen @ wird zudem
erreicht, dass die Bestandteile einer Liste einzeln auftauchen. Hier sind das die Ausdrücke, die
durch die zerlegende Variablenbindung in body gesammelt werden. Die abgebildete
Makro-Expansion verdeutlicht das.
Eine weitere oft gesehene Anwendung ist das komplette Ignorieren von
Fehlern. Klassischerweise heißt dieses Makro ignore-errors, aber für das folgende
Beispiel benennen wir es um. Zunächst wird eine Funktion definiert, deren Aufgabe es
ist, eine Exception zu werfen. Mit einem Makro können wir dann diese Exception
ignorieren.
(defn nimm-bratwurst []
(throw (Exception. "Aua, heiß!")))
user> (nimm-bratwurst)
java.lang.Exception: Aua, heiß!
(defmacro mit-zange [& exprs]
(let [e (gensym)]
‘(try
~@exprs
(catch Exception ~e nil))))
user> (mit-zange
(nimm-bratwurst))
nil
Neu ist in diesem Beispiel die Verwendung der Funktion gensym. Diese Funktion
erzeugt ein neues Symbol, das gefahrlos innerhalb des Makros verwendet werden kann.
Würde die Makrodefinition ein explizit benanntes Symbol verwenden, könnte es zu
Konflikten mit dem Code des Makroanwenders kommen, falls dieser den gleichen Namen
verwendet.
user> (gensym)
G__507
user> (gensym "basis")
basis517
Da die Verwendung von erzeugten Symbolen mit einem Basisnamen in Makros recht häufig
auftaucht, bietet Clojure hier eine Abkürzung an: Ein Hash-Zeichen, an ein Symbol
angehängt, erzeugt ebenfalls ein eindeutiges Symbol. Ein Beispiel für diese Notation folgt
weiter unten.
Wenn Firmen untereinander Belege wie Bestellungen und Rechnungen
austauschen, spielt oft der EDIFACT-Standard [72] eine wichtige Rolle. Dieser beschreibt ein
Dateiformat sowie Struktur und Inhalte für den elektronischen Dokumentenaustausch im
B2B-Bereich, also unter Firmen. Dabei wird die Nachricht in Segmente gegliedert, diese
wiederum werden in Gruppen und Datenelemente weiter untergliedert. Für die Gliederung
werden Zeichen verwendet, die einem üblichen Schema folgen, aber im Prinzip, auch wenn
selten verwendet, in der Nachricht in dem speziellen ersten Segment mit Namen „UNA“
vereinbart werden können.
UNA:+.? ’
UNB+UNOC:3+Gast+Wirt+100325:2349+1++123’
UNH+1+ORDERS:D:96A:UN’
BGM+220+108’
DTM+4:20060620:102’
NAD+BY+++Stefan+Tisch 3++++xx’
LIN+1++Ein Helles:SA’
QTY+1:1’
UNS+S’
CNT+2:1’
UNT+9+1’
UNZ+1+123’
Dieses Beispiel dient weniger dazu, eine korrekte EDIFACT-Nachricht darzustellen, als
vielmehr dazu, den Aufbau einer solchen Nachricht zu verdeutlichen. Eine wichtige
Anmerkung ist, dass die Segmente, die hier zeilenweise dargestellt sind, standardkonform nicht
umgebrochen werden. Die Zeichen mit Sonderrollen sind
-
Hochkomma:
- Segment-Trenner,
-
Doppelpunkt:
- Gruppen-Trenner,
-
Plus:
- Datenelement-Trenner,
-
Fragezeichen:
- Escape-Zeichen,
-
Leerzeichen:
- Leerzeichen und
-
Punkt:
- Dezimalpunkt.
Für ein EDIFACT-verarbeitendes Programm wäre es lästig, bei jeder Datei zu schauen, ob
ein UNA-Segment vorhanden ist und falls ja, dieses zu parsen. Diese immer wiederkehrende
Aufgabe kann ein Makro übernehmen. Für die Entwicklung dieses Makros halten wir uns
zunächst das Ziel vor Augen:
(with-edifact-file [reader-var "msg.edi"]
(mach-etwas)
(lies-von reader-var))
Das Makro soll einen Dateinamen übergeben bekommen, lokal einen Reader mit genannter
Variable dafür zur Verfügung stellen und einen Funktionsrumpf mit einem oder mehreren
Ausdrücken ausführen. Dabei soll hinter den Kulissen dafür gesorgt werden, dass die für diese
Datei geltende EDIFACT-Syntax verwendet wird. Offensichtlich braucht dieses System
zunächst die Defaultwerte.
(def seg-trenn \’)
(def grup-trenn \:)
(def datelm-trenn \+)
(def escape-zeich \?)
Der Einfachheit halber und weil wir die Dateninhalte nicht weiter beachten, ignorieren wir
den Dezimalpunkt und das Leerzeichen. Zudem erzeugen wir uns eine Funktion, die aus einem
gegebenen Reader, in der Regel vom Typ BufferedReader, die ersten neun Zeichen
liest.
(defn lies-neun [rdr]
(apply str (take 9 (repeatedly #(char (.read rdr))))))
user> (use ’(clojure.java [io :only (reader)]))
nil
user> (with-open [rdr (reader "una.edi")]
(lies-neun rdr))
"UNA:+.? /"
user> (with-open [rdr (reader "test.edi")]
(lies-neun rdr))
"UNB+UNOC:"
Dieses Beispiel zeigt, dass die Funktion lies-neun wie erwartet funktioniert. Dazu
verwendet das Beispiel die Funktion reader aus der Bibliothek clojure.java.io, die schnell
und umkompliziert einen BufferedReader bereitstellt. Die beiden Beispieldateien, aus denen
die ersten neun Zeichen ausgelesen werden, enthalten einmal ein UNA-Segment mit einer
Nicht-Standard-Definition für den Segment-Trenner („/“ statt „’“ in una.edi) und einmal
kein solches Segment (test.edi).
Das Makro selbst enthält wenig Überraschendes, aber ein gewisses Maß an Fleißcode, der
auf diese Weise aus dem täglichen Leben verschwindet.
(defmacro with-edifact-file [rdr file & body]
‘(let [~rdr (reader ~file)
kopf# (lies-neun ~rdr)]
(if (.startsWith kopf# "UNA")
(binding [seg-trenn (nth kopf# 8)
grup-trenn (nth kopf# 3)
datelm-trenn (nth kopf# 4)
escape-zeich (nth kopf# 6)]
~@body)
(do
~@body))))
Das Symbol, das als rdr durch den Anwender dem Makro übergeben wird, wird an einen
Reader gebunden; für den internen Gebrauch des Makros wird ein Symbol kopf mit
eindeutigem Postfix erzeugt. An dieses wird lokal der String am Anfang der Datei gebunden.
Falls dieser mit „UNA“ beginnt, werden die weiter oben angelegten Vars dynamisch anhand
der Werte in kopf für die Ausführung der Ausdrücke, die gesammelt im body auftauchen,
gebunden. Falls kein „UNA“ gefunden wird, werden die Ausdrücke im normalen Kontext
ausgeführt.
user> (with-edifact-file strm "una.edi"
seg-trenn)
\/
user> (with-edifact-file strm "test.edi"
seg-trenn)
\’
Mit diesem Makro ist der Anwender die oftmals als lästig empfundene Aufgabe des
UNA-Parsens los und kann nur durch Einsatz des Makros korrektes Verhalten voraussetzen. In
den nächsten Schritten kann er dann Funktionen zum Einlesen von ganzen Segmenten
und zum Zerlegen derselben in ihre Bestandteile schreiben, die die globalen Vars
direkt verwenden können oder aber, im funktionalen Stil, als Parameter übergeben
bekommen.
Es gibt im Wesentlichen zwei Wege, die Entwicklung eines Makros zu realisieren.
Im einfacheren Falle erkennt der Programmierer eine Redundanz in seinem Code
und entwirft dann eine kürzere Form. Hier kann der vorher geschriebene Code als
Template in die Makrodefinition geschrieben werden, und es gilt nur noch, die zu
evaluierenden Elemente zu identifizieren. Eventuell werden noch lokale Symbole erzeugt. Ein
komplizierterer Fall liegt vor, wenn aufgrund von Vorüberlegungen feststeht, dass ein
Makro zur Problemlösung herangezogen werden soll, aber weder die Programmlogik,
die das Makro kapseln soll, noch die neue Ausdrucksform feststehen. In dem Falle
empfiehlt es sich, zunächst die neue Form hinzuschreiben, die nach Definition des
Makros verwendet werden soll. Danach entwirft der Programmierer das „Backend“,
also den Quelltext, der nach der Expansion des Makros im Programm stehen soll.
Nachdem solchermaßen von beiden Seiten auf die Makrodefinition hingearbeitet
wurde, kann dann der defmacro-Ausdruck hingeschrieben werden. Bei komplizierteren
Makros werden noch weitere Funktionen fällig, die bei der Expansion ausgeführt
werden.
Es ist wichtig, zu verstehen, dass Makros kompliziert sind. Ihre Definition lässt sich eher mit
der Weiterentwicklung der Programmiersprache als des eigenen Programms vergleichen. Viele
Lisp-Einsteiger durchlaufen einige typische Stadien:
- Unverständnis, wozu Makros dienen sollen und was sie beispielsweise vom
Präprozessor in C unterscheidet,
- Verständnis und Begeisterung für dieses neue Sprachkonstrukt und
- die Ernüchterung, dass gute Makros schwierig zu entwickeln sind.
Die Erfahrung zeigt, dass viele der Lösungen, die in der zweiten Phase mit Makros
angegangen werden, doch besser mit Funktionen realisiert werden sollten.
Die vermutlich wichtigste Faustregel für Makros ist: Verwende keine Makros.
In Abschnitt 2.12.1 wurde beschrieben, wie Clojure es ermöglicht, Funktionen hinsichtlich der
Anzahl ihrer Argumente zu überladen. Aus der objektorientierten Welt stammt das Überladen
von Funktionen hinsichtlich der Typen der Argumente. Clojure geht dabei noch einen Schritt
weiter und bietet einen flexibleren Mechanismus zum Überladen von Funktionen, bei
dem der Programmierer selbst die Funktion implementiert, die die Entscheidung
trifft, welche Funktion die Aufgabe übernehmen wird. In Clojures Welt heißen diese
speziellen Methoden Multimethods. In diesem Buch verwenden wir den deutschen Begriff
„Mehrfachmethoden“.
Am Beispiel einer einfachen Funktion, die nur ein Argument entgegennimmt, lässt
sich das generelle Verfahren studieren. Eine einfache Implementation der Quersumme einer
(positiven) Zahl, die rekursiv das Ergebnis ermittelt, zeigt der folgende Code. Dieser
verwendet den Befehl recur für die Rekursion, der bereits kurz vorgestellt wurde. In diesem
Falle springt recur mit den zwei Argumenten zurück an die Stelle von loop und setzt dort die
Variablenbindungen x und summe auf die neuen Werte. Rekursion ist Thema des
Abschnitts 2.14.
(defn quersumme [zahl]
(loop [x zahl
summe 0]
(if (< x 9)
(+ summe x)
(recur (int (/ x 10))
(+ summe (mod x 10))))))
user> (quersumme 3)
3
user> (quersumme 34)
7
user> (quersumme 345)
12
Wie die Verwendung am REPL-Prompt zeigt, erfüllt diese Funktion die Anforderungen für
die Eingabe von ganzen Zahlen. Die Implementation hat aber Probleme:
user> (quersumme "99")
java.lang.ClassCastException:
java.lang.String cannot be cast to java.lang.Number
user> (quersumme 345.5)
12.5
Das entspricht nicht den Erwartungen. Im Falle eines Strings, der eine ganze Zahl
liefert, könnte die Quersummen-Funktion intelligent genug sein, um die Zahl aus dem String
zu parsen. Und im Falle von Zahlen mit Nachkommastellen sollte sie einen Fehler
signalisieren.
Ein Weg, das zu realisieren, wäre, die Prüfungen auf den Typ in der Funktion selbst
vorzunehmen und auf die verschiedenen Eingaben zu reagieren. Da das Problem aber
letztlich auf das geeignete Überladen einer Funktion bezüglich ihres Arguments
hinausläuft, erscheint dieses Vorgehen wenig elegant. Besser wäre eine Lösung, die
anhand des Typs auf die passende Implementation zurückgreift. Ebendas lässt sich in
Clojure mit Mehrfachmethoden realisieren. Zunächst wird eine Mehrfachmethode mit
dem Makro defmulti als solche definiert und bekommt eine Dispatch-Funktion
übergeben:
(defmulti quersumme type)
Die Dispatch-Funktion bekommt alle Argumente des tatsächlichen
Funktionsaufrufes übergeben und liefert einen Wert zurück, der bei der Definition der
einzelnen Methoden verwendet wird. In diesem Falle ist die Dispatch-Funktion type und sie
bekommt ein Argument übergeben. Der Rückgabewert der Dispatch-Funktion ist der Typ des
Arguments.
user> (type 345)
java.lang.Integer
user> (type 345.5)
java.lang.Double
user> (type "99")
java.lang.String
Basierend auf diesem Zwischenergebnis lässt sich die Implementation auf die
verschiedenen Typen verteilen. Dazu verwendet Clojure das Makro defmethod,
das den Namen der Mehrfachmethode, den Dispatch-Wert und die Implementation
entgegennimmt.
Die Implementation für ganze Zahlen ist fast exakt die vorherige
Funktionsdefinition, nur dass anstelle von defn nun defmethod Verwendung findet und dass
vor der Liste der Argumente der Dispatch-Wert steht.
(defmethod quersumme Integer [zahl]
(loop [x zahl
summe 0]
(if (< x 9)
(+ summe x)
(recur (int (/ x 10))
(+ summe (mod x 10))))))
user> (quersumme 345)
12
user> (quersumme "2147483647")
46
Die Methode, die die Quersumme von ganzen Zahlen in Strings berechnen kann,
greift auf die Methode für Integer zurück. Zusätzlich verwendet diese Methode den Parser
für Integer aus der Klasse Integer und überprüft deren Ergebnis durch Auffangen
von NumberFormatException, was sie in Form einer hier geeigneter erscheinenden
IllegalArgumentException weiterreicht.
(defmethod quersumme String [zahl-s]
(try
(let [zahl (Integer/parseInt zahl-s)]
(quersumme zahl))
(catch NumberFormatException e
(throw
(IllegalArgumentException.
"String enthaelt kein Int")))))
user> (quersumme "22")
4
user> (quersumme "22.5")
java.lang.IllegalArgumentException:
String enthaelt kein Int
Bleibt noch die Implementation des Fehlerzustandes für alle anderen
Zahlen:
(defmethod quersumme Number [zahl]
(throw (IllegalArgumentException.
"Argument ist keine ganze Zahl")))
user> (quersumme 44.5)
java.lang.IllegalArgumentException:
Argument ist keine ganze Zahl
Glücklicherweise kennt die Multimethod-Maschinerie von Clojure die Hierarchien der
Java-Klassen und sorgt so dafür, dass jegliche Instanz von Number, inklusive BigInteger, einen
Fehler signalisiert, während Integer ein valides Ergebnis erzeugt.
Selbst für den Fall, dass sich diese Beziehung einmal nicht automatisch
auflösen lässt, steht eine Lösung parat. Die Funktion prefer-method kann verwendet werden,
um eine Methode einer anderen explizit vorzuziehen. Dadurch sind keine komplizierten
Algorithmen zur Bestimmung der relevanten Implementation zu verstehen, der Programmierer
entscheidet ad hoc, welche Methode Vorrang haben soll.
Methoden, die einer Mehrfachmethode hinzugefügt wurden, lassen sich mit Hilfe
von remove-method auch wieder entfernen. Der Aufruf dieser Funktion erwartet – ähnlich wie
das Hinzufügen – die Mehrfachmethode und den Dispatch-Wert:
user> (remove-method quersumme String)
#<MultiFn clojure.lang.MultiFn@453c47>
user> (quersumme "22")
java.lang.IllegalArgumentException:
No method in multimethod ’quersumme’ for dispatch value:
class java.lang.String
Für den Fall, dass alle Methoden einer Mehrfachmethode entfernt werden sollen, steht seit
Clojure 1.2 die Funktion remove-all-methods zur Verfügung, die nur den Namen der
Mehrfachmethode erwartet:
user> (remove-all-methods quersumme)
#<MultiFn clojure.lang.MultiFn@453c47>
user> (quersumme 11)
java.lang.IllegalArgumentException:
No method in multimethod ’quersumme’ for dispatch value:
class java.lang.Integer
Die in diesem Abschnitt vorgestellten Mehrfachmethoden zeigen nur den
häufig auftretenden Fall des einfachen Dispatch anhand des Typs eines Arguments.
Mehrfachmethoden sind jedoch deutlich flexibler. Die Dispatch-Funktion bekommt zur
Laufzeit alle Argumente übergeben, die auch an die zu ermittelnde Methode übergeben
werden. Somit kann die Dispatch-Funktion weit mehr als nur den Typ der Argumente
heranziehen. Denkbar ist etwa eine Bibliothek, die Operationen auf Dateien komplett
im Speicher abwickelt, wenn die Dateien ausreichend klein sind; dazu würde die
Dispatch-Funktion die Größe einer als Argument übergebenen Datei heranziehen. In ähnlicher
Weise könnte ein Dispatch auf eine asynchron arbeitende Funktion erfolgen, die
einem Anwender – beispielsweise einer Webanwendung – signalisiert, dass seine
Anfrage etwas länger dauert, wenn abzusehen ist, dass der Anwender eine aufwendige
Berechung in Auftrag gegeben hat. Andernfalls würde die Dispatch-Funktion auf
eine synchron arbeitende Funktion verzweigen, die dem Anwender ohne Umwege
sein Ergebnis liefert. Es sind vielfältige Anwendungen dieser flexiblen Technologie
denkbar.
Die Flexibilität kommt nicht ohne Kosten. Der Mechanismus zum Dispatchen kostet
Zeit. Für den häufigen Fall des einfachen Typ-Dispatches wurden daher auch in
Clojure 1.2 Protocols eingeführt, die in Kapitel 5 vorgestellt werden. Vor dem Einsatz von
Mehrfachmethoden empfiehlt es sich daher, auch jene Möglichkeit in Betracht zu
ziehen.
Für die Verarbeitung von Texten haben sich reguläre Ausdrücke etabliert. Java liefert diese im
Paket java.util.regexp mit, und Clojure greift darauf zurück. Dabei verwendet Clojure eine
eigene Read-Syntax, was vor allem in Bezug auf die Anzahl der Backslashes einen
großen Vorteil gegenüber einer Repräsentation als String bietet. Im Gegensatz dazu
verwendet beispielsweise Emacs Lisp eine String-Syntax, und im Elisp-Code für
den Clojure-Mode erscheint der reguläre Ausdruck für einen Kommentarbeginn
als
(set (make-local-variable ’comment-start-skip)
"\\(\\(^\\|[^\\\\\n]\\)\\(\\\\\\\\\\)*\\)\\(;+\\|#|\\) *")
Das sollte Motivation genug sein, eine eigene Read-Syntax für reguläre Ausdrücke
einzuführen. Für Clojure ist das #"regexp", also der reguläre Ausdruck eingefasst in doppelte
Anführungszeichen mit einem vorangestellten Hash-Zeichen. Funktionsaufruf Alternativ kann ein
regulärer Ausdruck aus einem String mit der Funktion re-pattern erzeugt werden.
In beiden Fällen ist das Resultat eine Instanz von java.util.regexp.Pattern. Das
folgende Beispiel demonstriert die Erzeugung von solchen Instanzen und zeigt auch,
wie bei Verwendung von re-pattern ein Backslash gesondert behandelt werden
muss.
user> (type #"([0-9]\.)")
java.util.regex.Pattern
user> (type (re-pattern "([0-9]\.)"))
java.lang.Exception: Unsupported escape character: \.
java.lang.Exception: Unmatched delimiter: )
;;<< Strg-d druecken>>
java.lang.Exception: EOF while reading string
user> (type (re-pattern "([0-9]\\.)"))
java.util.regex.Pattern
Die Funktion re-matcher erzeugt aus einem regulären Ausdruck und einem
String eine Instanz von java.util.regex.Matcher. Durch wiederholte Anwendung von re-find
auf diesen Matcher können dann alle Treffer extrahiert werden, wobei der Matcher selbst
seinen Zustand speichert.
(def my-text "
1. Regexps haben eine Read-Syntax
2. Clojure hat einige Match-Funktionen
3. Idiomatisch ist eine Lazy Sequence")
(def my-matcher (re-matcher #"[0-9]\." my-text))
user> my-matcher
#<Matcher java.util.regex.Matcher[pattern=[0-9]\.
region=0,111
lastmatch=]>
user> (re-find my-matcher)
"1."
user> my-matcher
#<Matcher java.util.regex.Matcher[pattern=[0-9]\.
region=0,111
lastmatch=1.]>
user> (re-find my-matcher)
"2."
user> my-matcher
#<Matcher java.util.regex.Matcher[pattern=[0-9]\.
region=0,111
lastmatch=2.]>
user> (re-find my-matcher)
"3."
user> (re-find my-matcher)
nil
Der Aufruf von re-find kann aber auch direkt mit dem regulären Ausdruck und dem Text
erfolgen. Dann unterscheidet sich das Verhalten von re-find je nachdem, ob das
Suchmuster Gruppen enthält oder nicht. Im einfachen Falle ohne Gruppen liefert re-find
schlicht den (ersten) Treffer, im aufwendigeren Falle mit Gruppen hingegen einen
Vektor mit dem gesamten Match und darauf folgend den Resultaten der jeweiligen
Gruppen.
user> (re-find #"[0-9]\." my-text)
"1."
user> (re-find #"([0-9]\.) +([^ ]+)" my-text)
["1. Regexps" "1." "Regexps"]
Die Funktion re-find fungiert als Wrapper-Funktion, die im Hintergrund je nach
Aufruf ein Matcher-Objekt mit Hilfe von re-matcher anlegt und die Gruppen des Matches
durch Aufruf von re-groups extrahiert. Die geschilderte Form der Rückgabe als Vektor mit
dem gesamten Match als erstem Element stammt genau von re-groups. Das folgende Beispiel
zeigt dessen expliziten Einsatz, der durch die Funktionalität von re-find nicht notwendig
ist.
user> (let [m (re-matcher #"(.(.).)" "abc")]
(re-find m)
(re-groups m))
["abc" "abc" "b"]
user> (let [m (re-matcher #"(.(..).?)" "abc")]
(re-find m)
(re-groups m))
["abc" "abc" "bc"]
user> (let [m (re-matcher #"(...?)" "abc")]
(re-find m)
(re-groups m))
["abc" "abc"]
user> (let [m (re-matcher #"..." "abc")]
(re-find m)
(re-groups m))
"abc"
Die Funktion re-groups tut auch hinter den Kulissen von re-matches
ihren Dienst. Diese Funktion, deren Name nicht den Plural von „match“ andeutet, sondern auf
die gleichnamige Java-Methode aus java.util.regexp verweist, akzeptiert einen regulären
Ausdruck und einen String als Argumente. Sie erzeugt transparent ein Matcher-Objekt und
prüft, ob der gesamte String auf das Suchmuster passt. Das unterscheidet sie von re-find, das
auch Matches auf Teilstrings betrachtet.
user> (re-find #"." "abc")
"a"
user> (re-matches #"." "abc")
nil
user> (re-matches #"..." "abc")
"abc"
Da Clojure die Regexp-Funktionalitäten direkt von Java erbt, ergibt sich nicht nur eine
Arbeitsweise, die der von Java ähnelt, auch die Schalter für die Feineinstellungen eines
Musters lassen sich übernehmen. Die Dokumentation von java.util.regexp.Pattern beschreibt
die Syntax und die Fähgigkeiten von Javas regulären Ausdrücken ausführlich.
Das Arbeiten mit regulären Ausdrücken geht in kaum einer Sprache so leicht von der Hand
wie in Perl. Auch wenn Edi Weitz [76] mit CL-PCRE [75] aus einer Wette heraus eine
Regexp-Engine geschrieben hat, die die von Perl in Sachen Geschwindigkeit unter speziellen
Bedingungen schlägt. Ein einfaches Beispiel ist ein Parser für Ini-Dateien. Diese haben das
einfache Format
[Abschnitt]
Schluessel1=Wert1
Schluessel2=Wert2
[Anderer-Abschnitt]
NocheinSchluessel=WiederEinWert
Und-so=weiter
Vorgehen bei imperativen Sprachen
Ein Parser in Perl – oder einer vergleichbaren Sprache –
würde außerhalb einer Schleife, die zeilenweise durch die Datei iteriert, eine Variable für den
aktuellen Abschnitt anlegen. Solchermaßen vorbereitet, würde dieser Parser mit regulären
Ausdrücken nach dem Auftreten von Abschnitten (erkennbar an den eckigen Klammern)
suchen, woraufhin diese Variable umgesetzt werden würde. In eine weitere äußere
Variable würde das Programm im Falle von Zeilen, aus denen es – ebenfalls per
Regexp – ein Schlüssel-Wert-Paar extrahieren konnte, die gefundenen Werte unter
Angabe des aktuellen Abschnitts ablegen. Hierfür würde sich ein Hash von Hashes
anbieten.
Dieses Vorgehen ist ohne Veränderliche nicht möglich. Zwar könnte man in Clojure
mit lokalen Referenztypen operieren, die für sich ändernde Zustände entworfen sind, doch das
ist wenig idiomatisch. In der funktionalen Programmierung ist in solchen Fällen oft Rekursion
die passende Antwort.
Zunächst erzeugt der folgende Code eine Beispieldatei.
user> (with-open [out (java.io.BufferedWriter.
(java.io.FileWriter.
"buecher.ini"))]
(binding [*out* out]
(println "[Programming Clojure]")
(println "Autor=Stuart Halloway")
(println "Jahr=2009")
(println "")
(println "[PCL]")
(println "Autor=Peter Seibel")))
nil
Das Beispiel öffnet eine Datei, indem es neue Instanzen von BufferedWriter und FileWriter
erzeugt. Das Makro with-open verwendet die Instanz von BufferedWriter und bindet
kurzzeitig die Variable out daran. Die Verwendung von binding demonstriert, wie die
Bindung von *out* für die Umleitung der Ausgabe von println in die geöffnete
Datei kurzzeitig umgebogen wird. Da with-open intern lokale Variablenbindungen
anlegt, kann in dessen Bindungsdefinitionen nicht direkt *out* verwendet werden.
Das Öffnen wie auch das Schließen der Datei übernimmt das Makro with-open
ebenfalls.
Skizze des rekursiven Parsers
Die generelle Funktionsweise des Parsers skizziert der folgende
Pseudocode.
mit offener Datei:
starte iteration(Zeile, Abschnitt, Akkumulator)
wenn iteration beendet:
liefer Akkumulator
sonst:
wenn Abschnitt gefunden:
rekursion mit neuem Abschnitt
und naechster Zeile
wenn Schluessel-Wert gefunden
rekursion mit neuen Werten in Akkumulator
und naechster Zeile
sonst
rekursion mit naechster Zeile
Formale Rekursion
Rekursionen lassen sich formal beschreiben. Sie beginnen immer mit einem Satz an Startwerten. Diese werden als Arbeitswerte übernommen und vom Programm verwendet. Zum Erreichen des nächsten Schritts existiert eine Vorschrift, wie die Arbeitswerte zu verändern sind. Diese Vorschrift kann den aktuellen Wert verwenden. Bei dieser recht formalen Definition fällt das Detail der Implementation, dass der nächste Schritt im erneuten Aufruf der Funktion besteht, weg.
Funktionsaufruf mit Akkumulator statt Statusänderung
Diese Skizze enthält zwei typische Muster
von rekursiven Lösungen. Zum einen wird aus einer sich ändernden Zustandsvariablen, wie sie
eine prozedurale Lösung verwendet, ein Argument für einen rekursiven Funktionsaufruf. Somit
erfolgt die Veränderung nicht in Form einer Zuweisung an eine Variable mit geeignetem
Geltungsbereich, sondern in Form einer Parameterübergabe. Zum anderen wird ein
Akkumulator verwendet, der ebenfalls einen sich ändernden Zustand widerspiegelt, der aber
zusätzlich am Ende der Rekursion als Ergebnis der gesamten Aufrufkette zurückgeliefert
wird.
Ein Problem der Rekursion – das auch bereits in Abschnitt 2.1.1 beschrieben
wurde – ist, dass sie unter Umständen den Stack, der für Funktionsaufrufe zur Verfügung
steht, überlaufen lässt. Eine häufig anwendbare Lösung sind Endrekursionen, bei denen die
Rekursion nicht an beliebigen Stellen im Funktionsrumpf aufgerufen wird, sondern
nur an den Stellen, an denen die Funktion einen Wert zurückliefern würde. Solche
Rekursionen lassen sich in eine stackschonende Schleife wandeln. Da Rekursion in
der funktionalen Programmierung eine wichtige Rolle spielt, die JVM aber keine
Optimierung solcher endrekursiver Aufrufe erlaubt, geht Clojure seinen eigenen
Weg und definiert zwei spezielle Operatoren: loop und recur. An der Stelle des
Aufrufs von loop erzeugt Clojure dann einen Einstiegspunkt mit lokalen Bindings, der
innerhalb des Rumpfes mit recur erneut angesprungen werden kann. Dabei setzt
recur die neuen Werte für die lokalen Bindings. Zusätzlich zum Sprung an eine
durch loop definierte Stelle beherrscht recur auch den rekursiven Einstieg in eine
Funktion.
Aufgrund der expliziten Ausdrucksweise mit diesen beiden speziellen
Operatoren bevorzugen manche Entwickler mittlerweile sogar diese Variante gegenüber der
klassischen Endrekursion, obwohl sie aus einer Unzulänglichkeit der gewählten Plattform
entstand.
Implementation des Parsers
Eine mögliche Implementation der Lösung verwendet
reguläre Ausdrücke, um die verschiedenen Typen von Zeilen zu erkennen, und gibt
die Ergebnisse der Gruppen der Matches an den nächsten Aufruf der Rekursion
weiter.
user> (with-open [in (java.io.BufferedReader.
(java.io.FileReader. "buecher.ini"))]
(let [sec-re #"\[([a-zA-Z0-9_ -]+)\]"
kv-re #"([a-zA-Z0-9_-]+)=(.*)"]
(loop [x (.readLine in)
sec "Global"
acc {}]
(if (not x)
acc ;; abschliessende Rueckgabe
(let [secm (re-matcher sec-re x)
kvm (re-matcher kv-re x)]
(cond
(.find secm) ;; neue Section
(recur (.readLine in)
(second (re-groups secm))
acc)
(.find kvm) ;; key-value-Paar
(recur (.readLine in)
sec
(assoc-in acc
[sec (nth (re-groups kvm) 1)]
(nth (re-groups kvm) 2)))
;; default ignoriere Zeile
:else
(recur
(.readLine in) sec acc)))))))
{"PCL" {"Autor" "Peter Seibel"},
"Programming Clojure" {"Jahr" "2009",
"Autor" "Stuart Halloway"}}
Im Wesentlichen entspricht dieser Code dem Pseudocode aus der Lösungsskizze. Zu
Beginn werden noch die beiden regulären Ausdrücke zum Erkennen von Abschnitten (sec-re)
und Schlüssel-Wert-Paaren (kv-re) gesetzt; das Auswerten dieser Ausdrücke erfolgt nach
Erzeugen der Matcher-Objekte pro Zeile mit find, und die mit den Gruppen eingefangenen
Informationen werden mit Hilfe von re-groups extrahiert. Wichtig sind die verschiedenen
Stellen des Aufrufs von recur. Das erste Auftreffen steigt in die Rekursion und übergibt die
neue Section als zweites Argument. Das dritte Auftreten ist trivial, da es lediglich die neue
Zeile verändert. Interessant ist das zweite Auftreten, das ein Schlüssel-Wert-Paar an den
Akkumulator anhängt:
(assoc-in acc
[sec (nth (re-groups kvm) 1)]
(nth (re-groups kvm) 2))
Für das Verständnis dieses Aufrufs hilft ein Experiment an der REPL.
user> (let [a {"sec1" {"k1" 1, "k2" 2}
"sec2" {"k3" 3}}]
(assoc-in a ["sec2" "k4"] 4))
{"sec1" {"k1" 1, "k2" 2}, "sec2" {"k4" 4, "k3" 3}}
Dieser Ausdruck definiert sich unter dem Namen a zum Testen eine Map,
die Maps enthält. An die Funktion assoc-in, die für die Manipulation von tiefer
geschachtelten Strukturen entworfen ist, wird nach der zu betrachtenden Map ein Vektor mit
Schlüsseln übergeben. In diesem Falle ist das ein Vektor aus den Elementen „sec2“
und „k4“. Der mit diesem Pfad zu assoziierende neue Wert, „4“, folgt als drittes
Argument.
Dieses nicht ganz leicht verdauliche Beispiel hat die Verwendung von Rekursion
zum Lösen eines Problems, das Zustandsänderungen benötigt, demonstriert. Im Java-Umfeld
wird man aber üblicherweise mit einem engen Verwandten der Ini-Dateien in Berührung
kommen: Properties. Diese lassen sich auch deutlich leichter lesen (das Makro doto wird in
Abschnitt 4.1.1 beschrieben):
user> (doto (java.util.Properties.)
(.load
(java.io.BufferedReader.
(java.io.FileReader.
"/etc/java-6-sun/net.properties"))))
#<Properties {java.net.useSystemProxies=false}>
Das ist kurz und prägnant. Gibt es eine gängige Lösung zu einem Problem in
Java, ist das eine idiomatische Lösung in Clojure. Erscheint der rekursive Code zu
unübersichtlich, kann für diesen Teilbereich eines Programms auch eine Java-Klasse
geschrieben und aus Clojure verwendet werden.
Jedes Symbol sowie Clojures eigene Datenstrukturen können mit Metadaten versehen werden.
Darüber hinaus bieten auch die veränderlichen Referenztypen ein Interface für Metadaten. Der
Begriff „Metadaten“ bezeichnet eine Sammlung von Schlüssel-Wert-Paaren, die nicht zu dem
eigentlichen Dateninhalt gezählt wird, sondern unabhängig davon existiert. Dieser
Abschnitt beschreibt zunächst die Verwendung von Metadaten, beleuchtet dann
die technischen Hintergründe und geht abschließend auf einige Anwendungsfälle
ein.
Der Inhalt der Metadaten hat keinen Einfluss auf den Vergleich von Daten. Zwei
Vektoren mit den Werten eins, zwei und drei sind gleich (im Sinne von Abschnitt 2.9),
auch wenn sich ihre Metadaten unterscheiden; gleichwohl sind sie unterschiedliche
Objekte.
Metadaten liegen in Form von Maps vor, woraus sich folgern lässt, dass auch
Metadaten unveränderlich sind. Sie werden einmal bei der Anlage einer Datenstruktur erzeugt
und sind dann Bestandteil dieser Datenstruktur. Es gibt keine Möglichkeit, sie wieder zu
verändern.
Die Anlage und Zuweisung zu einem Objekt erfolgt mit Hilfe
der Funktion with-meta, zum späteren Auslesen dient meta. Bei der Anlage wird
zunächst das mit Metadaten zu versehende Objekt angegeben, danach die Map mit den
Metadaten.
user> (def m (with-meta ["Objekt" "mit" "Meta"]
{:meta-schluessel "wert"}))
#’user/m
user> (meta m)
{:meta-schluessel "wert"}
Dabei ist zu beachten, dass die Argumente von with-meta evaluiert
werden, da es eine Funktion ist. Das folgende Beispiel zeigt dies anhand einer Ausgabe mit
println.
(defn haste-mal-ne-map []
(println "Hier haste ne Map")
{:landkarte "Schweiz"})
user> (def o (with-meta (haste-mal-ne-map)
{:mein-meta true}))
Hier haste ne Map
#’user/o
user> o
{:landkarte "Schweiz"}
user> (meta o)
{:mein-meta true}
Für die Analyse, wie Vergleiche von Objekten mit Metadaten vonstatten gehen,
erzeugt das nächste Beispiel zwei Vektoren mit gleichen Inhalten, aber unterschiedlichen
Metadaten. Die Inhalte der Vektoren sowie die Metadaten werden angezeigt und
abschließend die beiden Vektoren auf Gleichheit mit = und Identität mit identical?
getestet.
user> (def vec1 (with-meta [1 2 3]
{:beschreibung "Erster Vektor"}))
#’user/vec1
user> vec1
[1 2 3]
user> (meta vec1)
{:beschreibung "Erster Vektor"}
user> (def vec2 (with-meta [1 2 3]
{:beschreibung "inhalt=, meta!="}))
#’user/vec2
user> vec2
[1 2 3]
user> (meta vec2)
{:beschreibung "inhalt=, meta!="}
user> (= vec1 vec2)
true
user> (identical? vec1 vec2)
false
Es ist wichtig, sich vor Augen zu halten, dass hier die Metadaten Bestandteil des Vektors
sind. Sie gehören nicht zu dem Symbol, an das der Vektor gebunden wird. Daher kann auch
mit dem Ausdruck (meta vec1) direkt auf die Metadaten zugegriffen werden, indem das
Symbol vec1 zunächst zur durch das Symbol benannten Var und darauf zum Vektor
evaluiert.
Die meisten Clojure-Entwickler bevorzugen für die Erzeugung von Metadaten
eine Alternative, die durch die Read-Syntax ^ (Caret) gegeben ist.
user> (def vec3 ^{:beschreibung "verwende Read-Syntax"}
[1 2 3])
#’user/vec3
user> vec3
[1 2 3]
user> (meta vec3)
{:beschreibung "verwende Read-Syntax"}
Die Read-Syntax wird dabei auf den jeweils folgenden Ausdruck angewendet, das heißt,
auch im Falle der Definition von vec3 wird die Metadaten-Map dem Vektor und nicht dem
Symbol hinzugefügt. Bedingt durch die Entwicklung der Read-Syntax für die Erzeugung und
das Auslesen von Metadaten (siehe Kasten) ist auch die Verwendung von #^ noch
geläufig.
Kurze Geschichte der Read-Syntax
Vor Version 1.1 von Clojure erlaubte die Read-Syntax mit dem Caret das Auslesen der Metadaten. Diese Form dürfte in vielen älteren Tutorials im Netz zu finden sein. In Version 1.1 hat das Caret nach wie vor diese Arbeit verrichtet, jedoch mit einer Warnung, dass diese Verwendung veraltet sei. Seit Clojure 1.2 steht das einfache Caret ebenso wie die Kombination mit dem führenden Hash-Zeichen für die Erzeugung der Metadaten. Es ist zu erwarten, dass die zweite Form wieder als veraltet markiert werden wird.
Das folgende Beispiel erscheint dagegen unter Umständen zunächst
verwirrend.
user> (def ^{:beschreibung "Huch?"} vec4 [1 2 3])
#’user/vec4
user> (meta vec4)
nil
Was genau geschieht hier? Der Reader findet die Read-Syntax zur Erzeugung von
Metadaten und fügt diese Daten dem folgenden Element hinzu. Das folgende Element ist aber
ein SymbolSymbol, das Symbol mit dem Namen vec4. Somit werden an den Befehl def ein
Symbol mit Metadaten und ein Vektor ohne Metadaten übergeben. Daraufhin legt Clojure
eine Var an, wobei die Metadaten des Symbols kopiert werden, und abschließend wird die
Verbindung zum Vektor hergestellt. Bei der Frage nach den Metadaten von vec4 wird das
Symbol evaluiert, so dass die Frage nach den Metadaten des Vektors gestellt wird.
Dieser enthält aber keine Metadaten. Natürlich lassen sich die bisherigen Beispiele
kombinieren, indem sowohl für das Symbol als auch für den Vektor Metadaten erzeugt
werden:
user> (def ^{:kontext "Meta des Symbols"} vec5
^{:kontext "Meta des Vektors"} [1 2 3])
#’user/vec5
user> (meta vec5)
{:kontext "Meta des Vektors"}
Zurück zum vorigen Beispiel. Es stellt sich die Frage, wie die erzeugten Metadaten wieder
ausgelesen werden können.
user> (meta ’vec4)
nil
user> (meta (resolve ’vec4))
{:ns #<Namespace user>, :name vec4,
:file "NO_SOURCE_PATH", :line 25, :beschreibung "Huch?"}
user> (meta (var vec4))
{:ns #<Namespace user>, :name vec4,
:file "NO_SOURCE_PATH", :line 25, :beschreibung "Huch?"}
user> (meta #’vec4)
{:ns #<Namespace user>, :name vec4,
:file "NO_SOURCE_PATH", :line 25, :beschreibung "Huch?"}
Der erste Versuch, mit Hilfe des Quote-Operators das Symbol zu erhalten
und dessen Metadaten auszulesen, scheitert daran, dass Clojures Reader immer ein neues
Symbol zurückgibt, das dann keine Metadaten enthält. Dieses flüchtige Verhalten von
Symbolen – beschrieben in Abschnitt 2.6.5 – kann Programmierer mit Lisp-Erfahrung
durchaus verwirren. Es ist nach der Verwendung eines Symbols nicht mehr möglich, an
dasselbe Symbol heranzukommen.
Der zweite Versuch hingegen löst das Symbol mit Hilfe von resolve korrekt in
seinem Namensraum auf und findet schließlich die Metadaten, die in die Var kopiert wurden.
Dasselbe gelingt auch mit dem dritten Aufruf. Der letzte Befehl schließlich kombiniert den
Var-Quote-Operator #’ mit dem Zugriff auf die Metadaten, entspricht also dem dritten
Aufruf.
Vars gehören zu Clojures Referenztypen, deren genaue Beschreibung in
Abschnitt 3.4 erfolgt. Da diese nicht unveränderlich sind, können auch ihre Metadaten in
dem Sinne verändert werden, dass sie durch eine neue Map überschrieben werden
können.
user> (reset-meta! #’vec4
{:beschreibung
"So langsam wird es klarer"})
{:beschreibung "So langsam wird es klarer"}
user> (meta #’vec4)
{:beschreibung "So langsam wird es klarer"}
user> (alter-meta! (var vec4)
assoc
:mehrinfo "Jetzt mit Funktion")
{:mehrinfo "Jetzt mit Funktion",
:beschreibung "So langsam wird es klarer"}
user> (meta (var vec4))
{:mehrinfo "Jetzt mit Funktion",
:beschreibung "So langsam wird es klarer"}
Wie das Beispiel zeigt, existieren zwei Funktionen für die Manipulation von Metadaten
veränderlicher Datentypen: reset-meta! und alter-meta. Dabei nimmt reset-meta! eine
neue Map für die Metadaten entgegen, wohingegen alter-meta! eine Funktion als Argument
bekommt. Diese Funktion wird mit den aktuellen Metadaten aufgerufen und liefert eine neue
Metadaten-Map zurück. Im Beispiel wird auf diese Weise ein weiteres Schlüssel-Wert-Paar
hinzugefügt.
Nachdem nun die Mechanismen zur Erzeugung von und zum Zugriff auf
Metadaten sowie im Falle von Referenztypen zur Manipulation beschrieben sind,
bleibt noch die Verwendung von Metadaten zu klären. Welche Anwendungen gibt es
für Clojures Metadaten? Zunächst sind einige Anwendungen bereits durch Clojure
selbst vorgegeben. Wie das Beispiel von vec4 gezeigt hat, erzeugt Clojure selbst
Metadaten.
{:ns #<Namespace user>, :name vec4,
:file "NO_SOURCE_PATH", :line 25,
:beschreibung "Huch?"}
Datei, Zeilennummer und mehr
Hier sind Informationen bezüglich des Namensraums, des
Symbolnamens sowie der Stelle, wo Clojure vec4 gefunden hat, hinterlegt. Da es sich um ein
Experiment an der REPL handelt, liegen keine Informationen über die Quelldatei vor. Die
Zeilennummer gibt aber Auskunft darüber, die wievielte Eingabe an der REPL zu vec4
geführt hat. Ein Beispiel für die Anwendung der Metainformation :file ist der Befehl
source aus dem Namespace clojure.repl (vgl. Abschnitt 6.7). Wenn Clojure selbst
Metadaten erzeugt, haben doch sicherlich auch Clojures eigene Funktionen Metadaten
…
user> (meta #’meta)
{:ns #<Namespace clojure.core>, :name meta,
:file "clojure/core.clj", :line 178, :arglists ([obj]),
:doc "Returns the metadata of obj, [gekuerzt ...].",
:added "1.0"}
Weitere Standardinformationen
Hier finden sich zwei neue Standard-Metainformationen: die
Argumentenliste einer Funktion (:arglist) sowie der Docstring (vgl. Abschnitt 2.4). Die
Funktion zum Addieren zeigt, dass Clojure auch Informationen über das Inlining in den
Metadaten hinterlegt:
user> (meta #’+)
{:ns #<Namespace clojure.core>, :name +,
:file "clojure/core.clj", :line 809,
:arglists ([] [x] [x y] [x y & more]), :added "1.0",
:inline-arities #{2},
:inline #<core$_PLUS___inliner
clojure.core$_PLUS___inliner@69127c4d>,
:doc "Returns the sum of nums. (+) returns 0."}
Ein sehr wichtiger Anwendungsfall ist die konkrete Angabe von Typinformationen
(„Type Hints“), um die Performance zu erhöhen.
user> (def ^Integer ganzzahl 33)
#’user/ganzzahl
user> (meta #’ganzzahl)
{:ns #<Namespace user>, :name ganzzahl,
:file "NO_SOURCE_PATH", :line 108,
:tag java.lang.Integer}
Dafür verwendet Clojure den Metadaten-Schlüssel :tag. Da die Angabe von
Typinformationen eine sehr häufige Anwendung von Metadaten ist, existiert hierfür eine stark
verkürzte Form, die auch in obigem Beispiel verwendet wird: ^Typname. Wie schon
bei der Read-Syntax für das Erzeugen von vollständigen Metadaten existiert hier
die alte Form mit #^. Auch bei der Definition von Funktionen können Argumente
bereits durch Angabe entsprechender Metadaten in der Argumentenliste typisiert
werden.
(defn int-plus [^Integer a ^Integer b]
(+ a b))
Wenn eine Funktion eine Datenstruktur entgegennimmt, in der nur Objekte eines
einzigen Typs erwartet werden, kann die Typinformation als Plural geschrieben
werden.
(defn einfach-mult [werte]
(reduce * werte))
(defn float-mult [^Floats werte]
(reduce * werte))
user> (time (dotimes [_ 1000]
(einfach-mult (range 1000))))
"Elapsed time: 281.683 msecs"
nil
user> (time (dotimes [_ 1000]
(float-mult (range 1000))))
"Elapsed time: 99.402 msecs"
nil
Clojure verwendet also von Haus aus Metadaten für die Kommunikation
mit dem Compiler und für die Dokumentation. Darüber hinaus stehen die Metadaten aber
jedem Programmierer für eigene Zwecke zur Verfügung. Beispielsweise ließe sich – in
Anlehnung an den Tainted-Zustand, den Perl und Ruby mitbringen – an einer Information
speichern, ob sie aus einer nicht vertrauenswürdigen Quelle, wie einer Eingabe in ein
Webformular, stammt. Es ist jedoch zu beachten, dass Metadaten nicht an Zahlen oder Strings
angebracht werden können, da diese Java-eigene Typen sind, die Clojure vollständig erbt und
nicht erweitern kann.
Liste der vorbelegten Schlüssel
Bei der Definition eigener Metadaten sollte auf die in der
folgenden Liste beschriebenen Schlüssel verzichtet werden. da sie bereits intern von Clojure
verwendet werden, also schon eine Semantik besitzen.
-
:private
- – Regelt den Zugriff von außerhalb des Namensraums auf eine Var; Default ist
false
-
:doc
- – Docstring
-
:test
- – Eine Funktion ohne Argumente, die zum automatisierten Testen mit der
Funktion test verwendet werden kann
-
:tag
- – Typinformation
-
:file
- – Information, in welcher Datei die Var definiert wurde; enthält
„NO_SOURCE_PATH“ für Eingaben an der REPL
-
:line
- – Information, in welcher Zeile die Var definiert wurde
-
:name
- – Symbolname
-
:ns
- – Namespace, in dem die Var definiert wurde
-
:macro
- – Boolean-Wert, der angibt, ob die Var ein Makro repräsentiert oder nicht
-
:arglists
- – Argumentenliste oder -listen
Die traditionell wichtigste Datenstruktur in Lisp-artigen Programmiersprachen ist die Cons
Cell. Diese Zellen enthalten jeweils einen Speicherbereich und einen Zeiger auf die folgende
Zelle. Sie implementieren also eine einfach verkettete Liste. Über die Jahrzehnte sind viele
Bilder dieser ebenso einfachen wie effektiven Datenstruktur gezeichnet worden. Eines, das seit
langer Zeit verwendet wird, entstammt der Emacs-Lisp-Referenz [43]:
--- --- --- --- --- ---
| | |--> | | |--> | | |--> nil
--- --- --- --- --- ---
| | |
| | |
--> rose --> violet --> buttercup
Selbstverständlich unterstützen alle Programmiersprachen der Lisp-Familie auch
andere Datenstrukturen, doch die aus Cons-Cells aufgebaute verkettete Liste ist eine
sehr typische Eigenschaft von Lisp, und viele idiomatische Lösungen beruhen auf
ihr.
Schnittstelle, Abstraktion
Wenn man einen Schritt zurückgeht und über diese Struktur
nachdenkt, kommt man fast unweigerlich zu dem Schluss, dass hier vieles auf einem Detail der
Implementation aufbaut. Wesentliche Funktionen der Sprache, Bibliotheken und gängige
Lösungen setzen diese Listenstruktur voraus. Abstrakt betrachtet spielt die Implementation
als eine einfach verkettete Liste jedoch nur eine untergeordnete Rolle. Weitaus bedeutender
erscheint die Schnittstelle: Es gibt Datenstrukturen, die den Zugriff auf das erste
Element und auf den ganzen Rest dahinter unterstützen. Diesen Weg geht Clojure
und definiert mit den folgenden Funktionen eine entsprechende API (im Interface
ISeq):
- first,
- next,
- rest und
- cons.
Die so entstandene Abstraktion trägt in Clojure den Namen Sequence; belassen wir es beim
englischen Begriff. Clojure-Anwender verwenden häufig auch die Kurzform „Seq“,
ausgesprochen wie das englische „seek“ (suchen), und darauf aufbauend „seq-able“ für
Datentypen, die zu einer Sequence gemacht werden können.
Von diesen vier Funktionen erlaubt first den Zugriff auf das erste Element einer Sequence,
next und rest liefern die Sequence hinter dem ersten Element und cons fügt einer Sequence
ein neues Element hinzu. Der Unterschied zwischen next und rest besteht im Verhalten am
Ende einer Sequence. Dort liefert rest den Wert nil zurück und eignet sich somit für logische
Prüfungen und Rekursion besser als next, das eine leere Liste liefert. Interessierte
Programmierer können in RT.java in Clojures Implementation die Funktionen more und next
vergleichen.
Viele verschiedene Datenstrukturen – keineswegs beschränkt auf Clojures
Typen, sondern auch alle Java-Klassen, die das Interface Iterable implementieren – passen zu
der Sequence-Abstraktion und können mit allen Funktionen aus der Sequence-Library
verwendet werden. Das Konzept der Collection aus Java lässt sich ebenfalls auf Sequences
reduzieren, so dass sich alle Java-Klassen, die das Interface Collection implementieren,
ebenfalls wie eine Sequence von Clojure behandeln lassen.
Das folgende Beispiel zeigt die Anwendung der Sequence-Funktionen auf einer Liste,
wie es auch Lisp-Programmierer gewohnt sind.
user> (def trio-lst ’("JaJaJa" "Kummer" "Broken hearts"))
#’user/trio-lst
user> (first trio-lst)
"JaJaJa"
user> (rest trio-lst)
("Kummer" "Broken hearts")
user> (next trio-lst)
("Kummer" "Broken hearts")
user> (cons "Achtung Achtung" trio-lst)
("Achtung Achtung" "JaJaJa" "Kummer" "Broken hearts")
user> (type (next trio-lst))
clojure.lang.PersistentList
Mit Vektoren sind die Ergebnisse nahezu identisch, lediglich die Details der
Implementation als innere Klasse sind bei der Ausgabe von type sichtbar:
user> (def trio-vec ["JaJaJa" "Kummer" "Broken hearts"])
user> (first trio-vec)
"JaJaJa"
user> (rest trio-vec)
("Kummer" "Broken hearts")
user> (next trio-vec)
("Kummer" "Broken hearts")
user> (cons "Achtung Achtung" trio-vec)
("Achtung Achtung" "JaJaJa" "Kummer" "Broken hearts")
user> (type (next trio-vec))
clojure.lang.PersistentVector$ChunkedSeq
Im Falle der assoziativen Datenstrukturen ist jeweils ein Schlüssel-Wert-Paar als ein
Element der Sequence zu betrachten. Dies demonstriert das folgende Beispiel mit einer
Map.
user> (first {:t1 "Achtung Achtung",
:t2 "JaJaJa"})
[:t1 "Achtung Achtung"]
Bei diesen Datenstrukturen ist zu beachten, dass sie ihre Elemente in einer Reihenfolge
anbieten, die von den Details der Implementation abhängt. Ist eine Sortierung nach Schlüsseln
gewünscht, kann zum Beispiel eine sorted-map verwendet werden.
Als Abschluss der Betrachtung des Interface folgt ein letztes Beispiel, das die Seq-barkeit
von Java-Typen demonstriert. Hier kommt ein java.util.Vector zum Einsatz, dem mit der
Methode addElement – wie es Java-Programmierer gewohnt sind – Elemente hinzugefügt
werden. Im Anschluss daran kommen Clojures Funktionen zum Einsatz, wie sie auch schon
zuvor verwendet wurden.
user> (def trio-juv (java.util.Vector.))
#’user/trio-juv
user> (.addElement trio-juv "JaJaJa")
nil
user> (.addElement trio-juv "Kummer")
nil
user> (.addElement trio-juv "Broken hearts")
nil
user> trio-juv
#<Vector [JaJaJa, Kummer, Broken hearts]>
user> (first trio-juv)
"JaJaJa"
user> (rest trio-juv)
("Kummer" "Broken hearts")
user> (next trio-juv)
("Kummer" "Broken hearts")
user> (cons "Achtung Achtung" trio-juv)
("Achtung Achtung" "JaJaJa" "Kummer" "Broken hearts")
Clojures Sequences verfügen über eine Besonderheit: Ihre Elemente werden erst bei Zugriff
realisiert. Diese aus der funktionalen Programmierung bekannte Eigenschaft wird „Laziness“
genannt, im Deutschen wird „Bedarfsauswertung“ oder „nicht-strikte Auswertung“ verwendet.
Clojures Sequences sind also „Lazy Sequences“. Da dieser Begriff im Umfeld von Clojure sehr
häufig verwendet wird, verzichten wir in diesem Buch auf die Verwendung der deutschen
Form.
Referenzielle Transparenz
Diese Form der Auswertung hat vor allem positive Auswirkungen auf
die Performance. Zudem erlaubt sie auch das Erzeugen von eigentlich unendlichen Reihen von
Werten. Negativ macht sich Laziness gelegentlich bei der Fehlersuche bemerkbar, da sie eine
neue Klasse von Fehlern einführt, die auf dem Zeitpunkt der Berechnung beruht. Reine
Funktionen spielen eine wichtige Rolle für Laziness, denn durch ihre fehlenden Nebeneffekte
können sie zu jedem beliebigen Zeipunkt aufgerufen werden. Dadurch werden Ausdrücke, in
denen diese Funktionen verwendet werden, referenziell transparent. Das heißt, dieser Ausdruck
kann jederzeit durch sein Ergebnis ersetzt werden. Siehe auch den Wikipedia-Artikel zu diesem
Stichwort [78]. Bei der Verwendung von reinen Funktionen kommt es in der Regel auch
zu keinen Problemen, so dass die eventuell erschwerte Fehlersuche nicht relevant
ist.
Ein Beispiel mit Nebeneffekten kann zeigen, was es mit Clojures Lazy Sequences auf sich
hat. Dazu erzeugt zunächst range eine Lazy Sequence:
user> (type (range 10))
clojure.lang.LazySeq
user> (range 10)
(0 1 2 3 4 5 6 7 8 9)
Diese kann von der Funktion map, die ihrerseits ebenfalls Lazy Sequences erzeugt,
verwendet werden, wobei die Funktion, die map auf jedes Element der von range erzeugten
Sequence anwendet, als Nebeneffekt eine Ausgabe erzeugen sollte. Der Nebeneffekt ist hier
eine Ausnahme, die zur Demonstration der Laziness dient. Normalerweise sind Nebeneffekte
bei map nicht erwünscht, denn map kommt in der Regel dann zum Einsatz, wenn der
Rückgabewert – die resultierende Sequence – wichtig ist, nicht bei Iterationen für einen
Nebeneffekt.
user> (def abc (map (fn [x]
(printf "<%d> " x)
(* 2 x))
(range 100)))
#’user/abc
An dieser Stelle würde man eigentlich erwarten, dass die Ausgabe bereits erfolgt. Die
Wertzuweisung bei def wird schließlich evaluiert. Das überprüft das folgende Beispiel noch
einmal mit einem println. Dieses wird während der Definition von adam bereits
ausgeführt:
user> (def adam (do
(println "und eval")
"sapfel"))
und eval
#’user/adam
user> adam
"sapfel"
Da an die Var abc jedoch eine Lazy Sequence gebunden wird, findet die
Erzeugung der Elemente zu diesem Zeipunkt noch nicht statt. Erst wenn von der REPL
auf die Elemente einer Lazy Sequence zugegriffen wird, werden diese realisiert; aus
Performancegründen nicht einzeln, sondern in Blöcken (engl. „Chunks“), wie der folgende
Aufruf von take zeigt:
user> (take 2 abc)
(<0> <1> <2> <3> <4> <5> <6> <7> <8> <9> <10>
<11> <12> <13> <14> <15> <16> <17> <18> <19>
<20> <21> <22> <23> <24> <25> <26> <27> <28>
<29> <30> <31>
0 2)
Hier vermischt sich die Ausgabe der von take zurückgelieferten Sequence (0 2)
mit der Ausgabe, die bei der Realisierung der Werte durch den Aufruf von printf
entsteht.
In einem fiktiven Anwendungsfall könnte der Entwickler einer Bibliothek eine
Testfunktion anbieten, die eine komplizierte Funktion auf die natürlichen Zahlen anwendet.
Gemäß der Leistungsfähigkeit seines Rechners kommt er vielleicht zu dem Schluss, dass der
Test mit den ersten 1000 Zahlen gut funktioniert, und platziert einen Aufruf von range – wie
oben gesehen – in seinem Code. Durch Laziness hat er aber eine Alternative: Er kann seine
Funktion auf eine unendliche Reihe anwenden und es dem Anwender überlassen –
beispielsweise mit Hilfe von take –, so viele Elemente zu realisieren, wie dessen
Maschine verkraftet. Statt range verwendet der Entwickler dann einen anderen
Ausdruck und setzt etwa die Funktion iterate ein, womit er eine unendliche Sequence
erzeugt.
Unendlichkeit und die REPLAchtung beim Testen unendlicher Sequences an der REPL. In der Standardeinstellung würde versucht werden, die komplette Sequence auszugeben, was aus verständlichen Gründen nicht funktioniert. Abhilfe schaffen die Funktion
take oder auch die dynamische Var
*print-length*. Siehe dazu Abschnitt
2.18.4.
Das folgende Beispiel demonstriert die Funktion iterate, die auch bereits in
Abschnitt 2.12.1 zur Anwendung kam.
user> (take 10 (iterate inc 0))
(0 1 2 3 4 5 6 7 8 9)
user> (type (iterate inc 0))
clojure.lang.Cons
Dass der Rückgabewert von iterate vom Typ Cons ist, erscheint ungewöhnlich. Der Grund
dafür ist, dass iterate mit dem Startwert (hier 0) beginnt und den Rest seiner Ergebnisse
lazy erzeugt. Die übergebene Funktion (hier inc zum Erhöhen um 1) wird beim ersten Aufruf
mit dem Startwert aufgerufen, und jeder weitere Aufruf erfolgt mit dem vorherigen Ergebnis.
Als Resultat liefert der Ausdruck mit iterate in obigem Beispiel also die Menge der
natürlichen Zahlen mit 0. Aber alle späteren Elemente werden erst bei Bedarf eben durch
Anwenden von inc erzeugt.
Das oben skizzierte, fiktive Beispiel könnte dann in etwa wie folgt aussehen:
(defn platzhalter-fuer-komplizierte-fn [x]
(* x x))
user> (defn test-komplizierte-fn [n]
(take n (map platzhalter-fuer-komplizierte-fn
(iterate inc 0))))
#’user/test-komplizierte-fn
user> (test-komplizierte-fn 10)
(0 1 4 9 16 25 36 49 64 81)
Es gibt jedoch auch viele Fälle, in denen die Werte einer Sequence wirklich
realisiert werden sollen. Das kann durch einen der Befehle doseq, dorun oder doall
geschehen.
Von diesen ist doseq die komplizierteste. Sie akzeptiert in ihrer Binding-Form eine oder
mehrere Variablenbindungen an Sequences, was zu einer geschachtelten Iteration
führt. Mit diesen Variablenbindungen iteriert doseq dann über alle darauf folgenden
Ausdrücke.
user> (doseq [x (take 5 (iterate inc 0))]
(println "x ist jetzt" x))
x ist jetzt 0
x ist jetzt 1
x ist jetzt 2
x ist jetzt 3
x ist jetzt 4
user> (doseq [x (take 2 (iterate inc 0))
y (take 3 (iterate inc 10))]
(println "x und y sind jetzt" x y))
x und y sind jetzt 0 10
x und y sind jetzt 0 11
x und y sind jetzt 0 12
x und y sind jetzt 1 10
x und y sind jetzt 1 11
x und y sind jetzt 1 12
Deutlich einfacher gestaltet sich der Aufruf der beiden anderen Funktionen, die
sich lediglich darin unterscheiden, ob sie ihr Resultat zurückliefern und dazu die gesamte
Sequence im Speicher realisieren (doall) oder ob es es nur um die Nebeneffekte geht
(dorun).
user> (def schuessel
(doall
(map (fn [x]
(printf "<%d> " x)
(* 2 x))
(range 5))))
<0> <1> <2> <3> <4> #’user/schuessel
user> schuessel
(0 2 4 6 8)
user> (def sieb
(dorun
(map (fn [x]
(printf "<%d> " x)
(* 2 x))
(range 5))))
<0> <1> <2> <3> <4> #’user/sieb
user> sieb
nil
Bei Verwendung von dorun in Verbindung mit map drängt sich die Frage nach
dem Sinn auf. Die Hauptaufgabe von map ist es, aus einer Liste durch Anwenden einer
Funktion auf die Elemente eine neue Liste zu erzeugen. Dieses Ergebnis wird dann durch
dorun verworfen. In den meisten Fällen wird man also doseq dieser Kombination vorziehen
wollen.
Im Sprachumfang von Clojure finden sich viele Funktionen, die mit Sequences in Verbindung
zu bringen sind. Die Dokumentation auf der Clojure-Webseite [28] teilt diese anhand ihres
Verhaltens auf, ob sie aus Sequences neue Sequences erzeugen, mit Sequences arbeiten oder
Sequences anderweitig erzeugen. Wir sehen davon ab, für jede Funktion die Funktionsweise
vorzustellen oder ein aussagekräftiges Beispiel zu ersinnen. Es ist wichtig, diese Funktionen zu
kennen und bei Bedarf auf sie zurückgreifen zu können, ermöglichen sie doch oft die
eleganten (und performanten) Lösungen. Daher stellen wir sie in weitestgehend
alphabetischer Form kurz vor und zeigen im Anschluss daran einige ausgewählte
Beispiele.
-
butlast:
- Liefert alle Elemente bis auf das letzte. Realisiert alle Elemente einer Lazy
Sequence.
-
concat:
- Nimmt mehrere Sequences entgegen und liefert eine zurück, die alle einzelnen
Elemente der übergebenen Seqs enthält.
-
cycle:
- Nimmt eine Sequence und wiederholt sie immer wieder. Siehe auch
Abschnitt 2.12.1.
-
distinct:
- Entfernt Duplikate einer Sequence.
-
drop:
- Entfernt die ersten Elemente einer Sequence. Muss alle übersprungenen Elemente
dafür realisieren.
-
drop-last:
- Lässt Elemente am Ende einer Sequence weg, ist aber im Gegensatz zu
butlast weiterhin lazy. Realisiert Elemente am Anfang der Sequence.
-
drop-while, take-while:
- Diese beiden Funktionen erwarten eine Sequence und ein
Prädikat. Dabei ignoriert drop-while alle Elemente am Anfang der Sequence,
solange das Prädikat true zurückliefert, während take-while alle Elemente
einsammelt, solange das Prädikat true liefert. Beide realisieren dazu (mindestens)
die Elemente, auf die sie das Prädikat anwenden.
-
enumeration-seq, iterator-seq:
- Diese beiden Funktionen erstellen Sequences aus
Java-Objekten vom Typ java.util.Enumeration und java.util.Iterator.
-
every?, not-every:
- Das Prädikat every? testet, ob eine Funktion für jedes Element
einer Sequence einen wahren Rückgabewert hat. Dieses Ergebnis negiert
not-every?.
-
ffirst …:
- Für den Zugriff auf die ersten Elemente stehen abkürzende Funktionen bereit,
die die ersten Kombinationen aus next und first zusammenfassen. So ist (ffirst
s) gleichbedeutend mit (first (first s)). In gleicher Form existieren fnext
((first (next s))), nfirst und nnext.
-
file-seq, line-seq:
- Diese beiden Funktionen ermöglichen den Zugriff auf Dateien und
Verzeichnisse sowie auf die Zeilen einer Datei in Form von Sequences. Dabei ist
allerdings zu beachten, dass diese nicht frei von Nebeneffekten sind. Eine Lazy
Sequence auf den Zeilen einer Datei kann nur so lange Zeilen liefern, wie die Datei
geöffnet ist.
-
interleave:
- Verwebt zwei oder mehr Datenstrukturen. Das Resultat beginnt mit dem
ersten Element des ersten Arguments, verwendet darauf die ersten Elemente der
weiteren Argumente und iteriert dieses Verfahren für alle weiteren Elemente.
Sobald eine der übergebenen Datenstrukturen keine Elemente mehr liefert, endet
auch das Resultat. Somit lässt sich interleave auch mit unendlichen Sequences
einsetzen.
-
interpose:
- Setzt zwischen alle Elemente einer Sequence ein weiteres Element.
-
into:
- Erwartet zwei Sequences und fügt alle Elemente der zweiten in die erste ein. Wird
gelegentlich mit einer leeren ersten Seq verwendet.
-
not-any?:
- Testet, ob ein übergebenes Prädikat für kein Element einer Sequence einen
wahren Rückgabewert liefert.
-
partition:
- Ordnet die Elemente eine Sequence zu einer Sequence von Vektoren an, die
sich auch überlappen können. Kommt oft zum Einsatz, wenn benachbarte Elemente
einer Seq gemeinsam betrachtet werden müssen.
-
remove:
- Nimmt ein Prädikat sowie eine Sequence entgegen und liefert eine Sequence
zurück, in der alle Elemente fehlen, für die das Prädikat wahr geliefert hat.
-
reverse:
- Liefert die Elemente einer Sequence rückwärts zurück, ist aber nicht lazy.
-
some:
- Liefert das erste Element einer Sequence, für das das übergebene Prädikat
einen wahren Rückgabewert liefert. Ein häufiger Fehler ist die Verwendung von
contains?, wenn eigentlich some das gewünschte Verhalten an den Tag legt,
insbesondere beim Testen, ob ein Element in einer Liste vorhanden ist.
-
split-at, split-with:
- Die Funktion split-at kombiniert die Funktionen take und
drop und liefert einen Vektor mit zwei Elementen zurück. Das erste Element des
Vektors enthält die ersten Elemente der Sequence und das zweite die restlichen. Im
Unterschied zu split-at, das an einer Position trennt, entscheidet split-with
die Trennstelle mit Hilfe einer Funktion. Es verwendet also take-while und
drop-while.
-
sort-by:
- Bei einer Sequence, die nicht aus einfachen Datentypen, sondern
aus zusammengesetzten besteht, kann diese mit sort-by auf Basis eines
Schlüsselwertes sortiert werden. Dazu kann eine Funktion angegeben werden, die
aus jedem Element der Sequence die zu vergleichende Information extrahiert.
Optional kann eine Vergleichsfunktion angegeben werden, wenn der Default
compare nicht zum gewünschten Ziel führt.
-
…
- Diese Liste ließe sich noch weiterführen.
Für all diese Funktionen gilt, dass ihre Dokumentation mit Hilfe von doc gelesen werden
sollte. Danach helfen viele Experimente an der REPL beim genauen Verständnis der
Arbeitsweise. Auch ein Blick auf die Webseite von Clojure ist empfehlenswert, da
die hier vorgestellte Liste nicht vollständig ist. Die folgende Sitzung an der REPL
demonstriert einige der Funktionen. Kommentare im Beispiel dienen zum besseren
Verständnis.
;; trivial: concat
user> (concat [1 2 3] ’(A B C)
{:samson "uiuiui" :tiffy "rosa"})
(1 2 3 A B C [:samson "uiuiui"] [:tiffy "rosa"])
;; drop, take und split:
user> (drop-while #(< % 5) (range 10))
(5 6 7 8 9)
user> (take-while #(< % 5) (range 10))
(0 1 2 3 4)
user> (split-with #(< % 5) (range 10))
[(0 1 2 3 4) (5 6 7 8 9)]
;; Eine Seq aus Java Properties
user> (doseq [it (take 4 (reverse (System/getProperties)))]
(println (.getKey it) "=" (.getValue it)))
sun.cpu.isalist =
sun.desktop = gnome
sun.cpu.endian = little
sun.io.unicode.encoding = UnicodeLittle
;; 0 zwischen die Ziffern 0-9
user> (interpose 0 (range 10))
(0 0 1 0 2 0 3 0 4 0 5 0 6 0 7 0 8 0 9)
;; Komma zwischen Strings, oft folgt darauf str
user> (interpose "," ["Ene" "Mene" "Miste"])
("Ene" "," "Mene" "," "Miste")
;; Sortieren mit Keyword als Key-Funktion
user> (def albums
[{:t "Three Friends" :jahr 1972}
{:t "Acquiring the Taste" :jahr 1971}
{:t "Gentle Giant" :jahr 1970}
{:t "Octopus" :jahr 1972}])
#’user/albums
user> (sort-by :jahr albums)
({:t "Gentle Giant", :jahr 1970}
{:t "Acquiring the Taste", :jahr 1971}
{:t "Three Friends", :jahr 1972}
{:t "Octopus", :jahr 1972})
Ein weiteres Beispiel zeigt ein durchaus typisches Zusammenspiel verschiedener
Seq-Funktionen. Zunächst erzeugt line-seq aus einer Datei, die zeilenweise einige Namen
enthält, eine Sequence von Personen. Ein Abzählreim aus Kindheitstagen wird zunächst als
String aufgeschrieben, dann aber mit der Java-Methode split von String an Leerzeichen
zerschnitten und das resultierende Java-Array mit seq in eine Sequence gewandelt. Das
eigentliche Abzählen erledigen dann cycle, interleave und partition. Ein Abzählreim
eignet sich ohnehin nur dann, wenn die Anzahl der Mitglieder in der Gruppe kleiner ist als die
Anzahl von Wörtern im Abzählreim, daher wird auf die Mitglieder der Gruppe durch Einsatz
von cycle so lange immer wieder mit dem Finger gezeigt, bis das letzte Wort des
Abzählreims erreicht ist. Mit Hilfe von interleave werden die Namen und Abzählwörter
hintereinander aufgereiht, worauf partition sie paarweise zusammenfasst. Der letzte
Schritt, das erste Element des letzten Paares mit last und first zu ermitteln, ist
trivial.
user> (def leute (line-seq
(java.io.BufferedReader.
(java.io.FileReader. "leute.txt"))))
#’user/leute
user> leute
("Jochen" "Frank" "Tim" "Tobias" "Sascha")
user> (def abzaehl-reim
(str "ene mene miste es rappelt in der kiste "
"ene mene meck und du bist weg"))
#’user/abzaehl-reim
user> (def abzaehler
(seq (.split abzaehl-reim " ")))
#’user/abzaehler
user> abzaehler
("ene" "mene" "miste" "es" "rappelt" "in" "der" "kiste"
"ene" "mene" "meck" "und" "du" "bist" "weg")
user> (partition 2 (interleave (cycle leute)
abzaehler))
(("Jochen" "ene") ("Frank" "mene") ("Tim" "miste")
("Tobias" "es") ("Sascha" "rappelt")
("Jochen" "in") ("Frank" "der") ("Tim" "kiste")
("Tobias" "ene") ("Sascha" "mene")
("Jochen" "meck") ("Frank" "und") ("Tim" "du")
("Tobias" "bist") ("Sascha" "weg"))
user> (first
(last
(partition 2 (interleave (cycle leute)
abzaehler))))
"Sascha"
Die Verwendung von Sequences ist oft einer Iteration vorzuziehen. Es ist für den
Clojure-Programmierer wichtig, die Funktionen aus dem Umfeld der Sequences zu kennen und
zu beherrschen. Dieses lässt sich vor allem durch eigene Experimente an der REPL
erreichen.
Clojures Funktionen in Bezug auf reguläre Ausdrücke wurden bereits in Abschnitt 2.13
besprochen. Dort wurde eine wichtige Funktion ausgelassen, da sie zum Themenkomplex der
Sequences gehört: re-seq. Soll ein längerer Textbaustein mit regulären Ausdrücken
durchsucht werden, wird zunächst ein Matcher erzeugt, auf dem so lange die Funktion
re-find aufgerufen wird, bis sie kein wahres Resultat mehr zurückgibt. Diese Schleife lässt
sich in Form einer Sequence komfortabel abbilden. Das erledigt die Funktion re-seq. Genau
genommen liefert re-seq eine Sequence mit den einzelnen Ergebnissen von re-groups
zurück.
user> (re-seq #"." "Hallo")
("H" "a" "l" "l" "o")
user> (re-seq #"(.)." "Sequence")
(["Se" "S"] ["qu" "q"] ["en" "e"] ["ce" "c"])
Idiomatische und elegante Lösungen verwenden in Clojure häufig Lazy Sequences. Der
einfachste Weg, selbst solche Sequences zu erzeugen, ist die Verwendung von Funktionen,
die sie als Resultat liefern. Häufig verwendete Beispiele sind map, iterate oder
repeatedly.
Ein einfaches Rezept für die Erzeugung eigener Lazy Seqs ist die Verwendung von lazy-seq
in Verbindung mit einer Rekursion. In diesem Falle wird schlicht der rekursive Aufruf
zusammen mit dem Erzeugen einer Sequence mit cons in einen Aufruf von lazy-seq gesteckt.
Das folgende Beispiel demonstriert das anhand einer Funktion, die eine Lazy Seq auf den
Bytes einer (geöffneten) Datei liefert.
(defn byte-seq [rdr]
(let [naechstes (.read rdr)]
(when (< -1 naechstes)
(lazy-seq (cons naechstes (byte-seq rdr))))))
Zu beachten ist hier, dass die Datei nicht geschlossen sein darf, bevor die Elemente der
Sequence, die benötigt werden, auch ermittelt wurden. Dies ist ein häufiger Fehler, da
für die hier definierte Sequence die referentielle Transparenz nicht mehr gegeben
ist.
user> (use ’(clojure.java [io :only (reader)]))
nil
user> (with-open [r (reader "buecher.ini")]
(doall
(apply str
(map char
(take 21 (byte-seq r))))))
"[Programming Clojure]"
Dieses Beispiel verwendet die in Abschnitt 2.14 erzeugte Ini-Datei und sorgt mit doall
dafür, dass die Elemente der Lazy Seq auch realisiert werden. Den notwendigen Reader
erzeugt die Hilfsfunktion reader aus dem Namespace clojure.java.io.
Dieser Abschnitt wirft einen Blick in verschiedene, noch nicht vorgestellte Bereiche von
Clojure und enthält Methoden, Konzepte und anderes Material, das wichtig oder interessant
erscheint.
Im Namensraum clojure.core befinden sich über 500 Funktionen, die auf ihren Einsatz in
Programmen warten. Daraus ergeben sich drei natürliche Fragen: Was bewirken all diese
Funktionen? Welche davon brauche ich wirklich? Und wie kommt man auf diese
Zahl?
Davon ist die dritte Frage am leichtesten zu beantworten und gibt gleich zwei Beispiele für
die zweite Frage.
user> (count (ns-publics ’clojure.core))
546
Hier wird die Funktion ns-publics verwendet, um alle
Symbole im Namensraum clojure.core zu finden. Jetzt ist das Ergebnis 545 aber
deutlich größer als die eingangs genannte Zahl von 500 Funktionen. Die Auflösung liegt
darin, dass es im Namensraum zwar fast 550 Symbole gibt, aber nicht alle auch auf
eine Funktion verweisen. Um diese zu finden, ist ein etwas aufwendigerer Ausdruck
notwendig:
(defn safe-deref [x]
(try
(deref x)
(catch Exception e nil)))
user> (count (filter #(fn? (safe-deref %))
(map second (ns-publics ’clojure.core))))
509
Zunächst wird eine Hilfsfunktion definiert, die mit Hilfe von try und
catch den Aufruf von deref absichert. Fehler treten hier nur auf, wenn etwas vorliegt,
das keine Var mit einer Funktionsbindung ist. Diese Fehlerfälle interessieren hier
nicht, und es wird schlicht nil als Ergebnis zurückgegeben, was später gefiltert
wird.
Im folgenden Ausdruck wird erneut die Funktion ns-publics verwendet, deren Ergebnis
aber nicht direkt gezählt, sondern an die Funktion map übergeben wird. Die einzelnen
Elemente von ns-publics sind jeweils eine Kombination aus dem Symbol und der
damit assoziierten Var. Der map-Ausdruck ermittelt dann mit Hilfe der Funktion
second den jeweils zweiten Eintrag, die Var. Die so gesammelten Vars werden an
filter übergeben. Zusätzlich bekommt filter eine Funktion übergeben, die für jedes
Element entscheidet, ob es bleiben darf oder nicht. Diese Entscheidung trifft die
Kombination aus fn? und der Hilfsfunktion safe-deref. Das Resultat dieses Filters ist die
Liste von Funktionen im Namensraum, die dann an count zum Zählen übergeben
wird.
Dieser kleine Exkurs, mit dem die verfügbaren Funktionen im wichtigsten
Namensraum, clojure.core, gezählt werden sollten, hat wichtige typische Konstrukte von
Clojure gezeigt: Kombinationen von map und filter, die Übergabe von Funktionen als
Argumente, das Zählen von Elementen in einer Datenstruktur sowie die Behandlung von
Ausnahmesituationen vermittels try und catch werden in Clojure häufig in dieser Form
verwendet.
Wer sich nun fragt, von welchem Typ die anderen Elemente des Namensraums sind, kann
sich zunächst davon überzeugen, dass es sich größtenteils um Variablen handelt, und sich dann
deren Typ anschauen.
user> (let [alle (apply
hash-set
(map second (ns-publics
’clojure.core)))
fnks (filter #(fn? (safe-deref %))
alle)]
(doseq [t (clojure.set/difference
alle fnks)]
(println t)))
#’clojure.core/*read-eval*
#’clojure.core/*warn-on-reflection*
;; .. Ausgabe verkürzt
#’clojure.core/*3
#’clojure.core/*allow-unresolved-vars*
nil
user> (let [alle (apply
hash-set
(map second (ns-publics
’clojure.core)))
fnks (filter #(fn? (safe-deref %))
alle)]
(doseq [t (distinct
(map #(type (safe-deref %))
(clojure.set/difference
alle fnks)))]
(println t)))
clojure.lang.MultiFn
clojure.lang.RT$1
clojure.lang.Var
clojure.lang.LineNumberingPushbackReader
nil
clojure.lang.Namespace
java.io.OutputStreamWriter
java.lang.Boolean
clojure.lang.PersistentArrayMap
java.lang.String
clojure.lang.RT$3
clojure.core.VecNode
java.io.PrintWriter
clojure.lang.Compiler$CompilerException
java.lang.Integer
nil
Wenn eine Funktion, die auf lokale Variablen zugreift, mitten im Quelltext anonym generiert
und verwendet wird, oder wenn eine Funktion der Rückgabewert einer Erzeugerfunktion ist
und dabei Variablen aus dem lexikalischen Geltungsbereich dieser Erzeugerfunktion
verwendet, spricht man von einer „Closure“, zu deutsch von einem „Funktionsabschluss“. Es
handelt sich dabei um eine Funktion, die den gesamten umgebenden Variablenkontext
bewahrt. Das unterscheidet eine Closure von einem Funktionszeiger in C oder einer internen
Klasse in Java.
Ein einfaches Beispiel ist das Erzeugen einer Funktion, die immer wieder den gleichen Wert
zu einem Parameter addiert. Diese Addierer-Funktion wird von einer anderen Funktion
erzeugt, der der konstante Wert übergeben wird.
(defn erzeuge-addierer [const]
(fn [x] (+ const x)))
user> (def test-addierer (erzeuge-addierer 4))
#’user/test-addierer
user> (test-addierer 6)
10
user> (let [addier-4 (erzeuge-addierer 4)
addier-2 (erzeuge-addierer 2)]
(list
(addier-4 5)
(addier-4 10)
(addier-2 5)
(addier-2 10)
(addier-2 (addier-4 1))))
(9 14 7 12 7)
Hier wird zunächst eine Funktion erzeugt, die mit Hilfe von fn eine neue Funktion
zurückgibt. Dabei kann die zurückgegebene Funktion auf den Parameter const zugreifen, auch
wenn der Geltungsbereich von erzeuge-addierer lange schon verlassen wurde. Die
Funktion, die als Resultat zurückgegeben wird, erhält den lokalen Kontext. Die
Verwendung dieser Funktion demonstrieren die weiteren Aufrufe, die den Rückgabewert
an eine Var mit Namen test-addierer binden und diese Var darauf als Funktion
verwenden.
Im letzten Beispiel werden mit Hilfe der Erzeuger-Funktion zwei Funktionen erzeugt, die
jeweils die Zahl 4 oder 2 zu ihrem späteren Argument addieren. Diese Funktionen werden in
den lokalen Variablen addier-4 und addier-2 gespeichert und danach in verschiedenen
Varianten aufgerufen. Alle Resultate werden in einer Liste gesammelt und als Ergebnis des
gesamten Aufrufs in der REPL ausgegeben.
Die Funktionsweise von Closures ist einfach genug, um schnell verstanden zu werden.
Wie praktisch Closures sind, erfahren die meisten Programmierer, für die dieses Konstrukt neu
ist, erst nach einiger Zeit, dann aber oftmals mit großem Aha-Effekt. Die unspektakuläre
permanente Anwendung von Closures verlangt jedoch eine möglichst einfache Syntax zu ihrer
Erzeugung. Clojure reduziert diesen Aufwand auf ein Mindestmaß, wie die Beschreibungen in
Abschnitt 2.12.1 gezeigt haben.
Funktionen, die ihrerseits Funktionen als Argumente akzeptieren, werden Funktionen höherer
Ordnung genannt. Sie sind ein wichtiges Konstrukt in der funktionalen Programmierung und
auch im Verlaufe dieses Buches schon mehrfach aufgetaucht. So kam beispielsweise die
Funktion map, die eine Funktion auf eine oder mehrere Sequences anwendet, bereits einige
Male zur Anwendung.
Eine weitere, häufig in funktionalem Code verwendete Funktion ist reduce. Diese
Funktion erwartet als Argument zunächst eine weitere Funktion, die ihrerseits zwei
Argumente verarbeiten können muss. Zudem verlangt reduce die Angabe einer
Sequence. Von dieser Wertesammlung nimmt reduce dann die ersten beiden Argumente
und wendet die übergebene Funktion darauf an. Auf das Ergebnis dieses Aufrufs
zusammen mit dem nächsten, noch unbenutzten Element der Sequence wird die
übergebene Funktion erneut angewendet usw., bis die Liste keine unbenutzten Elemente
mehr enthält. Beispielsweise könnte das Maximum einer Liste gefunden werden,
indem mit reduce so lange zwei Werte verglichen werden, bis alle Werte verglichen
wurden.
(defn my-max [x y]
(if (<= x y) y x))
user> (my-max 4 5)
5
user> (reduce my-max [1 4 22 9])
22
Tatsächlich ist es aber umgekehrt so, dass max mit Hilfe von reduce implementiert ist. Das
Studium der Implementation von max in Clojures Quelltext empfiehlt sich, da es eine ziemlich
typische Funktion ist, die mit verschiedener Argumentanzahl definiert ist und den variablen
Aufruf mit Hilfe von reduce löst.
Es gibt noch eine zweite Form von reduce mit drei Argumenten, die vor der Sequence noch
einen Startwert erwartet. Dieser Startwert bildet dann zusammen mit dem ersten Element der
Sequence die Argumente für den ersten Aufruf der Reduktionsfunktion.
In Abschnitt 2.12.1 wurde die implizite Iteration von reduce durch einen Nebeneffekt –
eine Ausgabe mit println – sichtbar. Diese Zwischenergebnisse liefert (seit Clojure 1.2) auch
die Funktion reductions:
user> (reductions
(fn [x y] (str x " " y))
’("ich" "und" "du" "muellers" "esel" "meiers" "kuh"))
("ich" "ich und" "ich und du" "ich und du muellers"
"ich und du muellers esel" "ich und du muellers esel meiers"
"ich und du muellers esel meiers kuh")
Auch Sortieren einer Sequence erfolgt mit Hilfe von Funktionen als Argumenten, die
an sort übergeben werden. Die folgenden Beispiele verwenden durchgehend die explizite
Schreibweise mit fn, natürlich ist auch eine anonyme Funktion mit der entsprechenden
Read-Syntax möglich, in der dann mit %1 und %2 auf die beiden Argumente zugegriffen
werden kann.
user> (sort (fn [a b] (< a b))
[1 4 2 66 43 3 6 7 43 88])
(1 2 3 4 6 7 43 43 66 88)
user> (sort (fn [a b] (> a b))
[1 4 2 66 43 3 6 7 43 88])
(88 66 43 43 7 6 4 3 2 1)
user> (sort < [1 4 2 66 43 3 6 7 43 88])
(1 2 3 4 6 7 43 43 66 88)
user> (sort > [1 4 2 66 43 3 6 7 43 88])
(88 66 43 43 7 6 4 3 2 1)
user> (sort (fn [a b]
(> (.length (str a))
(.length (str b))))
[1 4 2 66 43 3 100 6 7 43 88])
(100 66 43 43 88 1 4 2 3 6 7)
Da < und > schon Funktionen sind, können sie einfach als Sortierkriterium übernommen
werden.
Wenn eine Sequence von komplexen Datenstrukturen anhand eines
Schlüsselwertes sortiert werden soll, kann sort-by verwendet werden. Ein Beispiel dazu wurde
bereits in Abschnitt 2.16.2 gezeigt.
Das Filtern eines Resultats mit filter wurde am Anfang dieses Abschnitts
bereits gezeigt. Gelegentlich spielt filter sehr gut mit Closures zusammen. So ist
es beispielsweise möglich, sich eine Filterfunktion in Form einer Closure geben zu
lassen.
(defn kleiner-filter [n]
(fn [x] (< x n)))
Das Beispiel erstellt eine Funktion, die ihrerseits eine Funktion zurückliefert. Dabei merkt
sich die zurückgelieferte Funktion das als n übergebene Argument. Sie ist also eine Closure.
Auf diese Weise entsteht eine Funktion, die jederzeit wieder verwendet werden kann und die
ihr übergebene Argumente mit dem gemerkten Wert vergleicht. Ein Test zeigt, dass es
funktioniert:
user> ((kleiner-filter 10) 5)
true
user> ((kleiner-filter 10) 11)
false
Im folgenden REPL-Experiment wird zunächst eine Sequence mit zufälligen
Zahlen erzeugt, die als zu filternder Datenbestand dienen. Die zuvor definierte Funktion
kleiner-filter wird verwendet, um eine Funktion zu definieren, die auf „Kleinerheit“
gegenüber der Zahl 30 testet, und mit dieser Closure-Funktion findet filter die Zahlen, die
kleiner als 30 sind.
user> (def daten
(take 10 (repeatedly #(rand-int 100))))
#’user/daten
user> daten
(13 96 16 72 87 22 27 14 70 48)
user> (def kleiner-30 (kleiner-filter 30))
#’user/kleiner-30
user> (filter kleiner-30 daten)
(13 16 22 27 14)
user>
Funktionen, die Funktionen erzeugen
Ein solches Vorgehen ist nicht auf selbst geschriebene
Funktionen, die Closures zurückliefern, beschränkt. Clojure selbst bringt einige solcher
Funktionen mit. Beispielsweise verkehrt complement eine Prüfung ins Gegenteil, wie das
folgende Beispiel zeigt, das die bisherigen Beispiele weiterführt.
user> (def groesser-40 (complement
(kleiner-filter 40)))
#’user/groesser-40
user> (filter groesser-40 daten)
(96 72 87 70 48)
Nur dem Namen nach eng verwandt mit complement ist comp. Die Funktion von
comp ist die Komposition mehrerer Funktionen zu einer einzigen Funktion. Das Beispiel am
Anfang dieses Abschnitts, das alle Funktionen aus dem Namensraum clojure.core ermittelt
hat, könnte mit Hilfe von comp eleganter geschrieben werden:
user> (count (filter (comp fn? safe-deref second)
(ns-publics ’clojure.core)))
509
Die Filterfunktion wird hier mit Hilfe von comp aus den Einzelfunktionen fn?, safe-deref
und second erzeugt. Die resultierende Funktion entspricht also gerade dem folgenden
Aufruf.
(fn? (safe-deref (second %)))
Im Rahmen der funktionalen Programmierung geht es oft darum, die richtigen Funktionen
zu finden. In der täglichen Arbeit mit Clojure wird der eine oder andere vielleicht feststellen,
dass er mehr nachdenkt als bei anderen Sprachen, dafür aber auch sehr viel kompakteren und
aussagekräftigeren Code schreibt.
Eine triviale Funktion liefert constantly zurück: eine Funktion, die immer wieder
denselben Wert zurückgibt.
user> (def immer-gleich (constantly "gleich"))
#’user/immer-gleich
user> (immer-gleich)
"gleich"
user> (immer-gleich)
"gleich"
Eine Anwendung von constantly wird das Beispiel in Abschnitt 3.8 zeigen, in
dem constantly verwendet wird, um einen Agent auf einen konstanten Wert zu
setzen.
Mit juxt steht Clojure-Programmierern eine Funktion zur Verfügung, die eine Liste
von Funktionen entgegennimmt und eine neue zurückliefert, die bei Aufruf einen
Vektor der Ergebnisse der einzelnen Funktionen zum Resultat hat. Dabei müssen
die einzelnen Funktionen in der Lage sein, die Argumente des späteren Aufrufs zu
verarbeiten.
(defn f0 [] "f0")
(defn g0 [] "g0")
(defn h0 [] "h0")
user> (def j0 (juxt f0 g0 h0))
#’user/j0
user> (j0)
["f0" "g0" "h0"]
(defn f1 [x] (str "f1" x))
(defn g1 [x] (str "g1" x))
(defn h1 [x] (str "h1" x))
user> (def j1 (juxt f1 g1 h1))
#’user/j1
user> (j1 "-> ein arg")
["f1-> ein arg" "g1-> ein arg" "h1-> ein arg"]
Im Bereich mathematischer Berechnungen lassen sich so Abbildungen ℝn → ℝm kompakt
abbilden. Eine weitere Anwendung für juxt liegt dann vor, wenn auf einer Sequence mehrere
Operationen in einem Durchlauf ausgeführt werden sollen. So kann in einem Rutsch aus einer
Menge von Zahlen sowohl das Minimum als auch das Maximum ermittelt werden. Da weder
min noch max eine Sequence direkt als Argumente akzeptieren, muss auf apply zurückgegriffen
werden.
user> (def data [1 2 3 5 4 3 2 6])
#’user/data
user> (def minmax (juxt #(apply min %)
#(apply max %)))
#’user/minmax
user> (minmax data)
[1 6]
Die letzte Funktion in dieser Liste von Funktionen, die Funktionen erzeugen, ist partial.
Die Aufgabe dieser Funktion ist es, die Argumentenliste einer anderen Funktion vorab
teilweise auszufüllen. Das folgende Beispiel erzeugt mit partial eine Funktion auf
Basis von assoc, für die sowohl die Map als auch der Schlüssel bereits festgelegt
sind.
user> (def zentrale
{:durchwahl 0
:fax 99
:aktiv "Iris"})
#’user/zentrale
user> (def zent-dienst (partial assoc zentrale
:aktiv))
#’user/zent-dienst
user> (zent-dienst "Andrea")
{:durchwahl 0, :fax 99, :aktiv "Andrea"}
user> (zent-dienst "Sylvia")
{:durchwahl 0, :fax 99, :aktiv "Sylvia"}
Dieses Verfahren ist dem Currying sehr ähnlich. Der kleine Unterschied liegt darin, dass
beim Currying das Resultat und keine Funktion zurückgegeben wird, sobald alle Argumente
feststehen. Das ist im Falle von Clojure aber meist nicht erkennbar, da viele Funktionen eine
variable Anzahl von Argumenten verarbeiten können.
CurryDie Methode des
Currying ist nach
Haskell Curry benannt, der auch Namensvater der funktionalen Programmiersprache Haskell ist. Wer kann schon von sich sagen, mit Vor- und Nachnamen Namensgeber wichtiger Technologien zu sein? Wenngleich wir als
Göttinger eine gewisse Verbundenheit mit ihm verspüren – hat er doch seine Arbeiten an der kombinatorischen Logik, die als Grundlagen der funktionalen Programmierung angesehen werden, während seiner Promotion bei
David Hilbert in Göttingen begonnen –, so gebührt die Ehre eigentlich den ebenfalls in Göttingen tätigen
Gottlob Frege und
Moses Schönfinkel. Und
„schönfinkeln“ ist doch eine wunderbare Bezeichnung.
Das Konstrukt der List Comprehensions, für das uns keine geeignete Übersetzung bekannt ist,
stammt aus der funktionalen Programmierung und lehnt sich an die Beschreibung von Mengen
aus der Mathematik an. Als Beispiel diene die Menge aller Quadrate aller natürlichen
Zahlen, die kleiner oder gleich 10 sind. Mathematiker schreiben dies in der folgenden
Form:
 | (2.1) |
MengenDahinter steht, dass aus einer Menge von Zahlen – hier der natürlichen Zahlen – eine
neue Menge gebaut wird, wobei die erste Menge durch eine weitere Eigenschaft oder ein
Prädikat – hier kleiner oder gleich 10 – eingeschränkt wird. Zudem werden die Werte der so
eingeschränkten Menge noch durch eine Funktion abgebildet. Eine Liste, gefiltert mit einem
Prädikat, erzeugt eine neue Liste von modifizierten Werten. Dieses Konstrukt nennt die
funktionale Programmierung „List Comprehension“.
In Clojure übernimmt das Makro for diese Aufgabe.
user> (take 10 (for [x (iterate inc 0)
:when (<= x 10)]
(* x x)))
(0 1 4 9 16 25 36 49 64 81)
Da das Prädikat – hier mit dem Schlüsselwort :when definiert – logisch zwar die von
iterate erzeugte Seq einschränkt, die Ausführung aber nicht unterbricht, erzeugt Clojure eine
im Prinzip unendliche Sequence. Somit ist die Verwendung von take angebracht. Alternativ
könnte die ursprüngliche Liste auch mit Hilfe von range erzeugt werden, wobei dann aber
Prädikat und Ursprungsliste vermischt wären.
In der Regel lässt sich das gleiche Resultat auch durch Verwendung von map und filter
verwenden. Die komprimierte Schreibweise von for macht das Konstrukt jedoch oft leichter
lesbar.
In der Binding-Form von for können mehrere Variablenbindungen
angelegt werden, was zu einer geschachtelten Iteration führt.
user> (for [x (range 4)
y ["A" "B"]]
[x y])
([0 "A"] [0 "B"]
[1 "A"] [1 "B"]
[2 "A"] [2 "B"]
[3 "A"] [3 "B"])
Viele Neueinsteiger in Programmiersprachen der Lisp-Familie haben eine Abneigung gegen die
mitunter tief geschachtelten Ausdrücke. Clojure begegnet dem mit dem „Fädeloperator“
(engl. „threading operator“, auch „thrush operator“; die Übersetzung hier ist als Vorschlag zu
betrachten), der als Makro implementiert ist und es erlaubt, Lisp-Ausdrücke „von innen nach
außen“ zu schreiben. Das Makro nimmt sein erstes Argument und stellt es als zweites
Element in seinem zweiten Argument zur Verfügung. Wenn das zweite Argument noch
keine Liste ist, wird es zu einer gemacht. Wenn weitere Argumente folgen, wird mit
dem kompletten zuvor erbauten Ausdruck so verfahren wie zuvor mit dem ersten
Argument. Diese Schreibweise entspricht eher der in Java üblichen Aneinanderreihung von
Methodenaufrufen. Der einfache Fall einer Erzeugung einer zufälligen ganzen Zahl zeigt den
Unterschied.
user> (rand-int 10)
8
user> (-> 10 rand-int)
7
In diesem Beispiel bringt das aber keine Verbesserung weder der Lesbarkeit noch
bezüglich der Länge des Codes. Interessant wird es meist erst, wenn weitere Operationen
folgen, die beim Fädeloperator hintenangestellt werden können, wohingegen die
klassische Lisp-Syntax mehr Klammern und eine tiefere Schachtelung der Ausdrücke
verlangt.
user> (-> 10 rand-int .floatValue)
3.0
user> (-> 10 rand-int .floatValue .toString)
"4.0"
user> (.toString (.floatValue (rand-int 10)))
"9.0"
Gleich zwei Anwendungen von -> zeigt das folgende Beispiel, das die ersten Zeichen aus
einer Datei liest.
user> (with-open [r (java.io.BufferedReader.
(java.io.FileReader.
"/etc/hosts" ))]
(apply str
(take 9 (repeatedly
#(char (.read r))))))
"127.0.0.1"
user> (with-open [r (-> "/etc/hosts"
java.io.FileReader.
java.io.BufferedReader.)]
(apply str
(take 9 (repeatedly
#(-> r .read char)))))
"127.0.0.1"
Diese Beispiele haben als Folgelemente nach dem ersten bislang keine komplexeren
Ausdrücke verwendet, der Operator hat somit jeweils implizit eine Liste erstellt. Die beiden
folgenden Formen sind äquivalent:
user> (-> 3 (* 2) (+ 1))
7
user> (+ (* 3 2) 1)
7
Das Beispiel vom Beginn dieses Abschnitts, das bereits mit Hilfe von comp vereinfacht
wurde, kann ebenfalls mit -> geschrieben werden:
user> (count (filter #(-> % second safe-deref fn?)
(ns-publics ’clojure.core)))
509
Auch wenn das dem Beispiel mit comp sehr ähnlich sieht, handelt es sich
doch um eine gänzlich andere Methode. Vor allem ist -> ein Makro, arbeitet also auf der
Ebene der Ausdrücke. Das wird dann deutlich, wenn die Funktion safe-deref durch einen
entsprechenden Ausdruck ersetzt werden soll, der jetzt im Funktionsrumpf von safe-deref
steht. Dann würde -> versuchen, das vorige Ergebnis als zweites Element in dem Ausdruck
unterzubringen, was unweigerlich scheitern muss. Bei comp entfällt zudem die Notwendigkeit
einer anonymen Funktion – hier mit Read-Syntax erzeugt –, da comp selbst eine Funktion
zurückgibt.
Eine Variante des Fädeloperators ist -», der genauso funktioniert wie ->, mit dem
kleinen Unterschied, dass die vorhergehenden Ergebnisse nicht als zweite, sondern als letzte
Argumente in die folgenden Ausdrücke eingesetzt werden. Für diesen hat sich bislang noch
kein Name etablieren können. „tail threading operator“ wäre eine Variante, die sich an
„tail recursion“ anlehnt, allerdings wäre dann die äquivalente deutsche Übersetzung
„Endfädeloperator“ nach dem noch einigermaßen amüsanten „Fädeloperator“ ein eher
grausiges Wortmonster. Vielleicht sollten diese Operatoren schlicht bei ihren englischen
Bezeichnungen bleiben.
Die Mehrzahl der Funktionen, die mit Sequences arbeiten, erwartet die Sequence als
letztes Argument, so dass in diesem Umfeld häufig diese Form des Fädeloperators angetroffen
wird.
Der Fädeloperator erlaubt sowohl die Verwendung von Java-Methoden als auch
von Clojure-Funktionen, so dass er häufiger dort zum Einsatz kommt, wo man auch den
Dot-Dot-Operator einsetzen könnte (vgl. Abschnitt 4.1.1).
Der Einsatz von -> ist letztlich Geschmackssache, findet sich aber in
ausreichend vielen Quellen, so dass er verstanden werden muss.
Im Normalfall ist die Kommunikation mit Clojure intuitiv, und Clojure macht das, was der
Programmierer erwartet. An manchen Stellen lauern jedoch einige Überraschungen, die auch
davon abhängen, welchen Hintergrund der überraschte Mensch mitbringt. Dann ist es oft
hilfreich, sich vor Augen zu halten, welchen Weg die Eingabe genommen hat, die zu dem
unerwarteten Verhalten führte. Dieser Abschnitt widmet sich daher diesem Weg: von der
Quelldatei oder der REPL-Eingabe bis zur Anzeige des Ergebnisses.
Es ist unproblematisch, diesen Abschnitt beim ersten Lesen zu überspringen, wenn die
darauf folgenden Kapitel allzu verheißungsvoll erscheinen.
Quelltext kann Clojure entweder – wie in Abschnitt 2.3 beschrieben – direkt am
REPL-Prompt oder in Form von Quelltextdateien vorgelegt werden. Zur Übergabe von
Dateien existieren verschiedene Möglichkeiten. Zunächst kann ein passender Aufruf von Java
direkt auf der Kommandozeile erfolgen; die zu lesende Datei wird dabei mit der Option -i
angegeben.
shell> cat quelle.clj
(println "Hello World")
shell> java -cp clojure.jar clojure.main \
-i quelle.clj
Hello World
Das Beispiel gibt auf einem Linux-System mit Hilfe des Programms cat den Inhalt der
Datei quelle.clj aus und führt diesen Code danach aus.
Wenn auf dem System ein ausführbares Clojure-Skript verfügbar ist, ist es
möglich – wie von Interpreter-Sprachen wie Bash, Perl oder Ruby gewohnt –, ein direkt
ausführbares Clojure-Programm mit einem passenden Shebang zu schreiben, sofern das
Betriebssystem dies unterstützt. Dafür macht sich das Skript die wenig bekannte Eigenschaft
von Clojure zunutze, dass #! ebenfalls einen Kommentar bis zum Ende der Zeile
einleitet.
shell> which clj
/usr/local/bin/clj
shell> cat shebang.clj
#! /usr/bin/env clj
(println "Direkt ausführbares Programm")
shell> chmod +x shebang.clj
shell> ./shebang.clj
Direkt ausführbares Programm
An einem REPL-Prompt kann ebenfalls das Laden einer Datei
erfolgen.
user> (load-file "./quelle.clj")
Hello World
nil
Diese Verfahren reichen für einfache Anwendungen aus, die keine Infrastruktur
für die Bibliotheken-Landschaft erfordern. Von Java erbt Clojure aber auch den CLASSPATH,
und aus Clojure können Bibliotheken im Classpath gefunden werden. requireDazu dient der
Befehl require, dem als Argument ein Symbol übergeben wird, das einen Namespace
benennt. Der Name bestimmt dabei in bekannter Manier den Speicherort der Datei,
indem Punkte als Trennsymbole aufgefasst werden, die im Verzeichnisbaum dann
Verzeichnishierarchien entsprechen.
;; verwendet shell-out aus contrib zu Demozwecken statt
;; clojure.java.shell
user> (require ’clojure.contrib.shell-out)
nil
user> (clojure.contrib.shell-out/sh "date" "+%Y")
"2010\n"
Durch die require-Anweisung wird eine Datei shell_out.clj in einem
Unterverzeichnis clojure/contrib im Classpath gesucht. Dabei ist zu beachten, dass das in
Clojure übliche Minus in „shell-out“ in einen Unterstrich im Dateinamen für Java übersetzt
wird, weil ein Minus in Java-Namen nicht auftauchen darf. Diese Regel lässt sich mit
der entsprechenden Methode aus der Klasse Character – isJavaIdentifierPart –
überprüfen:
user> (Character/isJavaIdentifierPart \-)
false
user> (Character/isJavaIdentifierPart \_)
true
Die Umsetzung des Namens eines Namespace in einen validen Namen für ein Java-Package
übernimmt namespace-munge:
user> (namespace-munge ’de.clojure-buch)
"de.clojure_buch"
Nach einem require stehen die neuen Vars – zumeist Funktionen –
mit ihrem voll qualifizierten Namen zur Verfügung, wie das Beispiel durch die Verwendung
von sh demonstriert. Der voll qualifizierte Name besteht aus dem Namen des Pakets, einem
Schrägstrich und dem Namen der Var. aliasBei Vars, die häufig zum Einsatz kommen sollen,
ist das nicht sehr anwenderfreundlich. Eine erste Erleichterung verschafft die Funktion alias.
Mit dieser Funktion lässt sich ein Kurzname für einen Namespace definieren. Als
Vereinfachung lassen sich auch der Aufruf von require und alias zusammenziehen, indem
require in einer Form verwendet wird, die jede zu ladende Bibliothek in einem Vektor
erwartet, in dem zusätzlich das Schlüsselwort :as gefolgt von dem Kurznamen steht. Die
folgenden Aufrufe zeigen das. Sinnvollerweise sollte beim Ausprobieren zwischendrin eine neue
REPL gestartet werden.
user> (require ’(clojure xml))
nil
user> (alias ’x ’clojure.xml)
nil
user> (x/emit {:tag :project,
:content [{:tag :version,
:content ["1.2.0"]}
{:tag :url
:content ["http://clojure.org"]}]})
<?xml version=’1.0’ encoding=’UTF-8’?>
<project>
<version>
1.2.0
</version>
<url>
http://clojure.org
</url>
</project>
nil
;; neue REPL starten
user> (require ’(clojure [xml :as x]))
nil
;; (x/emit {:tag :project, ... } wie oben
;; Ausgabe ebenfalls wie oben
Der implizite Aufruf von alias durch Verwendung von :as ist dem direkten Aufruf
vorzuziehen.
Noch einfacher gestaltet sich der Zugriff auf die Funktionen der geladenen Bibliothek,
wenn dessen Funktionsnamen direkt in den aktuellen Namespace übernommen werden. Dies
lässt sich mit dem Befehl refer erreichen. Im folgenden Beispiel kann daher die Funktion sh
ohne Präfix verwendet werden.
user> (require ’clojure.contrib.shell-out)
nil
user> (refer ’clojure.contrib.shell-out)
nil
user> (sh "echo" "Moin, Moin")
"Moin, Moin\n"
Namenskollisionen vermeiden
Falls es im referenzierten Namensraum Namen gibt, die lokal eine
Kollision auslösen würden oder wenn nur einige wenige Symbole importiert werden sollen,
helfen die weiteren Argumente von refer, die mit den Schlüsselwörtern :exclude, :only und
:rename die Kontrolle über zu importierende Symbole erlauben. Es gilt als guter Stil, beim
Importieren von Symbolen so explizit wie möglich zu sein, also wirklich nur die Symbole
zu importieren, die auch verwendet werden. Somit sollte der Gebrauch von :only
oft erfolgen, die Schlüsselwörter :exclude und :rename sollten jedoch sehr selten
auftauchen.
Da die Kombination von require und refer sehr häufig benötigt wird,
existiert auch ein kürzerer Weg zum gleichen Ziel: der Befehl use. Bei der Definition eigener
Namespaces mit Hilfe des Makros ns sollte der Verwendung des Schlüsselwortes :use auch in
der Definition des Namespace Vorzug gegeben werden. Die explizite Verwendung von use ist
eher an der REPL üblich.
user> (use ’clojure.contrib.strint)
nil
user> (resolve ’<<)
#’clojure.contrib.strint/<<
user> (<< "Namespace: ~{*ns*}")
"Namespace: user"
Mehrere Bibliotheken laden
Im Hintergrund von use arbeitet nach wie vor die Funktion require,
die noch einige Argumente mehr versteht. So lassen sich mehrere Bibliotheken in einem
einzigen Befehlsaufruf zusammenfassen, und wenn die Bibliotheken ein gemeinsames Präfix
wie beispielsweise „clojure.contrib“ haben, braucht das nur einmal angegeben zu
werden.
user> (use ’(clojure.contrib base64))
nil
user> (clojure.repl/dir clojure.contrib.base64)
*base64-alphabet*
encode
encode-str
user> (resolve ’encode)
#’clojure.contrib.base64/encode
Der Name der Base64-Kodierfunktion encode ist sehr generisch und kann leicht zu
Konflikten mit anderen Bibliotheken führen, gleichzeitig ist es aber lästig, ständig auf
clojure.contrib.base64/encode zuzugreifen. Dafür kann dem importierten Namensraum
mit dem Schlüsselwort :as ein Kurzname gegeben werden. Obiger Aufruf hätte mit dem
Kurznamen „b64“ wie folgt ausgesehen:
user> (use ’(clojure.contrib [base64 :as b64]))
nil
user> (resolve ’b64/encode)
#’clojure.contrib.base64/encode
Wenn eine Bibliothek bereits geladen wurde, erkennt das der
require-Befehl und vermeidet ein erneutes Laden. Das ist auch in der Regel das, was
Programmierer und Anwender möchten. Allerdings ist es wenig hilfreich, wenn gerade die zu
ladende Bibliothek entwickelt wird. Dann helfen die Flags :reload und :reload-all, die ebenfalls
an require und use übergeben werden können. Das einfache :reload bewirkt, dass
die gesamte Bibliothek tatsächlich neu geladen wird. Bei :reload-all betrifft das
auch die Bibliotheken, die eventuell von der ersten noch nachgeladen werden. Mehr
InformationEin letztes Flag ist :verbose, das ausführlich Auskunft über den Ladevorgang
gibt:
user> (use :verbose ’(clojure.contrib (math :as mth)))
(clojure.core/load "/clojure/contrib/math")
(clojure.core/in-ns ’user)
(clojure.core/alias ’mth ’clojure.contrib.math)
(clojure.core/refer ’clojure.contrib.math)
nil
Abhängigkeiten in Definition des Namespace
Der direkte Aufruf von require und use ist eher
für die interaktive Sitzung an der REPL gedacht. In eigenen Projekten wird man
ohnehin auch einen eigenen Namensraum erzeugen und dann in der Definition des
Namespace mit dem ns-Makro die passenden :require und :use-Direktiven angeben. Deren
Verhalten entspricht exakt dem soeben beschriebenen. Namensräume waren Thema des
Abschnitts 2.7.2.
Nachdem der zu betrachtende Quelltext Clojure vorliegt, nimmt der Reader seine Arbeit auf.
Seine Aufgabe ist es, aus den Bytes einer Datei oder eines gelesenen Strings etwas
Evaluierbares für den Clojure-Compiler zu erzeugen. Wieder ausgegeben, ist das Resultat des
Readers dem geschriebenen Quelltext meist wieder sehr ähnlich, allerdings sind Makros und
Reader-Makros aufgelöst. Reader-Makros sind syntaktische Elemente von Clojure, die bereits
durch den Reader aufgelöst werden. Meist handelt es sich dabei um verkürzte Schreibweisen
häufig verwendeter Ausdrücke.
| Tabelle 2.2: | Reader-Makros |
|
|
|
| Zeichen | Name | Bedeutung |
|
|
|
| ’ | Quote | ’x wird umgesetzt zu (quote x). |
|
|
|
| \ | Character | Erzeugt ein Zeichen-Literal.
Vgl. Abschnitt 2.6.3. |
|
|
|
| ; | Comment | Kommentar bis zum Ende der Zeile |
|
|
|
| ^ | Meta | Unterschiedliches Verhalten je nach
Version von Clojure. Erzeugt Metadaten
und expandiert zu einem Ausdruck mit dem
Makro with-meta, ist aber nicht mit diesem
identisch. Vgl. Abschnitt 2.15. |
|
|
|
| @ | Deref | @x expandiert zu (deref x). |
|
|
|
| ‘ | Syntax-Quote | Erzeugt Code-Templates. Diese bestehen
aus neuem Code in Form einer Liste, der
wiederum Abschnitte enthalten kann, die
evaluiert werden. Vergleiche den Abschnitt
über Makros 2.12.3. |
|
|
|
| ~ | Unquote | Bewirkt in einem Code-Template, das
durch Syntax-Quote eingeleitet wurde, die
Evaluation eines Ausdrucks. |
|
|
|
| ~@ | Unquote-Splicing | Wie Unquote mit dem Unterschied, dass
eine Liste als Resultat in ihre einzelnen
Bestandteile zerlegt wird |
|
|
|
| # | Dispatch | Dieses Reader-Makro leitet ein längeres
Reader-Makro ein, bei dem anderen Zeichen
eine syntaktische Bedeutung zukommt. |
|
|
|
| |
Tabelle 2.18.2 stellt die vorhandenen Reader-Makros zusammen, deren
Auswertung dem Reader obliegt.
Das letzte Reader-Makro, das Dispatch-Makro, leitet eine erweiterte Sequenz
ein. Diese besteht aus dem Rautenzeichen für den Dispatch, gefolgt von einem weiteren
Zeichen, das die Art festlegt. Tabelle 2.18.2 listet die Dispatch-Makros auf und erklärt ihre
Bedeutung.
Im Verlaufe des Buches sind solche Dispatch-Makros bereits aufgetaucht, zum Beispiel bei
den regulären Ausdrücken, den anonymen Funktionen, aber auch in der Ausgabe der Beispiele,
wenn eine Instanz einer Java-Klasse ausgegeben wurde, die vom Reader nicht wieder
eingelesen werden kann.
user> *out*
#<OutputStreamWriter
java.io.OutputStreamWriter@81b1fb>
user> (read-string
"#<OutputStreamWriter
java.io.OutputStreamWriter@81b1fb>>")
java.lang.RuntimeException:
java.lang.Exception: Unreadable form
Reader-Makros sind mit Vorsicht zu genießen und sollten nur für kurze, einfache
Ausdrücke verwendet werden. Ihre primäre Funktion besteht darin, eine kürzere Schreibweise
für auch anderweitig erreichbare Funktionalität zu erlauben. Das folgende Beispiel
zeigt, dass sich die Read-Syntax für anonyme Funktionen mit der für Maps nicht
verträgt. Zur Lösung des Problems muss mindestens eine Read-Syntax entfernt
werden.
user> (map #(+ 1 %) (range 3))
(1 2 3)
user> (map #({:mehr (+ 1 %)}) (range 3))
java.lang.IllegalArgumentException:
Wrong number of args (0) passed to: PersistentArrayMap
user> (map (fn [x] {:mehr (+ 1 x)}) (range 3))
({:mehr 1} {:mehr 2} {:mehr 3})
user> (map #(hash-map :mehr (+ 1 %)) (range 3))
({:mehr 1} {:mehr 2} {:mehr 3})
| Tabelle 2.3: | Dispatch-Makros |
|
|
| Zeichen | Bedeutung |
|
|
| | |
| #{} | Erzeugt ein Set, vgl. Abschnitt 2.6.6. |
|
|
| #" | Erzeugt reguläre Ausdrücke. Somit sind in den Ausdrücken
weniger Backslashes notwendig. Vgl. Abschnitt 2.13. |
|
|
| #^ | Veraltet. Erzeugt Metadaten und expandiert zu einem
Ausdruck, der with-meta verwendet; ist aber nicht identisch
zu diesem Makro. Vgl. Abschnitt 2.15 und das Reader-Makro
^. |
|
|
| #’ | Dieses Var-Quote genannte Makro expandiert zu einem
Ausdruck mit var: #^x -> (var x). |
|
|
| #() | Erzeugt eine anonyme Funktion, kann nicht geschachtelt
werden. Vgl. Abschnitt 2.12.1. |
|
|
| #_ | Ignoriert den nächsten Ausdruck komplett, ist also ein
Kommentar mit Bezug zur Struktur des Codes im Gegensatz
zum Semikolon, das einen Kommentar in Bezug auf die
Struktur der Datei erzeugt. |
|
|
| #! | Ist ebenfalls ein Kommentar bis zum Ende der Zeile.
Eingeführt, um Shebang-Skripte zu erlauben. |
|
|
| #= | Startet eine Evaluation zur Read-Time. Selten. |
|
|
| #<> | Markiert einen Ausdruck als nicht lesbar. Wird vor allem
in der Ausgabe verwendet, wenn die Ausgabe nicht wieder
gelesen werden kann, beispielsweise bei Java-Klassen. |
|
|
| |
Als Resultat liefert der Reader jeweils einen Datentyp, den Clojures Compiler kennt und
verarbeiten kann. Das folgende Beispiel demonstriert, wie der Reader einen Aufruf der
Funktion println als Liste zurückgibt, ebenso wie den Typ des Rückgabewerts für
Literale.
user> (type (read-string "(println \"Hallo Welt\")"))
clojure.lang.PersistentList
user> (type (read-string "{:a 99 :b 77}"))
clojure.lang.PersistentArrayMap
user> (type (read-string "1"))
java.lang.Integer
user> (type (read-string "’(1 2 3)"))
clojure.lang.Cons
Auffällig ist hier die PersistentArrayMap. An dieser Stelle nimmt der Reader eine
Optimierung vor, indem er für kleine Maps auf eine PersistentArrayMap zurückgreift und erst
ab einer gewissen Anzahl von Elementen tatsächlich eine Hash-Map erzeugt. Im Normalfall
sieht der Entwickler dies jedoch gar nicht.
user> (type {:a 1 :b 2 :c 3 :d 4 :e 5
:f 6 :g 7 :h 8 })
clojure.lang.PersistentArrayMap
user> (type {:a 1 :b 2 :c 3 :d 4 :e 5
:f 6 :g 7 :h 8 :i 9})
clojure.lang.PersistentHashMap
Für Entwickler ohne Lisp-Hintergrund ist es eher ungewöhnlich, dass dieser
Phase eine so große Bedeutung zugemessen wird, die vermutlich am deutlichsten daran
erkennbar ist, dass der Reader auch eigenen Programmen in Form der Funktionen read und
read-string zur Verfügung steht.
user> (read-string "(println \"Hallo Welt\")")
(println "Hallo Welt")
user> (read (java.io.PushbackReader.
(java.io.FileReader.
(java.io.File.
"./shebang.clj"))))
(println "Direkt ausführbares Programm")
user> (read-string "’(1 2 3)")
(quote (1 2 3))
Das Beispiel verwendet die Datei shebang.clj, deren Inhalt in einem Beispiel im vorigen
Abschnitt gezeigt wurde. Das letzte Resultat zeigt die Auflösung der dedizierten Read-Syntax
für das Quoten einer Liste. Diesen Schritt führt der Reader für alle seine speziellen
Reader-Makros durch.
In Common Lisp ist es möglich, wenn auch nicht unbedingt
sehr verbreitet, eigene Reader-Makros zu schreiben. Clojure erlaubt das (bislang)
nicht.
Clojures Quelltext ist aus Ausdrücken, oder auch Forms, zusammengebaut, die in der Regel
für ihr Resultat, gelegentlich auch für ihren Nebeneffekt eingesetzt werden. Die Evaluation
einer vom Reader oder anderweitig bereitgestellten Datenstruktur beinhaltet auch eine
transparente Kompilation zu Java-Bytecode, der dann innerhalb der JVM ausgeführt wird.
Insofern ist eine Unterscheidung der Phasen der Kompilation und Evaluation unnötig. Clojure
wird bei Bedarf die Kompilation immer durchführen, eine interpretierte Ausführung findet
in keinem Falle statt. Der Befehl für die Evaluation ist wenig überraschend eval
und kann regulär in normalem Programmcode wie auch an der REPL verwendet
werden.
user> (eval (read-string "(println \"Hallo Welt\")"))
Hallo Welt
nil
user> (eval (read-string "(when true 99)"))
99
user> (eval (read-string "123"))
123
user> (eval (read-string "{:a 1 :b 2}"))
{:a 1, :b 2}
Grundsätze der Evaluation
Im Hintergrund erledigt Clojure eine Menge Arbeit, wenn eine
Datenstruktur evaluiert werden soll. Dabei geht Clojure nach folgenden Grundsätzen
vor:
- Literale wie Strings, Zahlen, Characters und Schlüsselwörter sowie die speziellen
Symbole true, false und nil evaluieren zu sich selbst.
- Symbole werden aufgelöst. Dieser Prozess erfolgt in mehreren Stufen.
- Falls das Symbol bereits vollständig qualifiziert ist, also einen Namensraum
angibt, ist das Resultat die Var, auf die das Symbol im Namensraum
verweist. Beispiele sind System/err oder clojure.core/*err*. Existiert
kein solches Symbol, wird eine Exception geworfen. Symbole in Clojures
Namensräumen haben dabei Vorrang vor Javas Packages, was allerdings
aufgrund der Eindeutigkeit der Namen keine Rolle spielen sollte.
- Das Symbol benennt einen speziellen Operator und wird dementsprechend
verwendet.
- Im aktuellen Namensraum existiert eine Zuordnung zu einer Java-Klasse.
- Im lokalen Geltungsbereich, also zum Beispiel in einer Funktionsdefinition
oder einem let-Ausdruck, existiert eine dem Symbol entsprechende
Variablenbindung.
- Im aktuellen Namensraum wird nach einer Var gesucht, deren Name dem
Symbol gleicht.
- Wenn bis zu diesem Zeitpunkt keine Auflösung erfolgte, gilt das Symbol als
nicht auflösbar, und eine Exception wird geworfen.
Nachdem das Symbol erfolgreich aufgelöst wurde, wird dessen Wert ermittelt, meist
indem die Var dereferenziert wird. Dabei werden eventuell vorhandene Metadaten vom
Compiler ausgewertet, wenn sie spezielle Informationen enthalten, die Clojure intern
verwendet.
- Datenstrukturen wie Vektoren und Maps (auch Metadaten-Maps) evaluieren zu
entsprechenden Datenstrukturen, in denen enthaltene Ausdrücke evaluiert
sind.
- Eine leere Liste evaluiert wieder zu einer leeren Liste (das ist ein Unterschied zu anderen
Lisps).
- Listen mit Inhalt werden als Aufruf interpretiert und je nach ihrem Typ (Funktion,
spezieller Operator oder Makro) ausgewertet.
- Im Falle eines Funktionsaufrufes werden zunächst die Argumente von links nach rechts
ausgewertet.
- Alles, was bis hierhin noch nicht evaluiert wurde, evaluiert zu sich selbst.
Am Beispiel der Auswertung eines Strings lässt sich die Rolle des Readers gut
nachvollziehen, denn eval evaluiert einen String, wie soeben beschrieben, immer als String.
Wenn ein String Clojure-Code enthält, muss der Reader dazwischen seine Arbeit
verrichten.
user> (eval "(println \"Hallo Welt\")")
"(println \"Hallo Welt\")"
user> (eval "(println 33)")
"(println 33)"
user> (eval (read-string "(println 33)"))
33
nil
Die Phase der Evaluation beinhaltet also sowohl die Auflösung von Symbolen als auch das
Ausführen von Anweisungen. Diese liefern ein Resultat zurück, das im weiteren Verlauf
verwendet werden kann.
Das Resultat der Evaluation wird an die aufrufende Funktion übergeben. Wenn diese ihrerseits
evaluiert wird, führen die einzelnen Resultate nach und nach zu einem Gesamtergebnis. Diese
Aufrufkette hat jedoch irgendwann ein Ende. Dieses hängt davon ab, wie die Evaluation in
Gang gesetzt wurde.
Clojures REPL fängt das Resultat der Evaluation ein und gibt es auf *out*
mit Hilfe der Funktion print (siehe Abschnitt 2.8) aus. Dieses Verhalten ist ein
wesentlicher Bestandteil der Arbeit mit einer REPL. Es ist nicht notwendig, eine
Datenstruktur auf der REPL explizit mit print auszugeben, um sie sich anzuschauen.
Die Datenstruktur selbst ist bereits ausreichend: Sie wird gelesen, evaluiert und
ausgegeben.
user> (def gib-mich-aus! ["ich" :bin 1 "Vektor"])
#’user/gib-mich-aus!
user> gib-mich-aus!
["ich" :bin 1 "Vektor"]
Die explizite Ausgabe mit Hilfe einer der Ausgabe-Funktionen erzeugt sogar
ein etwas anderes Resultat.
user> (println gib-mich-aus!)
[ich :bin 1 Vektor]
nil
Das abschließende nil ist der Rückgabewert von println und wird durch die REPL nach
der Evaluation der Funktion ausgegeben.
Die REPL von Clojure merkt sich die letzten drei Resultate sowie die letzte
Exception in den dafür vorgesehenen Variablen *1, *2 und *3 sowie *e. Das kann das
Arbeiten an der REPL vereinfachen, indem es die eine oder andere Wiederholung einer
Eingabe erspart.
user> (defn zeige-historie []
(println [*1 *2 *3]))
#’user/zeige-historie
user> (+ 33 44)
77
user> (* 3 3)
9
user> (str "Jetzt kommt ein Karton!")
"Jetzt kommt ein Karton!"
user> (zeige-historie)
[Jetzt kommt ein Karton! 9 77]
nil
user> (zeige-historie)
[nil Jetzt kommt ein Karton! 9]
nil
user> (zeige-historie)
[nil nil Jetzt kommt ein Karton!]
nil
user> (zeige-historie)
[nil nil nil]
nil
In diesem Beispiel wird bewusst println verwendet, damit der Aufruf von zeige-historie
als Resultat nil liefert, das dann in den folgenden Schritten die Historie belagert.
Die Ausgabe der REPL birgt im Zusammenhang mit Sequences die Gefahr
der Verwirrung. Zunächst ist zu beachten, dass jede Lazy Sequence durch die Ausgabe
realisiert wird. Wenn dann der getippte Befehl unreflektiert in eine Quelltextdatei
übernommen wird, kann es unter Umständen dazu führen, dass das gesamte Programm in der
Ausführung nichts tut, weil ihm ein doall oder dorun fehlt, damit an der getesteten Stelle die
Elemente der Sequence auch wirklich erzeugt werden. Hinzu kommt, dass Sequences immer als
Listen ausgegeben werden.
user> (range 1 6)
(1 2 3 4 5)
user> (take 6 (iterate inc 0))
(0 1 2 3 4 5)
user> (type (range 1 6))
clojure.lang.LazySeq
Das ist für diese Beispiele noch nicht verwirrend. Sequences entstehen aber auch beim
Aufruf mancher Funktionen, beispielsweise auf einem Vektor, und dann können die
scheinbar fehlerhaften Klammern der Ausgabe der REPL durchaus zum Grübeln
führen.
user> (rest [3 4 5 6 7 8])
(4 5 6 7 8)
user> (filter #(> % 5) [3 4 5 6 7 8])
(6 7 8)
Der Rest eines Vektors ist eine Liste. Warum kein Vektor? Clojure sieht nach dem Aufruf
von rest nur noch eine Sequence, unabhängig davon, was zuvor vorgelegen hat, und
Sequences werden wie eine Liste ausgegeben.
Die Ausgabe von Clojure wird durch einige Variablen gesteuert. Für sehr
große Datenstrukturen kann die Variable *print-length* auf einen ganzzahligen Wert gesetzt
werden, um die komplette Ausgabe zu verhindern. Ist diese Variable hingegen logisch unwahr,
wird jede Datenstruktur komplett ausgegeben.
user> (def zahlen [1 1 2 3 5 8 13])
#’user/zahlen
user> (println zahlen)
[1 1 2 3 5 8 13]
nil
user> (binding [*print-length* 3]
(println zahlen))
[1 1 2 ...]
nil
Die Tiefe der Schachtelung, bis zu der eine Ausgabe erfolgen soll, kontrolliert in ähnlicher
Weise die Variable *print-level*:
user> (def schachteln
["Schachtel"
["Karton" "Kasten" "Kästchen"
["Truhe" "Schrank"]
"Kiste"]
"Box"])
#’user/schachteln
user> (println schachteln)
[Schachtel [Karton Kasten Kästchen [Truhe Schrank] Kiste]
Box]
nil
user> (binding [*print-level* 1]
(println schachteln))
[Schachtel # Box]
nil
user> (binding [*print-level* 2]
(println schachteln))
[Schachtel [Karton Kasten Kästchen # Kiste] Box]
nil
user> (binding [*print-level* 3]
(println schachteln))
[Schachtel [Karton Kasten Kästchen [Truhe Schrank] Kiste]
Box]
nil
Für die maschinenlesbare Ausgabe kontrolliert die Var *print-meta*, ob die Metadaten
ebenfalls ausgegeben werden sollen:
user> (def herta ^{:greta "Alpha Beta"}
["Peter" "The Greater"])
#’user/herta
user> (meta herta)
{:greta "Alpha Beta"}
user> (binding [*print-meta* true]
(prn herta))
^{:greta "Alpha Beta"} ["Peter" "The Greater"]
nil
;; aber:
user> (binding [*print-meta* true]
(println herta))
[Peter The Greater]
nil
Es existiert mit *print-dup* noch eine weitere Kontroll-Var, deren Verwendung jedoch sehr
selten ist. Sie steuert eine spezielle Form der Ausgabe von Datenstrukturen, die den Reader
bei späterer Wiedervorlage dazu veranlasst, Teile explizit zu evaluieren. In den meisten Fällen
ist der Einfluss dieser Variablen nicht sehr groß:
user> (def berta "See you spaeter, Alligator")
user> (prn berta)
"See you spaeter, Alligator"
user> (binding [*print-dup* true]
(prn berta))
"See you spaeter, Alligator"
nil
user> (def berta ["See you spaeter," "Alligator"])
#’user/berta
user> (binding [*print-dup* true]
(prn berta))
["See you spaeter," "Alligator"]
Bei Vars oder auch einer Kombination von Java-Klassen und Metadaten kann das Resultat
aber durchaus beeindrucken:
user> (binding [*print-dup* true]
(prn +))
#=(clojure.core$_PLUS_. )
nil
user> ;; herta von weiter oben...
nil
user> (binding [*print-dup* true]
(println herta))
^#=(clojure.lang.PersistentArrayMap/create
{:greta "Alpha Beta"}) ["Peter" "The Greater"]
nil
Die Verbindung von Reader und den verschiedenen Möglichkeiten zur Ausgabe, gepaart mit
der Read-Syntax für verschiedene Datentypen, erlaubt einfache und unkomplizierte Lösungen
für die Persistierung von Daten. Dabei wird eine Datenstruktur in eine Datei ausgegeben, aus
der sie später mit Hilfe des Readers wiederhergestellt werden kann. Als Beispiel definieren wir
eine rudimentäre Fotodatenbank.
user> (def foto-db
{:root "/home/foto/bilder"
:files ["img_0001.jpg"
"img_0002.jpg"]})
Eine reale Anwendung würde sicherlich deutlich mehr Informationen in dieser Struktur
vorhalten. Das Speichern erfolgt mit Hilfe von prn, für das die Ausgabe in eine Datei
umgeleitet wird.
(defn speicher-foto-db [db f]
(binding [*out* (java.io.FileWriter. f)]
(prn db)))
user> (speicher-foto-db foto-db "foto-daten.clj")
nil
Ein Ausflug auf die Shell zeigt, dass die Fotodaten den Weg in die Datei gefunden
haben.
shell> cat foto-daten.clj
{:root "/home/foto/bilder", :files ["img_0001.jpg"
"img_0002.jpg"]}
Diese Datei kann dann leicht wieder importiert werden, indem schlicht der Reader
beauftragt wird, den Inhalt zu lesen und als Ergebnis zu liefern. Auch diese Funktion erfüllt
nicht die Erwartungen an eine reale Anwendung, in der zumindest Exceptions aufgefangen
werden sollten.
(defn lese-foto-db [f]
(read (java.io.PushbackReader.
(java.io.FileReader.
(java.io.File. f)))))
user> (lese-foto-db "foto-daten.clj")
{:root "/home/foto/bilder",
:files ["img_0001.jpg" "img_0002.jpg"]}
Dass diese Art, Daten abzulegen, nicht nur für kleine Spielereien taugt, sondern auch
mit größeren Datenmengen verwendet werden kann, zeigt das folgende Beispiel,
das 10 000 Einträge in den Vektor legt und die Zeiten zum Schreiben und Lesen
ermittelt.
user> (time
(speicher-foto-db
{:root "/home/foto/bilder"
:files (vec (repeat 10000 "img.jpg"))}
"test-fotos.clj"))
"Elapsed time: 295.783 msecs"
nil
user> (time
(do ;; zum Unterdruecken des Resultats
(lese-foto-db "test-fotos.clj")
nil))
"Elapsed time: 88.126 msecs"
nil
Mit einer letzten Ausgabe an der REPL beenden wir die Einführung der Sprache
Clojure:
user> "Tschuess"
"Tschuess"
user> (System/exit 0)
shell>